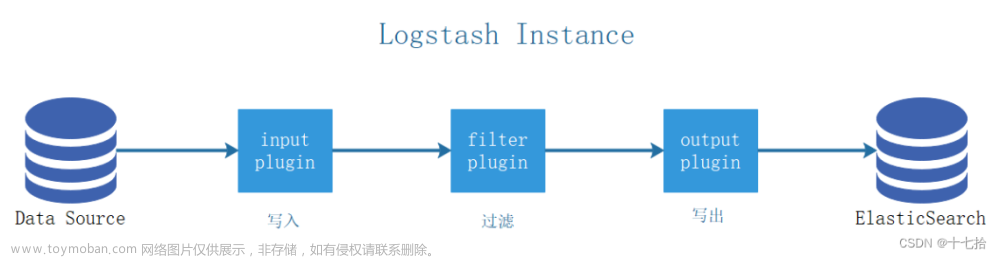
一、简介
1. 定义及特点
Elasticsearch 是一个开源的分布式全文搜索引擎,能够处理大型数据集合并且能够实时查询。其具有以下几个主要特点:
- 分布式架构:可以将数据分布在多台服务器上进行处理和存储,提高了系统的可靠性和扩展性。
- 全文搜索:能够对文本内容进行全面、实时的搜索与分析,支持复杂的语法查询。
- 多种数据类型支持:支持结构化数据、非结构化数据和地理空间数据等多种数据类型。
- 实时性强:可以快速、实时地对大量数据进行索引和查询,并且支持集群监控和诊断工具。
2. 基本功能
Elasticsearch 模块化设计,包括以下组件:
- Elasticsearch 节点
- Lucene 核心库,用于实现文本搜索
- 网络通信协议
- 与其他应用程序交互的 RESTful API
Elasticsearch 中的基本概念包括:
- Index(索引):类似于关系型数据库中的表格,用于存放一类具有相同属性的文档。
- Document(文档):可以理解为一行数据。
- Field(字段):文档中每个属性都是一个字段。
- Type(类型):Elasticsearch 7.0 版本后弃用。
3. 数据索引与查询
Elasticsearch 对文档进行索引和查询,需要经过以下几个步骤:
- 创建 Index(索引)
// 创建 index 对象
IndexRequest request = new IndexRequest("index_name");
// 向 Index 中添加文档数据
Map<String, Object> jsonMap = new HashMap<>();
jsonMap.put("content", "这是一个示例");
request.source(jsonMap, XContentType.JSON);
// 执行添加操作
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
- 查询 Index(索引)内数据
// 构建搜索参数
SearchRequest searchRequest = new SearchRequest("index_name");
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("content","示例");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(matchQueryBuilder);
// 执行查询操作
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
// 打印结果
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());
}
二、Kibana 简介
1. 定义及特点
Kibana 是一个开源的数据分析和可视化平台,允许用户对 Elasticsearch 中的数据进行复杂的查询和分析,以生成动态和交互式的可视化图表。Kibana 是一个非常强大的工具,适用于许多不同的应用程序场景,例如日志分析、运营商数据分析、安全分析、网站性能监测等。
Kibana 的特点包括:
- 易于使用:Kibana 提供了一个直观的用户界面,允许用户在几分钟内完成配置和使用。
- 实时查询:Kibana 允许用户实时地查询 Elasticsearch 中的数据,并且可以在数据变动时自动更新可视化和查询结果。
- 可视化和交互性:Kibana 支持多种视觉化图表类型,并允许用户通过图表和控制面板进行交互和过滤。
2. 基本功能与架构
Kibana 的基本功能包括:
- 数据分析:Kibana 允许用户在 Elasticsearch 中执行各种分析操作,如聚合、过滤、查询和统计。
- 可视化:Kibana 支持将 Elasticsearch 中的数据可视化为多种图表类型,如条形图、饼图、地图等。
- 搜索和发现:Kibana 允许用户使用强大的搜索功能查找 Elasticsearch 中的数据,还可以使用发现面板浏览数据。
- 实时监控:Kibana 可以实时监控 Elasticsearch 簇和索引的状态,以便及时发现问题和做出响应。
Kibana 的架构包括:
- 前端:Kibana 的前端界面是一个基于浏览器的单页面应用程序,使用 AngularJS、jQuery 和 D3.js 等前端技术实现。
- 后端:Kibana 通过 Elasticsearch 的 RESTful API 查询和获取数据,并使用 Node.js 和 Express 框架提供 Web 服务和路由。Kibana 还使用了多个 Node.js 模块,如 bluebird、request、lodash 等进行功能扩展。
- 数据存储:Kibana 并不直接存储数据,而是从 Elasticsearch 查询数据并将其可视化。
3. Kibana 可视化交互性
Kibana 实现可视化和交互性的核心在于其图表和控制面板组件。Kibana 提供了多种类型的图表,每种图表又可以配置多种可视化属性和样式。例如柱状图、饼图和地图都可以按照颜色、大小、标签等属性对数据进行分类和呈现。
在 Kibana 中控制面板是一组可定制的控件,用于交互式过滤数据、对图表进行选择和分组等操作。用户可以根据需要自由拖放控制面板,将其配置为自己需要的布局和风格,从而实现数据可视化和分析的互动性和灵活性。
下面是一个 Java 示例代码,用于演示如何使用 Kibana API 查询数据并实现可视化:
import com.fasterxml.jackson.databind.JsonNode;
import org.apache.http.HttpHost;
import org.elasticsearch.client.Request;
import org.elasticsearch.client.Response;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import java.io.IOException;
public class KibanaExample {
public static void main(String[] args) {
// create an Elasticsearch client
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http")));
// build a Kibana request
Request request = new Request("POST", "/_kibana/sql/sql_query");
request.setJsonEntity("{ \"query\": \"SELECT COUNT(*) FROM my_index\"}");
try {
// execute the request and get the response
Response response = client.getLowLevelClient().performRequest(request);
// parse the response object as JSON and extract the data field
JsonNode rootNode = objectMapper.readTree(response.getEntity().getContent());
int count = rootNode.path("rows").path(0).path(0).asInt();
// print the result
System.out.println("Number of documents in my_index: " + count);
} catch (IOException e) {
e.printStackTrace();
}
}
}
三、Elasticsearch 和 Kibana 的集成
1. 集成意义
Elasticsearch 是一个流行的搜索引擎和分布式数据存储解决方案。它支持实时地对大量数据进行搜索和分析,并提供了可扩展性和高可用性。Kibana 则是 Elasticsearch 的可视化工具,可以将 Elasticsearch 中的数据进行可视化展示。
将 Elasticsearch 和 Kibana 进行集成可以更好地掌握数据,及时发现问题并快速解决。在日志分析、监测数据、业务指标等方面都有广泛应用。
2. 集成方法
2.1 安装 Elasticsearch
首先需要安装 Elasticsearch,官网提供了详细的安装教程
2.2 安装 Kibana
完成 Elasticsearch 的安装后,需要再次进入官网安装 Kibana可以在安装页面找到步骤和方法
2.3 配置 Elasticsearch
修改 Elasticsearch 的配置文件 elasticsearch.yml,让其监听公网 IP 地址或者能够被访问到的网络地址。
2.4 启动 Elasticsearch 和 Kibana
在完成了 Elasticsearch 和 Kibana 的安装和配置之后,使用以下命令启动 Elasticsearch 和 Kibana:
# 启动 Elasticsearch
bin/elasticsearch
# 启动 Kibana
bin/kibana
3. 集成后的特性和使用方法
3.1 可视化展示
通过 Kibana 可以将 Elasticsearch 中的数据进行可视化展示,包括多种图表类型和仪表盘。用户可以根据具体需求自定义展示效果,并可以方便地导出报表。
3.2 实时监控
Elasticsearch 和 Kibana 集成后,可以实现对日志、监测数据等实时进行监控。这使得用户可以及时发现并定位问题,快速解决故障,提高应用的可用性和性能。
3.3 快速搜索和分析
Elasticsearch 支持全文搜索和结构化查询,将 Elasticsearch 和 Kibana 进行集成后,用户可以更加方便地进行搜索和分析,有效提高工作效率。
Java 代码展示 如何通过 Elasticsearch Java API 进行搜索:
// 创建 TransportClient 对象
TransportClient client = new TransportClient()
.addTransportAddress(new InetSocketTransportAddress("localhost", 9300));
// 设置要搜索的索引和类型
SearchRequestBuilder requestBuilder = client.prepareSearch("index-name")
.setTypes("type-name");
// 构造查询
QueryBuilder queryBuilder = QueryBuilders.matchQuery("field-name", "query-string");
requestBuilder.setQuery(queryBuilder);
// 执行搜索
SearchResponse response = requestBuilder.execute().actionGet();
注:需要导入 Elasticsearch Java API 的相关依赖包。
四、实时大数据分析系统案例分析
1. 实时大数据分析系统的应用场景
实时大数据分析系统可以应用于各种场景,如电商网站的用户行为分析、智能交通的车辆轨迹识别、金融行业的风险控制等。在这些场景下,实时大数据分析系统可以帮助企业实时了解商业趋势和客户需求,及时发现异常数据和问题,快速调整和决策。
2. 实时大数据分析系统的工作流程
实时大数据分析系统一般包括数据采集、数据处理、数据存储和分析展示四个环节。其中,数据采集阶段负责从各种数据源收集数据,包括结构化数据和半结构化数据;数据处理阶段对采集到的数据进行清洗、转换和聚合,以便后续分析使用;数据存储阶段用于存储清洗后的数据,通常会采用分布式数据库或文件系统;分析展示阶段则负责根据业务需求构建可视化的报表和图表,帮助企业更好地理解和利用数据。
3. 通过案例对实时大数据分析系统的具体应用进行说明
这里以一个电商网站的用户行为分析为例,具体工作流程如下:
3.1 数据采集
对于电商网站的用户行为分析,数据采集阶段需要从多种渠道获取数据,包括网站访问日志、用户购买记录、用户评价等。可以使用流行的开源数据采集工具如Flume、Logstash等。
3.2 数据处理
在数据采集后,需要进行数据处理才能得到更好的结果。数据处理可以涵盖以下方面内容:
- 数据清洗:对于不合法、重复、错误等数据进行过滤和修复。
- 数据转换:将数据从原始格式转换为可用格式,如将时间戳转换为日期格式等。
- 数据聚合:将多个数据源的数据进行组合,并按照业务逻辑进行聚合和统计分析,以便后续展示和使用。
在本例中通过Elasticsearch进行聚合和统计分析。Elasticsearch是一个分布式、可扩展、实时的搜索和分析引擎,支持海量数据的存储和查询。同时它也支持各种聚合操作,如sum、count、avg等,可以很轻松地实现各种数据分析需求。
Java代码示例:文章来源:https://www.toymoban.com/news/detail-721993.html
// 创建elasticsearch客户端
TransportClient client = new PreBuiltTransportClient(Settings.EMPTY)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("localhost"), 9300));
// 聚合统计IP地址的访问次数
SearchResponse sr = client.prepareSearch("logstash-*") // 设置查询的索引名称
.setTypes("type") // 设置查询的类型
.setQuery(QueryBuilders.termQuery("message", "192.168.1.1")) // 设置查询条件,这里以IP地址为例
.addAggregation(AggregationBuilders.count("count").field("clientip.keyword")) // 设置聚合操作,这里以访问次数为例
.get();
// 输出聚合结果
Count count = sr.getAggregations().get("count");
System.out.println("IP地址为192.168.1.1的访问次数为:" + count.getValue());
3.3 数据存储
在进行了数据处理之后,需要将处理过的数据存储到数据库或文件系统中。对于海量的数据,可以考虑使用分布式数据库如Hadoop、Cassandra等。
3.4 分析展示
最后需要将处理过的数据通过前端技术可视化展示出来,方便业务人员进行理解和决策。其中,Kibana是一个优秀的数据可视化工具,可以方便地从Elasticsearch中获取数据并构建各种图表和报表。
Java代码示例:
// 创建kibana客户端
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http")));
// 构建聚合查询请求
SearchRequest searchRequest = new SearchRequest("logstash-*");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
searchSourceBuilder.aggregation(
AggregationBuilders.dateHistogram("agg")
.field("@timestamp")
.calendarInterval(DateHistogramInterval.DAY)
.subAggregation(
AggregationBuilders.terms("count").field("clientip.keyword")));
searchRequest.source(searchSourceBuilder);
// 执行聚合查询请求并输出结果
SearchResponse searchResponse = client.search(searchRequest);
Aggregations aggregations = searchResponse.getAggregations();
ParsedDateHistogram agg = aggregations.get("agg");
for (Histogram.Bucket entry : agg.getBuckets()) {
System.out.println("日期:" + entry.getKeyAsString());
ParsedStringTerms count = entry.getAggregations().get("count");
for (Terms.Bucket bucket : count.getBuckets()) {
System.out.println("IP地址:" + bucket.getKeyAsString() + ",访问次数:" + bucket.getDocCount());
}
}
通过Elasticsearch和Kibana的集成可以很方便地构建一个实时大数据分析系统更好地理解和利用数据。文章来源地址https://www.toymoban.com/news/detail-721993.html
到了这里,关于Elasticsearch 和 Kibana 的实时大数据分析系统的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!