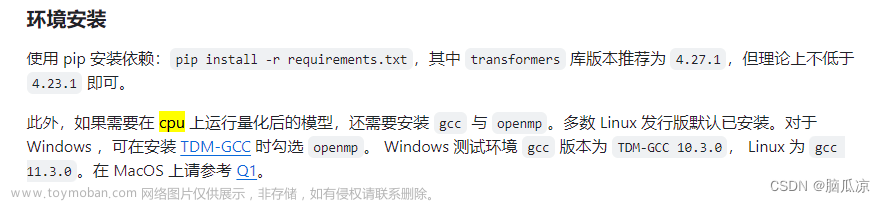
“token”是当前语言类模型的数据单位。当前的自回归语言模型是根据 token 来作为单位进行数据处理和计算,分词(tokenization)就是将句子、段落、文章这类型的长文本分解为以 token 为单位的数据结构,把文本分词后每个词表示成向量进行模型计算。例如在英文语境下,“happy”可能被分解为“hap”、“-py”两个 token,中文语境下,“我很开心”可以分成“我”,“很”,“开心”三个 token。
转载:ChatGPT算力计算更正——更准确的参数和计算方法
在与GPT-3参数相当的开源LLM——1760亿参数的BLOOM上,4张墨芯S30计算卡在仅采用中低倍稀疏率的情况下,就能实现25 tokens/s的内容生成速度,超过8张A100。

转载: MLPref放榜!大模型时代算力领域“潜力股”浮出水面:梅开二度拿下世界第一,今年获双料冠军文章来源:https://www.toymoban.com/news/detail-721830.html
ps: tokens/s表征了大模型内容生成速度。文章来源地址https://www.toymoban.com/news/detail-721830.html
到了这里,关于人工智能大模型中token的理解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!