大家好,今天我们用python语言去实现概率论与数理统计的一些基础计算等。常用第三方SciPy库、NumPy库来实现概率论和数理统计的计算。
SciPy是一个基于Python的开源库,是一组专门解决科学计算中各种基本问题的模块的集合,经常与NumPy、StatsModels、SymPy这些库一起使用。SciPy的不同子模块有不同的应用,如插值、积分、优化、图像处理等。
一、众数
众数是一组数据中出现次数最多的变量值,是集中趋势的测度值之一,一般用M0表示。
使用SciPy库中stats模块的mode函数可以求数据的众数,其语法格式如下:
scipy.stats.mode(a,axis=0,nan_policy='propagate')
#a:接受 array,表示需要求众数的数据。无默认值
#axis:接受int,表示计算的轴向。默认为0求某数据的众数:
from scipy import stats as sts#导入库SciPy的stats模块
import numpy as np
#读取保存的某数据
data = np.loadtxt(r'D:/data/salary.csv',delimiter=',')
print('众数为:',sts.mode(data,axis=None))输出结果:
众数为:ModeResult(mode=array([3880.]), count=array([2]))二、中位数
中位数又称中数、中值,是一组按大小顺序排列在一起的数据中位于中间位置的数,一般用Me表示。
使用NumPy库中的median函数可以求数据的中位数,其语法格式如下:
numpy.median(a,axis=None,out=None,over write_iput=False
keepdims=False)
#a:接受 array,表示需要求中位数的数据。无默认值
#axis:接受int,表示计算的轴向。默认为None求某数据的中位数:
import numpy as np#导入库Numpy
#读取保存的某数据
data = np.loadtxt(r'D:/data/salary.csv',delimiter=',')
print('中位数为:',np.median(data))输出结果:
中位数为:3905.0三、 四分位数
四分位数又称四分位点,将数据等分成4个部分。一组数据中有3个四分位数,分别位于这组数据排序后的25%、50%和75%的位置上,等分后的每个部分包含25%的数据。位于25%位置上的四分位数称为下四分位数,用QL表示;位于50%位置上的四分位数就是中位数,用QM表示;位于75%位置上的四分位数称为上四分位数,用QU表示。
使用SciPy库中stats模块的scoreatpercentile函数可以求数据的四分位数,其语法格式如下:
scipy.stats.scoreatpercentile(a,per,limit(),interpolation_method='fraction',axis=None)
# a:接受 array,表示需要求分位数的数据。无默认值
# per:接受数值型,表示指提取的百分位数,范围为【0,100】。无默认值
# interpolation_method:接受指定的string,可选择不同的参数来来返回不同值:
取值为fraction时,表示若存在多个值,则返回它们值的平均数
取值为lower时,表示若存在多个值,则返回它们中的最小值;
取值为higher时,表示若存在多个值,则返回它们中的最大值。
# axis:接受int。表示计算的轴向。默认为None使用SciPy库中stats模块的percentileofscore函数也可以求数据的四分位数,其语法格式如下:
scipy.stats.percentileofscore(a,score,kind='rank')
# a:接受 array,表示需要求分位数的数据。无默认值
# score:接受int/float,表示指定a中需要求所处分位数的元素。无默认值
# interpolation_method:接受指定的string,可选择不同的参数来来返回不同值:
取值为rank时,表示若存在多个值,则返回它们值的平均数
取值为weak时,表示若存在多个值,则返回小于所选元素的分位数;
取值为strict时,表示若存在多个值,则返回小于或等于所选元素的分位数;
取值为mean时,表示若存在多个值,则返回weak和stric的平均数。默认为rank根据某表的数据,求该组数据的下四分位数与上四分位数,并求该组数据中3850所处的分位数。
from scipy import stats as sts#导入库SciPy的stats模块
import numpy as np#导入库Numpy
#读取保存的某数据
data = np.loadtxt(r'D:/data/salary.csv',delimiter=',')
print('下四分位数为',sts.scoreatpercentile(data,25,interpolation_method='lower'))
print('上四分位数为',sts.scoreatpercentile(data,75,interpolation_method='lower'))
print('3850所处的分位数为:',sts.percentileofscore(data,3850),'%')结果输出:
下四分位数为 3850.0
上四分位数为 3950.0
3850所处的分位数为:25.0 %四、 平均数
4.1 算术平均数
算术平均数也称为平均值,通常是一组数据相加后除以数据的个数得到的结果。算术平均数是集中趋势最主要的测度值。根据分组数据计算的算术平均数称为加权算术平均数。
使用SciPy库中的stats模块的tmean函数可以求数据的简单算术平均数,其语法格式如下:
scipy.stats.tmean(a,limits=None,inclusive(True,True),axis=None)
# a:接受 array,表示需要求简单算术平均数的数据。无默认值
# limits:接受tuple,可指定需要求简单算术平均数的数据的范围。默认为None
# axis:接受int,表示计算的轴向。默认为None使用NumPy库中的mean函数也可以求数据的简单算术平均数,其语法格式如下:
numpy.mean(a,axis=None,dtype=None,out=None,keepdims=<class numpy._globals._NoValue>)
# a:接受 array,表示需要求简单算术平均数的数据。无默认值
# axis:接受int/tuple,表示计算的轴向。默认为None4.2 调和平均数
和平均数也称为倒数平均数,是总体内各个变量值倒数1/x的算术平均数的倒数。
使用SciPy库中的stats模块的hmean函数可以求数据的调和平均数,其语法格式如下:
scipy.stats.hmean(a,axis=0,dtype=None)
# a:接受 array,表示需要求调和算术平均数的数据。无默认值
# axis:接受int,表示计算的轴向。默认为None求某组数据的调和平均数:
from scipy import stats as sts#导入库SciPy的stats模块
import numpy as np#导入库Numpy
#读取保存的某数据
data = np.loadtxt(r'D:/data/salary.csv',delimiter=',')
print('调和平均数为:',sts.hmean(data))结果输出:
调和平均数为:3926.78974959936574.3 几何平均数
几何平均数是n个变量值乘积的n次方根。
使用SciPy库中的stats模块的gmean函数可以求数据的几何平均数,其语法格式如下:
scipy.stats.gmean(a,axis=0,dtype=None)
# a:接受 array,表示需要求调和算术平均数的数据。无默认值
# axis:接受int,表示计算的轴向。默认为None求某组数据的几何平均数:
from scipy import stats as sts#导入库SciPy的stats模块
import numpy as np#导入库Numpy
#读取保存的某数据
data = np.loadtxt(r'D:/data/salary.csv',delimiter=',')
print('几何平均数为:',sts.gmean(data))结果输出:
几何平均数为:3929.2144614926315五、 极差
极差又称范围误差或全距,是指一组数据中最大值与最小值的差,通常用R表示。
使用NumPy库中的ptp函数可以求数据的极差,其语法格式如下:
numpy.ptp(a,axis=None,out=None)
# a:接受 array,表示需要求极差的数据。无默认值
# axis:接受int,表示计算的轴向。默认为0求某组的极差:
import numpy as np#导入库Numpy
#读取保存的某数据
data = np.loadtxt(r'D:/data/salary.csv',delimiter=',')
print('极差为:',np.ptp(data))结果输出:
极差为:515.0六、 四分位数间距
四分位数间距又称为四分位差或内距,是上四分位数与下四分位数之差,一般用Qd表示。
from scipy import stats as sts#导入库SciPy的stats模块
import numpy as np#导入库Numpy
#读取保存的某数据
data = np.loadtxt(r'D:/data/salary.csv',delimiter=',')
print('四分位数间距为',sts.scoreatpercentile(data,75,\
interpolation_method='lower')-sts.scoreatpercentile(data,25,interpolation_method='lower'))结果输出:
四分位数间距为 100.0七、 方差
方差是一组数据中的各数据值与该组数据算术平均数之差的平方的算术平均数。
使用SciPy库中的stats模块的tvar函数可以求数据的样本方差,其语法格式如下:
scipy.stats.tvar(a,limits=None,inclusive(True,True),axis=0,ddof=1)
# a:接受 array,表示需要求样本方差的数据。无默认值
# axis:接受int,表示计算的轴向。默认为None使用NumPy库中的var函数可以求数据的总体方差,其语法格式如下:
numpy.var(a,axis=None,dtype=None,out=None,ddof=0,keepdims=<class numpy._globals._NoValue>)
# a:接受 array,表示需要求总体方差的数据。无默认值
# axis:接受int/tuple,表示计算的轴向。默认为None求某组数据的方差:
from scipy import stats as sts#导入库SciPy的stats模块
import numpy as np#导入库Numpy
#读取保存的某数据
data = np.loadtxt(r'D:/data/salary.csv',delimiter=',')
print('样本方差为:',sts.tvar(data))结果输出 :
样本方差为:21274.242424242424八、 标准差
标准差为方差的开方,与方差类似,可分为总体标准差与样本标准差,也可分为未分组数据标准差与分组数据标准差。总体标准差常用σ表示,样本标准差常用S表示。
使用SciPy库中的stats模块的tstd函数可以求数据的样本标准差,其语法格式如下:
scipy.stats.tstd(a,limits=None,inclusive(True,True),axis=0,ddof=1)
# a:接受 array,表示需要求样本标准差的数据。无默认值
# axis:接受int,表示计算的轴向。默认为None求某组数据的样本标准差:
from scipy import stats as sts#导入库SciPy的stats模块
import numpy as np#导入库Numpy
#读取保存的某数据
data = np.loadtxt(r'D:/data/salary.csv',delimiter=',')
print('样本标准差:',sts.tstd(data))结果输出:
样本标准差:145.85692449877868九、 变异系数
对不同变量或不同数组的离散程度进行比较时,如果它们的平均水平和计量单位都相同,才能利用上述指标进行分析,否则需利用变异系数来比较它们的离散程度。
变异系数又称为离散系数,是一组数据中的极差、四分位差或标准差等离散指标与算术平均数的比率。
求标准差变异系数:
from scipy import stats as sts#导入库SciPy的stats模块
import numpy as np#导入库Numpy
#读取保存的某数据
data = np.loadtxt(r'D:/data/salary.csv',delimiter=',')
print('标准差变异系数:',sts.tstd(data)/sts.tmean(data))结果输出:
标准差变异系数:0.03709798842698907十、偏度
偏度系数是对分布偏斜程度的测度,通常用SK表示。偏度衡量随机变量概率分布的不对称性,是相对于平均值不对称程度的度量。

当偏度系数为正值时,表示正偏离差数值较大,可以判断为正偏态或右偏态;反之,当偏度系数为负值时,表示负偏离差数值较大,可以判断为负偏态或左偏态。偏度系数的绝对值越大,表示偏斜的程度就越大。
使用SciPy库中的stats模块的skew函数可以求数据的偏度,其语法格式如下:
scipy.stats.skew(a,axis=0,bias=True,nan_policy='propagate')
# a:接受 array,表示需要求偏度的数据。无默认值
# axis:接受int,表示计算的轴向。默认为0求某数据的偏度:
from scipy import stats as sts#导入库SciPy的stats模块
import numpy as np#导入库Numpy
#读取保存的某数据
data = np.loadtxt(r'D:/data/salary.csv',delimiter=',')
print('偏度为:',sts.skew(data))结果输出:
偏度为:0.5325875397307566十一、峰度
峰度描述的是分布集中趋势高峰的形态,通常与标准正态分布相比较。在归化到同一方差时,若分布的形状比标准正态分布更“瘦”、更“高”,则称为尖峰分布;若比标准正态分布更“矮”、更“胖”,则称为平峰分布。
峰度系数是对分布峰度的测度,通常用K表示:

由于标准正态分布的峰度系数为0,所以当峰度系数大于0时为尖峰分布,当峰度系数小于0时为平峰分布。
使用SciPy库中的stats模块的kurtosis函数可以求数据的峰度,其语法格式如下:
scipy.stats.kurtosis(a,axis=0,fisher=Ture,bias=True,nan_policy='propagate')
# a:接受 array,表示需要求峰度的数据。无默认值
# axis:接受int,表示计算的轴向。默认为0求某数据的峰度:
from scipy import stats as sts#导入库SciPy的stats模块
import numpy as np#导入库Numpy
#读取保存的某数据
data = np.loadtxt(r'D:/data/salary.csv',delimiter=',')
print('峰度为:',sts.kurtosis(data))结果输出:
峰度为: -0.2396155690457311十二、二项分布-离散型分布
使用SciPy库中的stats模块的binom类下的pmf方法可以求得服从二项分布的随机变量的概率,其语法格式如下:
scipy.stats.binom.pmf(x,n,p,loc=0)
# a:接受 array,表示需要求解的数据。无默认值
# n:接受int,表示试验的次数。无默认值
# p:接受数值型,表示每次试验发生的概率。无默认值掷10次硬币,求恰好两次正面朝上的概率:
from scipy import stats as sts#导入库SciPy的stats模块
import numpy as np#导入库Numpy
n = 10 #独立试验的次数
p = 0.5 #每次正面的哦概率
k = np.arange(0,11) #总共有0~10次正面朝上的概率
print('0~10次正面朝上的概率为:\n',sts.binom.pmf(k,n,p))
print('2次正面朝上的概率为:',sts.binom.pmf(k,n,p)[2])结果输出:
0~10次正面朝上的概率为:
[0.00097656 0.00976563 0.04394531 0.1171875 0.20507812 0.24609375
0.20507812 0.1171875 0.04394531 0.00976563 0.00097656]
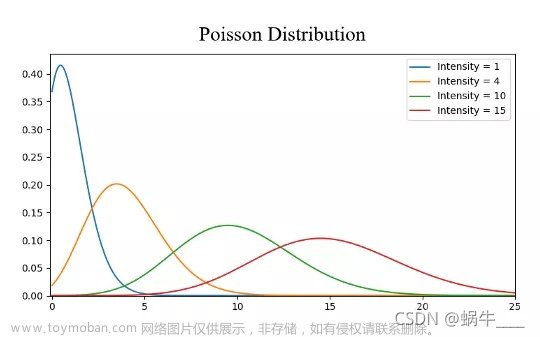
2次正面朝上的概率为:0.04394531250000004十三、泊松分布-离散型分布
使用SciPy库中的stats模块的poisson类下的pmf方法可以求得服从泊松分布的随机变量的概率,其语法格式如下:
scipy.stats.poisson.pmf(k,mu,loc=0)
# k:接受 array,表示需要求解的数据。无默认值
# mu:接受数值型,表示λ的值。无默认值已知某路口发生事故的频率是平均每天2次,求此处一天内发生4次事故的概率:
from scipy import stats as sts#导入库SciPy的stats模块
import numpy as np#导入库Numpy
mu = 2 #λ的值
k = np.arange(0,11) #假设总共有0~10次发生事故的概率
print('0-10次发生事故的概率分别为:\n',sts.poisson.pmf(k,mu))
print('发生4次事故的概率为:',sts.poisson.pmf(k,mu)[4])结果输出:
0-10次发生事故的概率分别为:
[1.35335283e-01 2.70670566e-01 2.70670566e-01 1.80447044e-01
9.02235222e-02 3.60894089e-02 1.20298030e-02 3.43708656e-03
8.59271640e-04 1.90949253e-04 3.81898506e-05]
发生4次事故的概率为:0.09022352215774178十四、均匀分布-连续型分布
使用SciPy库中的stats模块的randint类下的pmf方法可以求得服从均匀分布的随机变量的概率,其语法格式如下:
scipy.stats.randint.pmf(k,low,high,loc=0)
# k:接受 array,表示需要求解的数据。无默认值
# low:接受数值型,表示均匀分布的区间下限,即a。无默认值
# high:接受数值型,表示均匀分布的区间上限,即b。无默认值设随机变量X表示飞机从芝加哥到纽约的飞行时间,X可以是120~140min之间的任意值。求飞机飞行时间为135min的概率:
from scipy import stats as sts#导入库SciPy的stats模块
k = 135 #目标值
a = 120 #最低值
b = 140 #最高值
print('飞行135分钟的概率为:',sts.randint.pmf(k,a,b))结果输出:
飞行135分钟的概率为:0.05十五、指数分布-连续型分布
使用SciPy库中的stats模块的expon类下的pmf方法可以求得服从均匀分布的随机变量的概率,其语法格式如下:
scipy.stats.expon.pdf(x,loc=0,scale=1)
# x:接受 array,表示需要求解的数据。无默认值
# scale:接受数值型,表示λ的倒数。默认为1设某电子元件的寿命X(年)服从λ=3的指数分布,求该电子元件寿命为两年的概率:
from scipy import stats as sts#导入库SciPy的stats模块
import numpy as np#导入库Numpy
x = np.arange(0,11) #假设元件寿命有0~10年11可能
s = 1/3 #λ的倒数
print('0-10年的概率分别为:\n',sts.expon.pdf(x,scale=s))
print('寿命为两年的概率为:',sts.expon.pdf(x,scale=s)[2])结果输出:
0-10年的概率分别为:
[3.00000000e+00 1.49361205e-01 7.43625653e-03 3.70229412e-04
1.84326371e-05 9.17706962e-07 4.56899392e-08 2.27476813e-09
1.13254036e-10 5.63858645e-12 2.80728689e-13]
寿命为两年的概率为:0.0074362565299990755十六、正态分布-连续型分布
使用SciPy库中的stats模块的norm类下的pdf方法可以求得服从正态分布的随机变量的概率,其语法格式如下:
scipy.stats.norm.pdf(x,loc=0,scale=1)
# x:接受 array,表示需要求解的数据。无默认值
# loc:接受数值型,表示μ的值。默认为0
# scale:接受数值型,表示σ的值。默认为1某地区的月降水量服从μ=40,σ=4(单位:mm)的正态分布,求某月的月降水量为50mm的概率:文章来源:https://www.toymoban.com/news/detail-722736.html
from scipy import stats as sts#导入库SciPy的stats模块
print('降水量为50mm的概率为:',sts.norm.pdf(50,40,4))输出结果:文章来源地址https://www.toymoban.com/news/detail-722736.html
降水量为50mm的概率为:0.004382075123392135到了这里,关于python数据分析-概率论与数理统计基础的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!