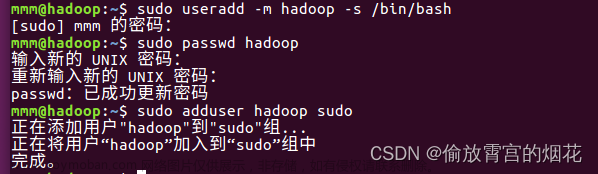
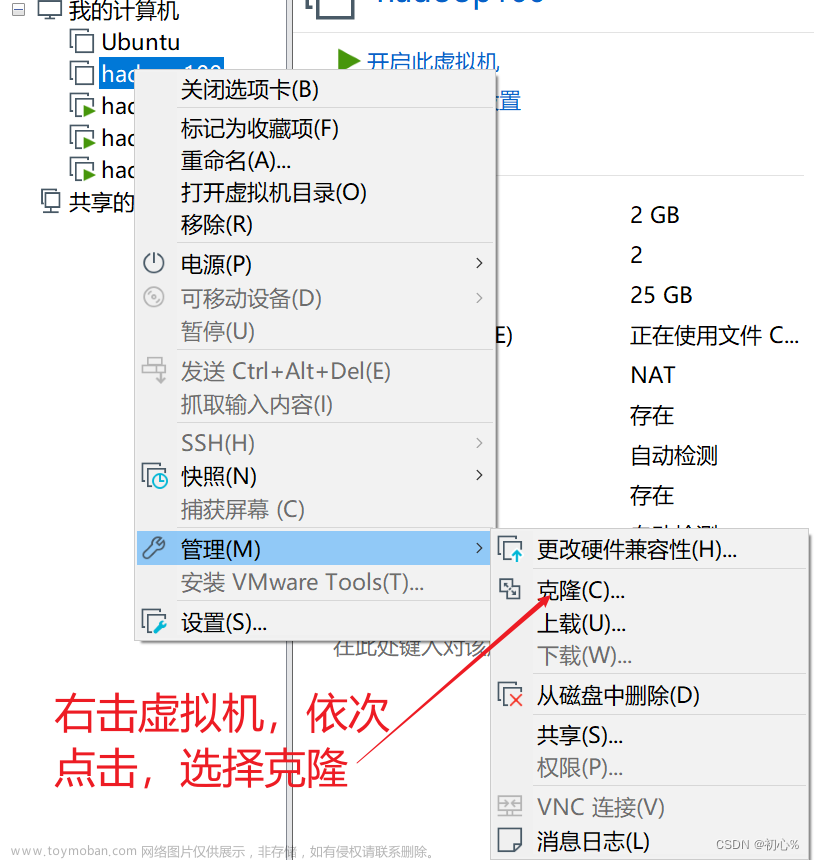
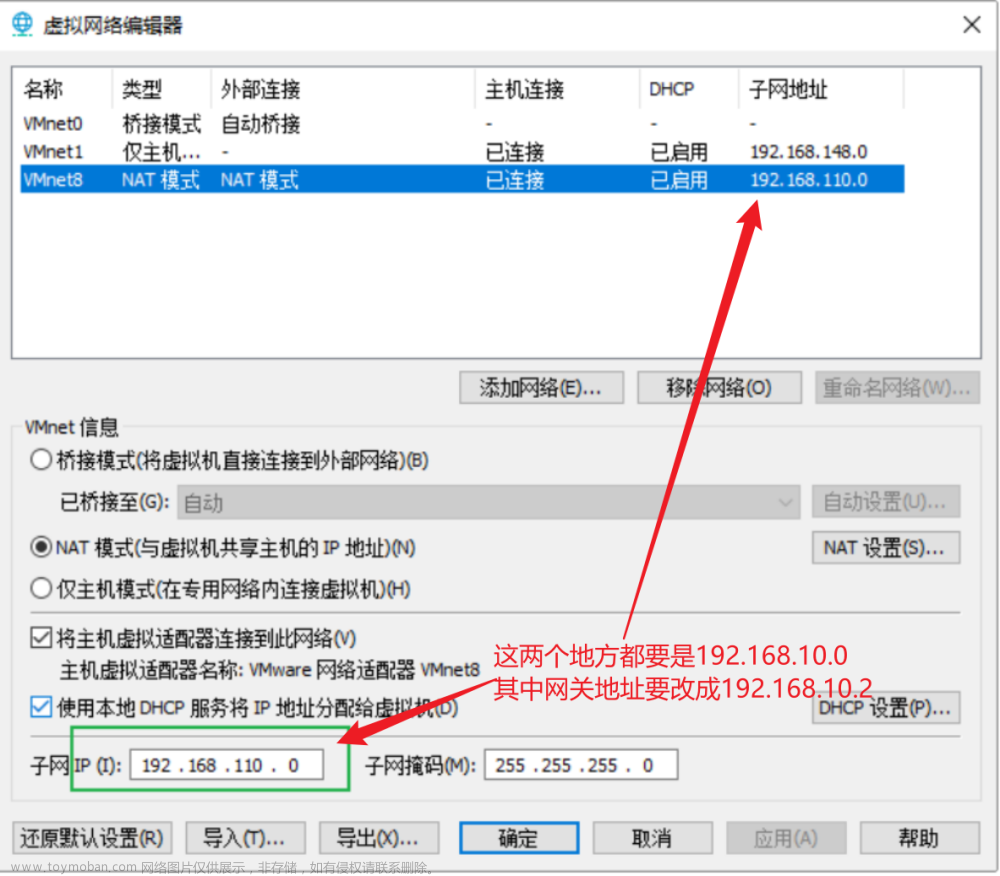
分别创建三个节点 master slave1 slave2
在master节点下安装jdk
# 解压
[root@master /]# tar -zxvf /opt/software/jdk-8u212-linux-x64.tar.gz -C /opt/module/
# 修改安装包名为 java
[root@master /]# mv /opt/module/jdk1.8.0—212/ /opt/module/java
# 配置环境变量并使其生效
[root@master /]# vi /etc/profile
# java
export JAVA_HOME=/opt/module/java
export PATH=$PATH:$JAVA_HOME/bin
# 验证是否成功
[root@master /]# source /etc/profile
[root@master /]# java -version
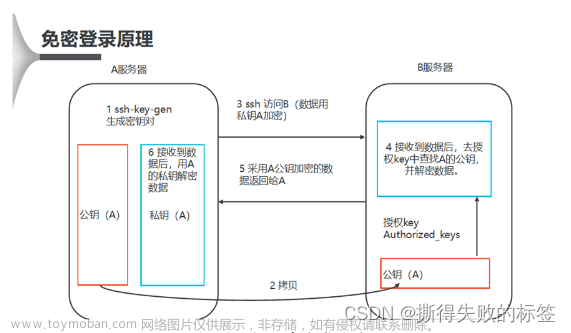
[root@master /]# javac配置免密登录
# 配置映射环境
[root@master /]# vi /etc/host
# 添加三个节点的IP映射
192.168.100.4 master
192.168.100.2 slave1
192.168.100.3 slave2
# 创建密钥 (三个节点都要创建)
[root@master /]# ssh-keygen -t rsa -P ''
# 将公钥传输给master slave1 slave2
[root@master /]# ssh-copy-id root@master
[root@master /]# ssh-copy-id root@slave1
[root@master /]# ssh-copy-id root@slave2
# 将Java安装文件传送给slave1 slave2
[root@master /]# scp -r /opt/module/java/ root@slave1:/opt/module/
[root@master /]# scp -r /opt/module/java/ root@slave2:/opt/module/Hadoop安装与配置
# 解压Hadoop到指定文件中
[root@master /]# tar -zxvf /opt/software/hadoop-3.1.3.tar.gz -C /opt/module/
# 修改Hadoop名称
[root@master /]# mv /opt/module/hadoop-3.1.3/ /opt/module/hadoop
# 配置环境变量
#hadoop
export HADOOP_HOME=/opt/module/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin切换到Hadoop的etc\hadoop目录下并进行相关配置
1.配置workers文件
# 配置workers 文件
[root@master /]# vi workers
master
slave1
slave22.配置Hadoop-env.sh文件
# 配置Hadoop-env.sh文件
export JAVA_HOME=/opt/module/java
export HADOOP_PERFIX=/opt/module/hadoop
export HADOOP_OPTS="-Djava.library.path=$HADOOP_PERFIX/lib:$HADOOP_PERFIX/lib/native"
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root3. 配置core-site.xml 文件
<!-- 配置core-site.xml 文件 -->
[root@master hadoop]# vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop/tmp</value>
</property>
</configuration>4.配置mapred-site.xml 文件
<!--配置mapred-site.xml 文件-->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>5. 配置hdfs-site.xml文件
<!--配置hdfs-site.xml文件-->
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/module/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/module/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>6. 配置yarn-site.xml 文件
<!--配置yarn-site.xml 文件-->
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>创建相关目录并分发
# 创建
[root@master hadoop]# mkdir -p /opt/module/hadoop/dfs/name
[root@master hadoop]# mkdir -p /opt/module/hadoop/dfs/data
[root@master hadoop]# mkdir -p /opt/module/hadoop/tmp
#分发
[root@master hadoop]# scp -r /opt/module/hadoop/ root@slave1:/opt/module/
[root@master hadoop]# scp -r /opt/module/hadoop/ root@slave2:/opt/module/
#同步环境
[root@master hadoop]# scp /etc/profile root@slave1:/etc
[root@master hadoop]# scp /etc/profile root@slave2:/etc
# 生效环境(三台都要)
[root@master hadoop]# source /etc/profileHadoop集群启动
# 初始化namenode
[root@master hadoop]# hdfs namenode -format
# 启动hdfs
[root@master /]# start-dfs.sh
# 启动yarn
[root@master /]# start-yarn.sh验证
# jps查看三个节点进程
# master
[root@master /]# jps
2833 Jps
1509 NameNode
1654 DataNode
2262 ResourceManager
1898 SecondaryNameNode
2429 NodeManager
# slave1
[root@slave1 /]# jps
642 NodeManager
787 Jps
511 DataNode
# slave2
[root@slave1 /]# jps
642 NodeManager
787 Jps
511 DataNode
#端口验证
HDFS :9870
YARN :8088端口测试
master:9870查看

ii. master:8088查看

mapreduce测试
[root@master /]# vi a.txt
[root@master /]# hadoop fs -put ~/a.txt /input
# 进入到jar包测试文件目录下
[root@master /]# cd /opt/module/hadoop/share/hadoop/mapreduce/
# 测试mapreduce
[root@master mapreduce]# hadoop jar hadoop-mapreduce-examples-3.1.3.jar wordcount /input/a.txt /output
# 测试结果
Map-Reduce Framework
Map input records=3
Map output records=6
Map output bytes=59
Map output materialized bytes=53
Input split bytes=95
Combine input records=6
Combine output records=4
Reduce input groups=4
Reduce shuffle bytes=53
Reduce input records=4
Reduce output records=4
Spilled Records=8
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=172
CPU time spent (ms)=1580
Physical memory (bytes) snapshot=664891392
Virtual memory (bytes) snapshot=5363101696
Total committed heap usage (bytes)=745537536
Peak Map Physical memory (bytes)=382193664
Peak Map Virtual memory (bytes)=2678300672
Peak Reduce Physical memory (bytes)=282697728
Peak Reduce Virtual memory (bytes)=2684801024
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=35
File Output Format Counters
Bytes Written=31
[root@master mapreduce]# hadoop fs -ls /output
Found 2 items
-rw-r--r-- 3 root supergroup 0 2023-03-19 18:02 /output/_SUCCESS
-rw-r--r-- 3 root supergroup 31 2023-03-19 18:02 /output/part-r-00000
[root@master mapreduce]# hadoop fs -cat /output/part-r-00000
2023-03-19 18:03:45,508 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
EOPE 1
HADOOP 1
HELLO 3
JAVA 1注意:如果出现一下问题:
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
Please check whether your etc/hadoop/mapred-site.xml contains the below configuration:
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${full path of your hadoop distribution directory}</value>
</property>解决方法:
<!-- 输入以下命令回车-->
[root@master mapreduce]# hadoop classpath
//将生成的这堆代码添加至yarn-site.xml中
/opt/module/hadoop/etc/hadoop:/opt/module/hadoop/share/hadoop/common/lib/*:/opt/module/hadoop/share/hadoop/common/*:/opt/module/hadoop/share/hadoop/hdfs:/opt/module/hadoop/share/hadoop/hdfs/lib/*:/opt/module/hadoop/share/hadoop/hdfs/*:/opt/module/hadoop/share/hadoop/mapreduce/lib/*:/opt/module/hadoop/share/hadoop/mapreduce/*:/opt/module/hadoop/share/hadoop/yarn:/opt/module/hadoop/share/hadoop/yarn/lib/*:/opt/module/hadoop/share/hadoop/yarn/*
[root@master hadoop]# vi yarn-site.xml //添加至最后
<property>
<name>yarn.application.classpath</name>
<value>/opt/module/hadoop/etc/hadoop:/opt/module/hadoop/share/hadoop/common/lib/*:/opt/module/hadoop/share/hadoop/common/*:/opt/module/hadoop/share/hadoop/hdfs:/opt/module/hadoop/share/hadoop/hdfs/lib/*:/opt/module/hadoop/share/hadoop/hdfs/*:/opt/module/hadoop/share/hadoop/mapreduce/lib/*:/opt/module/hadoop/share/hadoop/mapreduce/*:/opt/module/hadoop/share/hadoop/yarn:/opt/module/hadoop/share/hadoop/yarn/lib/*:/opt/module/hadoop/share/hadoop/yarn/*
</value>
</property>《恭喜您搭建成功!》
文章来源地址https://www.toymoban.com/news/detail-722566.html
文章来源:https://www.toymoban.com/news/detail-722566.html
到了这里,关于Hadoop完全分布式搭建教程(完整版)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!