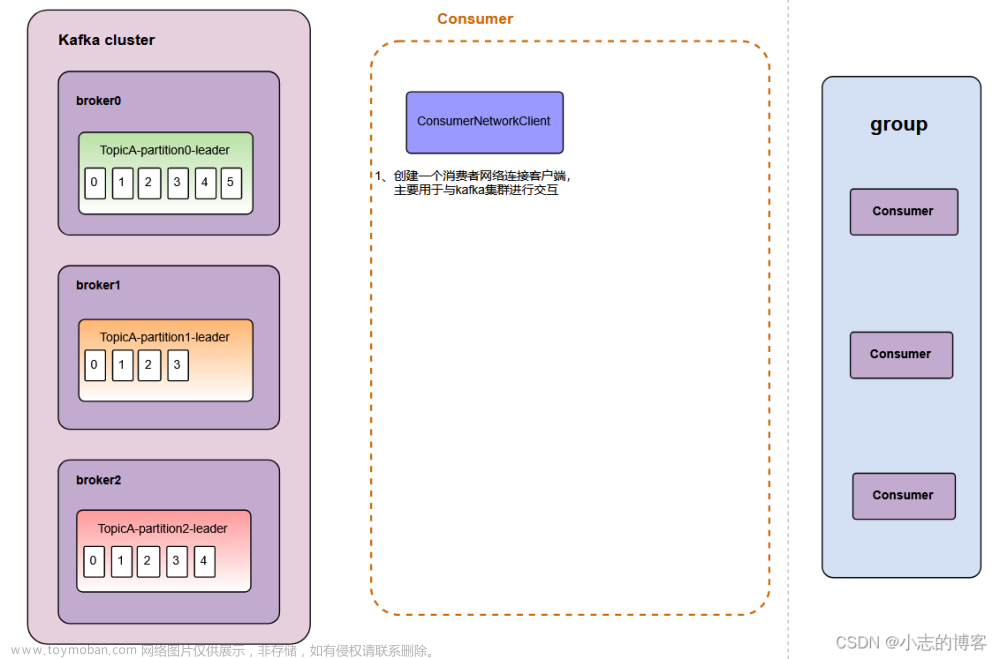
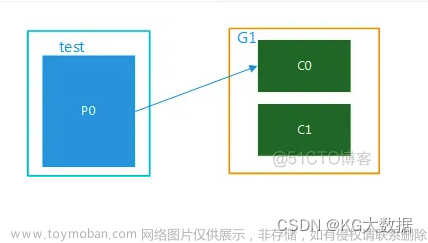
首先说一下结论,这个参数用来增加消费者实例,或者可以理解为@KafkaListener注解实例的数量。当消费者服务数量小于topic的分区数的时候使用此参数可以提升消费能力,spring-kafka在初始化的时候会启动concurrency个Consumer线程来执行@KafkaListener里面的方法。
Consumer线程
用来直接调用kafka-client的poll()方法获取消息。如果是自动提交offset,poll()方法获取消息后会直接给到listener线程执行。
Listener线程
真正调用处理我们代码中标有@KafkaListener注解方法的线程。具体实现在KafkaMessageListenerContainer 类中。文章来源:https://www.toymoban.com/news/detail-721266.html
KafkaMessageListenerContainer
protected void pollAndInvoke() {
if (!this.autoCommit && !this.isRecordAck) {
processCommits();
}
processSeeks();
checkPaused();
ConsumerRecords<K, V> records = this.consumer.poll(this.pollTimeout);
this.lastPoll = System.currentTimeMillis();
checkResumed();
debugRecords(records);
if (records != null && records.count() > 0) {
if (this.containerProperties.getIdleEventInterval() != null) {
this.lastReceive = System.currentTimeMillis();
}
// 这里可以看到如果是自动提交offset,会直接把consumer poll下来的消息给到listener执行,
// 即kafka consumer所在线程会直接调用我们的@KafkaListener方法
invokeListener(records);
}
else {
checkIdle();
}
}
如果是手动提交offset,即enable-auto-commit设置为false,则是将消息投放到阻塞队列中,另一边由Listener线程取出执行。ConcurrentMessageListenerContainer
当使用了concurrency参数是,在consumer启动过程会通过这个类去初始化。其实就是根据concurrency的值for循环调用KafkaMessageListenerContainer的dostart方法创建实例文章来源地址https://www.toymoban.com/news/detail-721266.html
到了这里,关于Kafka消费端concurrency参数的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!