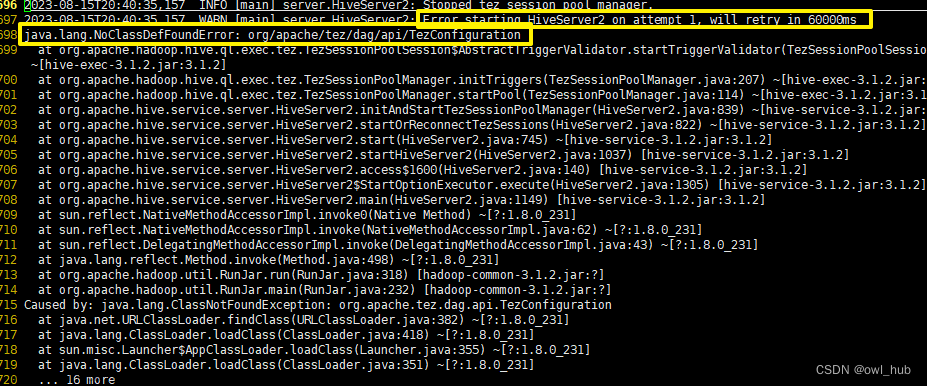
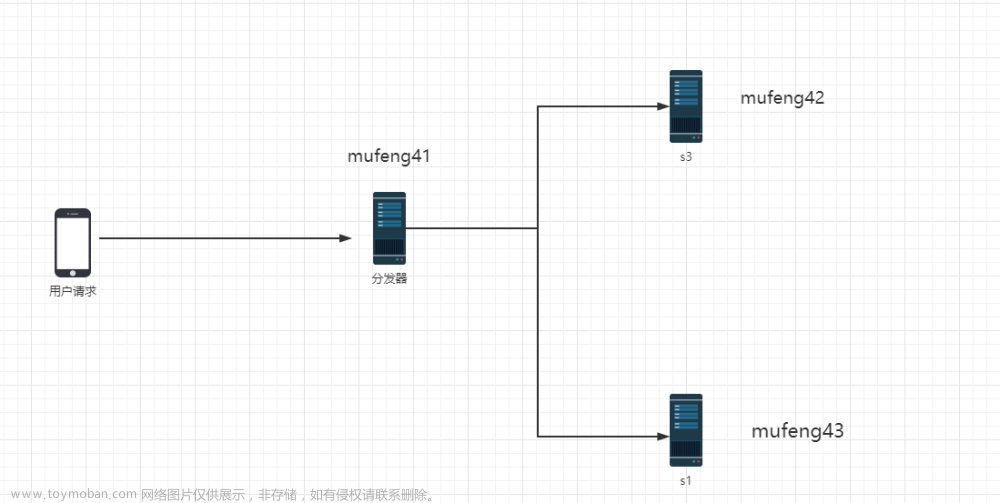
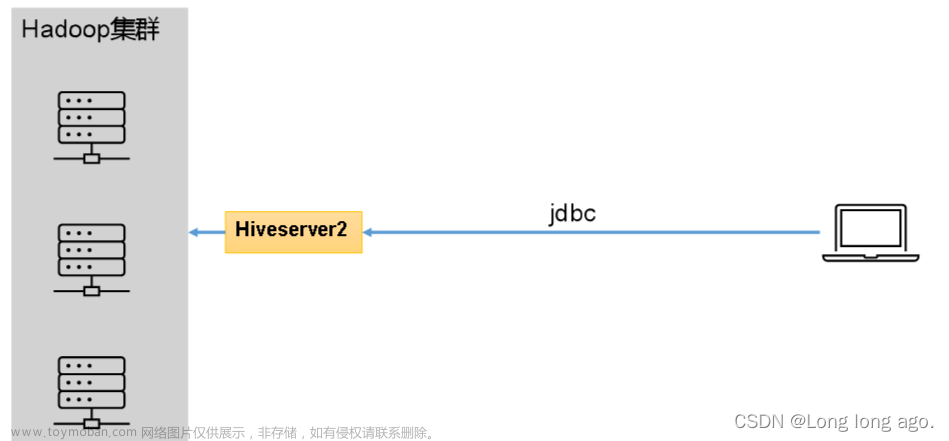
如果你使用的是CDH集群那就很是方便的
-
在Cloudera Manager中,进入HDFS Service
-
进入Instances标签页面,点击Add Role Instances按钮,如下图所示
-

-
点击Continue按钮,如下图所示
-

-
返回Instances页面,选择HttpFS角色,并点击Start启动服务,如下图所示

-
HttpFS服务启动后,点击进入Hue Service > Configuration页面,如下图所示
-
找到Service-Wide > HDFS Web Interface Role属性,选中httpfs单选框,如下图所示
-
点击Save Changes按钮保存修改并重启Hue服务文章来源:https://www.toymoban.com/news/detail-721393.html
如果使用的是其他的模式:
集群未打开Kerberos身份认证开关的集群
Hue连接该负载均衡HiveServer2,需要在Hue配置的hue页签中添加如下三个自定义参数。
参数 描述
zookeeper.clusters.default.hostports Zookeeper的连接地址,请根据实际情况填写,本示例为master-1-1:2181,master-1-2:2181,master-1-3:2181。
beeswax.hive_discovery_hs2 固定值为true。
beeswax.hive_discovery_hiveserver2_znode 固定值为/hiveserver2。文章来源地址https://www.toymoban.com/news/detail-721393.html
到了这里,关于hue实现对hiveserver2 的负载均衡的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!