1,项目地址
https://github.com/li-plus/chatglm.cpp.git
这个项目和llama.cpp 项目类似,使用C++ 去运行模型的。
项目使用了 ggml 这个核心模块,去运行的。
可以支持在 cpu 上面跑模型。
ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性:
更强大的性能: 基于 ChatGLM 初代模型的开发经验,我们全面升级了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 GLM 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,评测结果显示,相比于初代模型,ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
更长的上下文: 基于 FlashAttention 技术,我们将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。但当前版本的 ChatGLM2-6B 对单轮超长文档的理解能力有限,我们会在后续迭代升级中着重进行优化。
更高效的推理: 基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
2,准备环境,使用python的docker进行安装
下载代码:
git clone --recursive https://github.com/li-plus/chatglm.cpp.git
要是超时可以分开下载:
git clone https://github.com/li-plus/chatglm.cpp.git
cd chatglm.cpp/third_party
git clone https://github.com/ggerganov/ggml.git
git clone https://github.com/pybind/pybind11.git
git clone https://github.com/google/sentencepiece.git
要是网络不好可以这样下载,速度也快:
git clone https://ghproxy.com/https://github.com/li-plus/chatglm.cpp.git
cd chatglm.cpp/third_party
git clone https://ghproxy.com/https://github.com/ggerganov/ggml.git
git clone https://ghproxy.com/https://github.com/pybind/pybind11.git
git clone https://ghproxy.com/https://github.com/google/sentencepiece.git
然后运行docker 并配置python 的源:
docker run -itd --name python -p 8000:8000 -p 7860:7860 -v `pwd`/chatglm.cpp:/data python:slim-bullseye
docker exec -it python bash
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
pip config set install.trusted-host mirrors.aliyun.com/pypi/simple/
echo "deb https://mirrors.aliyun.com/debian/ bullseye main contrib non-free" > /etc/apt/sources.list && \
echo "deb https://mirrors.aliyun.com/debian/ bullseye-updates main contrib non-free" >> /etc/apt/sources.list && \
echo "deb https://mirrors.aliyun.com/debian/ bullseye-backports main contrib non-free" >> /etc/apt/sources.list && \
echo "deb https://mirrors.aliyun.com/debian-security/ bullseye-security main" >> /etc/apt/sources.list
3,安装依赖包,使用特殊命令安装pytorch的cpu版本
只安装 cpu 版本的 pytorch ,可以减少镜像大小。
特别注意pytorch2.0 只支持 3.10 的最低版本,其他版本安装不上。
apt-get update && apt-get -y install g++ cmake
# 只是安装 cpu 的版本:
pip3 install torch==2.0.1+cpu torchvision==0.15.2+cpu torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cpu
pip3 install uvicorn fastapi==0.92.0 sse_starlette chatglm-cpp tabulate tqdm gradio transformers==4.30.2
4,进行模型转换,把chatglm2-6b模型转换下
需要下载模型,安装git-lfs 把模型下载即可
cd /data
apt-get install git-lfs
# 下载模型
git clone https://huggingface.co/THUDM/chatglm2-6b-int4
# 然后就可以转换模型了,chatglm2-6b-int4 是下载的模型文件夹
python3 convert.py -i chatglm2-6b-int4 -t q4_0 -o chatglm2-ggml.bin
# 稍等下,如果没有报错信息,说明转换成功。会有个 chatglm2-ggml.bin 文件
3.3G chatglm-ggml.bin # 说明转换成了。
ChatGLM2-6B,各种尺寸的模型,需要消耗的资源:
| Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 | F16 | F32 | |
|---|---|---|---|---|---|---|---|
| ms/token (CPU @ Platinum 8260) | 64 | 71 | 79 | 83 | 106 | 189 | 372 |
| ms/token (CUDA @ V100 SXM2) | 9.7 | 9.4 | 10.3 | 10.2 | 14.0 | 19.1 | 33.0 |
| ms/token (MPS @ M2 Ultra) | 11.0 | 11.7 | N/A | N/A | N/A | 32.1 | N/A |
| file size | 3.3GB | 3.7GB | 4.0GB | 4.4GB | 6.2GB | 12GB | 24GB |
| mem usage | 3.4GB | 3.8GB | 4.1GB | 4.5GB | 6.2GB | 12GB | 23GB |
5,启动web demo 界面,启动api 接口
需要修改下 web_demo.py 的最后一行:
因为是docker 做端口映射,需要把 IP 修改成 0.0.0.0 本机就可以访问了。
demo.queue().launch(share=False, inbrowser=True,server_name="0.0.0.0", server_port=7860)
cd /data/examples
python3 web_demo.py
Running on local URL: http://0.0.0.0:7860
To create a public link, set `share=True` in `launch()`.

如果没有报错,说明启动成功了,端口是7860 ,直接通过web访问即可。
启动 api 接口:
python3 api_demo.py
INFO: Started server process [5843]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
执行命令测试接口,和chatgpt 的接口是一样的。
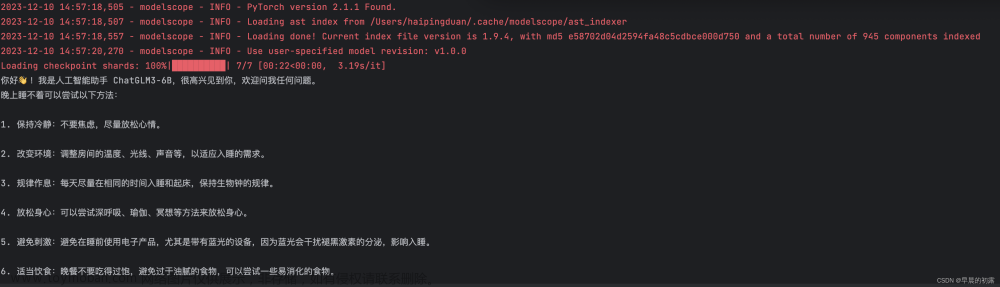
curl http://127.0.0.1:8000/v1/completions -H 'Content-Type: application/json' -d '{"prompt": "你好"}'
{
"object":"text_completion",
"response":"你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。",
"model":"chatglm2-6b",
"choices":[
{
"text":"你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。",
"index":0,
"finish_reason":"stop"
}
],
"usage":{
}
}
6,使用docker 把镜像的运行打包,在CPU下运行环境搭建
dockerfile
# 构建 python
# FROM python:slim-bullseye 使用最新的slim 版本。
# docker build . -t chatglm.cpp:latest
FROM python:slim-bullseye as builder
RUN echo "deb https://mirrors.aliyun.com/debian/ bullseye main contrib non-free" > /etc/apt/sources.list && \
echo "deb https://mirrors.aliyun.com/debian/ bullseye-updates main contrib non-free" >> /etc/apt/sources.list && \
echo "deb https://mirrors.aliyun.com/debian/ bullseye-backports main contrib non-free" >> /etc/apt/sources.list && \
echo "deb https://mirrors.aliyun.com/debian-security/ bullseye-security main" >> /etc/apt/sources.list && \
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/ && \
pip config set install.trusted-host mirrors.aliyun.com/pypi/simple/
RUN apt-get update && apt-get -y install g++ cmake && \
pip3 install torch==2.0.1+cpu torchvision==0.15.2+cpu torchaudio==2.0.2 \
--index-url https://download.pytorch.org/whl/cpu && \
pip3 install uvicorn fastapi==0.92.0 sse_starlette chatglm-cpp tabulate tqdm gradio transformers==4.30.2
# 拷贝本地文件到目录
COPY . /data
# service
FROM python:slim-bullseye
# 直接使用基础镜像然后拷贝 site-packages 安装包即可。
COPY --from=builder /data/examples /data/examples
COPY --from=builder /usr/local/lib/python3.11/site-packages /usr/local/lib/python3.11/site-packages
WORKDIR /data
# 设置python 的环境变量和 fask app文件。
ENV LC_ALL="C.UTF-8" LANG="C.UTF-8"
ENV PYTHONPATH="/data"
EXPOSE 8000 7860
ENTRYPOINT ["/data/examples/docker-entrypoint.sh"]
CMD ["/bin/sh"]
其中启动脚本 docker-entrypoint.sh 是:
#!/bin/sh
ls -lh
echo "############# start python3 web_demo.py #############"
cd /data/examples
python3 web_demo.py
sleep 99999d
执行打包命令:
docker build . -t chatglm.cpp:latest
然后就可以启动了,必须注意不能挂载当前的源代码文件夹了,否则会报错:
ModuleNotFoundError: No module named ‘chatglm_cpp._C’
https://github.com/li-plus/chatglm.cpp/issues/91
尝试下cd到别的路径下运行,在chatglm.cpp目录下执行,包名会跟仓库里的chatglm_cpp文件夹冲突
这样启动就可以了:
docker run -itd --name chatglm -p 8000:8000 -p 7860:7860 -v `pwd`/chatglm.cpp/chatglm-ggml.bin:/data/chatglm-ggml.bin chatglm.cpp:latest
然后就可以访问web 界面了。文章来源:https://www.toymoban.com/news/detail-721470.html
7,总结
也可以支持英文,但是最后几个字有点问题。最后有点乱码,不知道是不是因为模型裁剪的问题。
同时也有可能是原始素材就有这个问题。
可以使用docker 在 CPU上面运行 chatglm ,同时安装了 pytorch 的CPU 版本,镜像缩小到 1.5 G了。
并且速度也是非常的快了。可以在非GPU的机器上面运行了。可以解决很多问题呢。文章来源地址https://www.toymoban.com/news/detail-721470.html
到了这里,关于【chatglm2】使用Python在CPU环境中运行 chatglm.cpp 可以实现本地使用CPU运行chatglm2模型,速度也特别的快可以本地部署,把现有项目进行AI的改造。的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!