作者:禅与计算机程序设计艺术
1.简介
推荐系统(Recommendation System)一直都是互联网领域一个非常火热的话题。其主要目标是在用户多样化的信息环境中,通过分析用户的偏好、消费习惯等数据,提供个性化的信息推送、商品推荐、购物指导等服务。如何设计一个推荐系统的架构及其高可用、可扩展性是推荐系统从诞生到现在面临的一系列问题之一。本文将结合实际工程经验,对推荐系统的架构进行设计,从而实现实时的服务。文章来源:https://www.toymoban.com/news/detail-721816.html
1.1 为什么需要实时推荐系统?
推荐系统是一个高度实时和复杂的应用场景。随着互联网业务的不断发展,传统的基于离线的推荐系统已经不能满足互联网产品的快速响应速度要求,越来越多的公司希望能够在很短的时间内给用户反馈即时的推荐结果。因此,实时的推荐系统的需求日益凸显。它能够提供以下优点:文章来源地址https://www.toymoban.com/news/detail-721816.html
- 提升用户体验:实时的推荐系统能够提升用户的满意度和黏性,改善用户的使用体验,使得产品服务更加贴近用户的真正需求。
- 改善服务质量:实时的推荐系统可以帮助企业识别并消除系统故障,保证推荐效果的及时性和准确性,进而提升公司的竞争力。
- 更有效地提高效益:由于实时的推荐系统能够实时地向用户提供个性化的推荐结果,所以它能够帮助企业更快、更精准地收集用户信息,使得公司能够更加有效地运用资源,提高效益。
1.2 本文方案架构概览
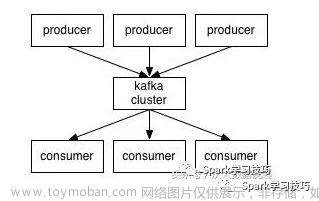
本文的实时推荐系统架构由三个模块组成,分别为: - 数据采集模块:负责获取用户行为数据、流量日志等原始数据。采用实时流式处理框架Spark Streaming。
- 流程模块:负责按照一定规则过滤、清洗、转换原始数据,
到了这里,关于推荐系统架构设计实践:Spark Streaming+Kafka构建实时推荐系统架构的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!