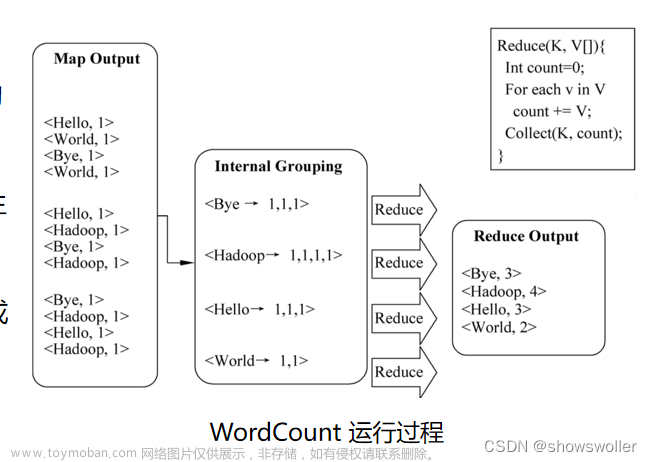
输入文件在你每次点击评测的时候,平台会为你创建,无需你自己创建,只需要启动HDFS,编写python代码即可。文章来源地址https://www.toymoban.com/news/detail-722004.html
第1关:成绩统计
- mapper.py
#! /usr/bin/python3
import sys
def main():
for line in sys.stdin:
line = line.strip()
mapper(line)
# 使用name,age分别表示姓名和年龄
def mapper(line):
########## begin ############
group = line.split('\\n')
for people in group:
if len(people.strip()) == 0:
continue
name, age = people.split(' ')
########### End #################
print("%s\t%s" % (name, age))
if __name__ == '__main__':
main()
- reducer.py
#! /usr/bin/python3
import sys
from operator import itemgetter
# 找出values的最大值,并按name\tmax_age的形式输出。
def reducer(k, values):
##### Begin #########
print("%s\t%s" % (k,max(values)))
##### End #########
#############################################
# mapper的输出经过分区处理后,数据行按照键排序;
# 具有相同键的行排在一起;
# hadoop-streaming不会合并相同键的各个值。
# 下面的代码将相同键的各个值放到同一个列表中,
# 并调用reducer函数实现找出每个人的最大年龄并输出;
# 输出格式为:姓名\年龄
#############################################
def main():
current_name = None
ages = []
name, age = '', 0
for line in sys.stdin:
line = line.strip()
name, age = line.split('\t', 1)
age = int(age)
if current_name == name:
ages.append(age)
else:
if current_name:
reducer(current_name, ages)
ages = []
ages.append(age)
current_name = name
# 不要忘记最后一个人
if current_name == name:
reducer(current_name, ages)
if __name__ == '__main__':
main()
第2关:文件内容合并去重
- mapper.py
#! /usr/bin/python3
import sys
def main():
for line in sys.stdin:
line = line.strip()
mapper(line)
def mapper(line):
########## Begin ###############
items = line.split('\\n')
for item in items:
key,value = item.split()
print("%s\t%s" % (key,value))
########### End #############
if __name__ == '__main__':
main()
- reducer.py
#! /usr/bin/python3
import sys
def reducer(k, values):
############ Begin ################
value = sorted(list(set(values)))
for v in value:
print("%s\t%s" % (k,v))
############ End ################
def main():
current_key = None
values = []
akey, avalue = None, None
for line in sys.stdin:
line = line.strip()
akey, avalue = line.split('\t')
if current_key == akey:
values.append(avalue)
else:
if current_key:
reducer(current_key, values)
values = []
values.append(avalue)
current_key = akey
if current_key == akey:
reducer(current_key, values)
if __name__ == '__main__':
main()
第3关:信息挖掘 - 挖掘父子关系
- mapper.py
#! /usr/bin/python3
import sys
def mapper(line):
############### Begin ############
items = line.split("\\n")
for item in items:
child,parent = item.split()
print("%s\t%s" % (child,"p-"+parent))
print("%s\t%s" % (parent,"c-"+child))
############### End #############
def main():
for line in sys.stdin:
line = line.strip()
if line.startswith('child'):
pass
else:
mapper(line)
if __name__ == '__main__':
main()
- reducer.py
#! /usr/bin/python3
import sys
def reducer(k, values):
############## Begin ################
grandc = []
grandp = []
for value in values:
if value[:2] == 'c-':
grandc.append(value[2:])
elif value[:2] == 'p-':
grandp.append(value[2:])
for c in grandc:
for p in grandp:
print("%s\t%s" % (c,p))
############## End #################
def main():
current_key = None
values = []
akey, avalue = None, None
print("grand_child\tgrand_parent")
for line in sys.stdin:
line = line.strip()
try:
akey, avalue = line.split('\t')
except:
continue
if current_key == akey:
values.append(avalue)
else:
if current_key:
reducer(current_key, values)
values = []
values.append(avalue)
current_key = akey
if current_key == akey:
reducer(current_key, values)
if __name__ == '__main__':
main()
文章来源:https://www.toymoban.com/news/detail-722004.html
到了这里,关于3.1 python版MapReduce基础实战的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!