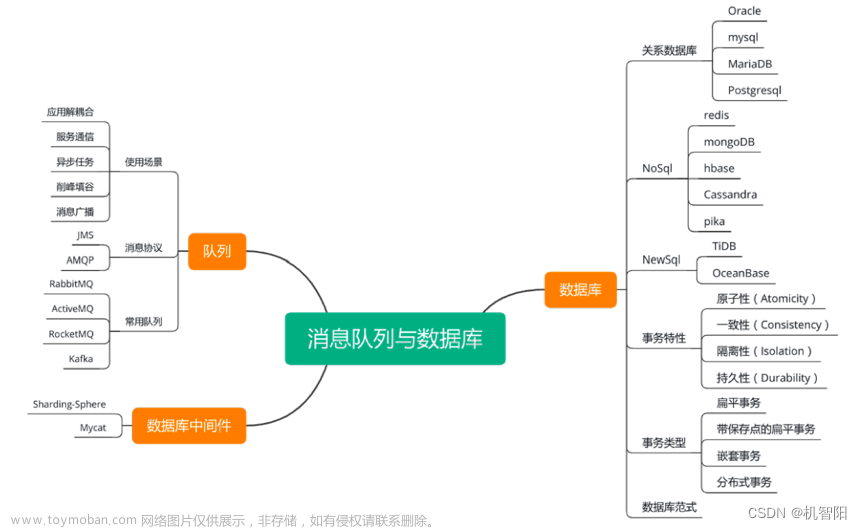
N.1 Kafka是什么
| 1)Kafka是开源消息系统 2)最初由 LinkedIn 公司开发,2011年开源,2012年10月从 Apache 毕业。 项目目标是:为处理实时数据,提供一个统一、高通量、低等待的平台。 3)Kafka是一个分布式消息队列。 Kafka对消息根据 Topic 进行归类。发送消息 Producer,接收消息 Consumer kafka集群中有多个kafka实例,每个实例都是一个 broker。 4)无论是kafka集群,还是 producer consumer 都依赖于 zookeeper 保存元信息,来保证系统的可用性。 |
N.2 消息队列内部实现原理
| 1)点对点: 点对点模型通常是一个基于拉取或者轮询的消息传送模型,这种模型从队列中请求信息,而不是将消息推送到客户端。这个模型的特点是发送到队列的消息被一个且只有一个接收者接收处理,即使有多个消息监听者也是如此。 2)发布/订阅模式: 发布订阅模型则是一个基于推送的消息传送模型。发布订阅模型可以有多种不同的订阅者,临时订阅者只在主动监听主题时才接收消息,而持久订阅者则监听主题的所有消息,即使当前订阅者不可用,处于离线状态。 |
N.3 为什么要用消息队列
| 1)解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。 这样两个程序组件就没有依赖性了 2)冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。许多消息队列所采用的"插入-获取-删除"范式中,在把一个消息从队列中删除之前,需要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你使用完毕。 3)扩展性: 因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,只要另外增加处理过程即可。 4)灵活性 & 峰值处理能力: 在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。 5)可恢复性: 系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。 6)顺序保证: 在大多使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。(Kafka保证一个Partition内的消息的有序性) 7)缓冲: 有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。 8)异步通信: 很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。 |
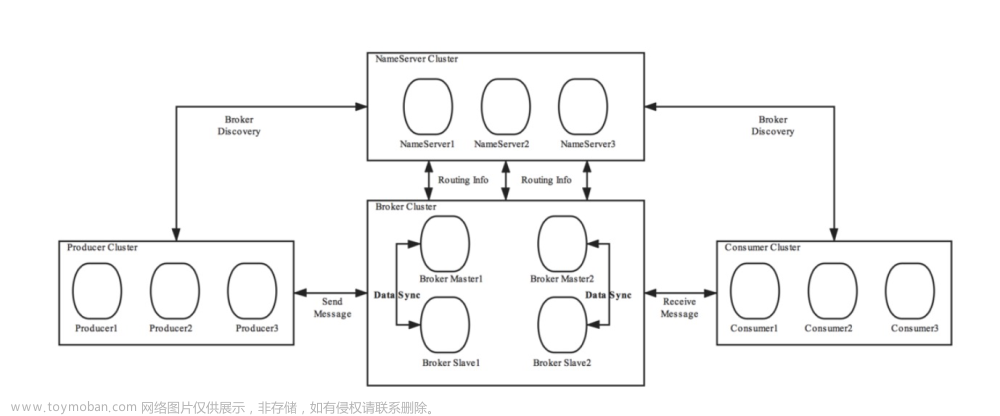
N.4 Kafka架构
————————————————————————

————————————————————————
| 0)partition分区可以设置备份数,也可以设置被几个消费组消费,如上 分区0是设置了两个被匹配消费者组消费 1)Producer :消息生产者,就是向kafka broker发消息的客户端。 2)Consumer :消息消费者,向kafka broker取 消息的客户端 3)Topic :可以理解为一个队列。 4) Consumer Group (CG):kafka提供的可扩展且具有容错性的消费者机制。既然是一个组,那么组内必然可以有多个消费者或消费者实例(consumer instance),它们共享一个公共的ID,即group ID。组内的所有消费者协调在一起来消费订阅主题(subscribed topics)的所有分区(partition)。当然,每个分区只能由同一个消费组内的一个consumer来消费。 5)Broker :一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。 6)Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的“每一条消息”都会被分配一个有序的id 即offset偏移量,有小到大编号。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序。 7)Offset(即id):kafka的存储文件的每个分区的偏移量都从0开始,不同分区之间的偏移量都是独立的,不会相互影响。 |
————————————————————————

————————————————————————
| 8)segment分段: (1)每一个分区都是多个分段构成,每个LogSegment分段,包括了'一个'数据文件和'一个'索引文件, 它们的文件名都是以某一个连续范围的区间ofset进行命名,且文件名是以最小的ofset进行命名。为了进一步提高查找的效率,Kafka为每个分段后的数据文件建立了索引文件,文件名与数据文件的名字是一样的,只是文件扩展名为.index。 (2)data file是.log后缀。index file是.index后缀。 (3)data file和index file文件命名规则:partion全局的第一个data file和index file从0开始,后续每个data file和index file文件名为上一个data file和index file最后一条消息的offset值。文件名是左开右闭的。而里面的数据保持一致顺序的 |
————————————————————————

————————————————————————

————————————————————————
| 9)下面的结论可能抽象,请结合后面的例子理解。 (1).index文件 [1] 相对offset(也可能为行号):索引包含两个部分(均为4个字节的数字),分别为行号和position。每个数据文件的起始不为0。index文件并不是每一条数据都有索引,这是稀疏索引,只有一部分有,如果全部都有,那内存就吃不消。 [2] position位置:是对应的log文件位置(也可以理解为行号) (2).log文件构成 [1] Message: Message在“kafka数据文件”中的绝对路径位置。 [2] position位置构成。是对应log文件的位置 其中每一个log文件的大小默认是1GB. (3).index文件构成 和 .log文件两个文件主要是通过position这个字段关联对应的, index文件依赖于log文件。 10)例如读取offset=368776的message,需要通过下面2个步骤查找。 (1)通过二分法查找segment file文件 第一个文件00000000000000000000.index表示最开始的文件,起始偏移量(offset)为0(由于这个文件是第一个,前面没有文件,所以文件名为零)。 第二个文件00000000000000368769.index的消息量起始偏移量为368770 = 368769 + 1。 第三个文件00000000000000737337.index的起始偏移量为737338=737337 + 1,其他后续文件依次类推。 以起始偏移量命名并排序这些文件,只要根据offset 二分查找文件,就可以快速定位到具体segment(即.index/log)文件。 当offset=368776时定位到00000000000000368769.index 。 因为我们通过过二分法查找,找出offset=368776 > 文件名编号(注意,不可以等于),且是最近的编号。 如果找的offset=368769,那么就找368776 > 文件名编号,因为文件名是左开右闭的。 (2)通过segment file查找message 通过第一步定位到segment file,当offset=368776时,依次定位到00000000000000368769.index的元数据物理位置和00000000000000368769.log的物理偏移地址,然后再通过00000000000000368769.log顺序查找直到offset=368776为止。 |
————————————————————————

————————————————————————
| 11)每个ConsumerGroup消费组 只能对同一个分区最多消费一次 而同一个分区可以被不同组消费; 疑问: 为什么一个分区可以被不同的组消费,有什么好处?文章来源:https://www.toymoban.com/news/detail-721111.html 如果A部门和B部门 都需要这些数据,这时就需要共享这些数据 给两个部门都消费,这就是分多组的好处。文章来源地址https://www.toymoban.com/news/detail-721111.html |
到了这里,关于Kafka架构原理(超级详细)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!