正态分布的概率密度函数(Probability Density Function,简称PDF)的函数取值是指在给定的正态分布参数(均值 μ 和标准差 σ)下,对于特定的随机变量取值 x,计算得到的概率密度值 f(x)。这个值表示了在正态分布下,随机变量取值为 x 的概率密度。
具体地,正态分布的概率密度函数取值计算公式如下:

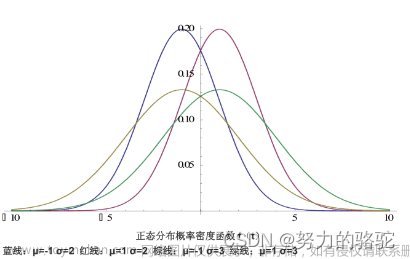
这个概率密度函数描述了随机变量 x 取不同值时的概率密度分布,换句话说,f(x) 表示了随机变量 X 在 x 处的相对概率。。正态分布的曲线呈钟形,以均值 μ 为中心,标准差 σ 决定了曲线的宽度。数据点离均值越远,概率密度越低。
概率密度与概率:概率密度函数给出了不同取值处的概率密度,但对于连续型随机变量来说,单个点的概率密度为零。概率是在一个区间内的概率密度的累积,而不是单个点的概率。
正态分布的概率密度函数的概率密度值不是直接的概率,而是描述了随机变量在不同取值处相对概率密度的分布。要计算具体的概率,你需要使用积分来计算区间内的概率。
正态分布的概率密度函数 f(x) 是一个数学函数,用于描述在正态分布中随机变量 X 取某个特定值 x 的概率密度。简单来说,它表示了在给定正态分布的均值(μ)和标准差(σ)下,随机变量 X 等于某个具体值 x 的相对可能性。
具体来说,f(x) 可以解释为以下两个要点:
相对可能性:f(x) 不是直接的概率值,而是概率密度。它告诉你在正态分布下,随机变量 X 取某个特定值 x 的相对可能性。如果在某个 x 处的 f(x) 较高,表示该值在正态分布中出现的可能性较大。
曲线下的面积:正态分布的概率密度函数图形呈钟形曲线。通过对曲线下的面积进行积分,你可以得到随机变量 X 落在某个值或值的范围内的概率。这意味着如果你想知道 X 落在某个区间内的概率,你可以通过积分 f(x) 来计算。
总结一下,概率密度函数 f(x) 是一个函数,它用于描述正态分布中各个可能取值的相对可能性。它是概率密度的一种表示方式,而不是直接的概率值。通过对 f(x) 进行积分,你可以计算出在正态分布中随机变量 X 落在某个值或值的范围内的概率。
概率密度函数(Probability Density Function,PDF)描述了连续型随机变量在不同取值处的相对概率密度。这意味着 PDF 反映了随机变量在不同取值处出现的相对频率或密度,而不是直接的概率。
下面是关于 PDF 下不同取值的一些重要概念:
概率密度值:PDF 的值 f(x) 表示了在随机变量取到特定值 x附近的相对概率密度。具体来说,f(x)表示了在 x处的单位概率密度,即在无限小的区间内的相对概率密度。
取值范围:PDF 描述了随机变量的所有可能取值范围内的概率密度分布。这个范围通常是连续的,因此在每个具体的取值处的概率密度值是无限小的。
曲线形状:PDF 的图形通常是一条曲线,它的形状由随机变量的分布特性决定。例如,正态分布的 PDF 是钟形曲线,峰值位于均值处,表示在均值附近的取值具有较高的相对概率密度。
概率计算:要计算随机变量落在某个区间 [a, b]$内的概率,你可以使用积分来计算。
概率比较:通过比较 PDF 在不同取值处的相对概率密度,你可以理解不同取值的相对频率。较高的概率密度值表示在该处的取值更频繁,而较低的概率密度值表示在该处的取值较少见。
总之,概率密度函数下的不同取值处的相对概率密度描述了连续型随机变量的相对频率或密度分布情况。这允许我们理解随机变量在不同取值处出现的相对频率,但要计算具体的概率,需要使用积分来考虑区间内的概率。
正态分布的概率密度函数是一个用于描述数据在不同值处的概率密度分布的数学方程,它在统计学和数据科学中非常重要,因为它允许我们量化数据点出现在不同位置的可能性。这是正态分布在各种应用中广泛使用的原因之一。
-----------
正态分布在统计学和数据分析中的关键作用无法被低估。以下是一些关于正态分布在这些领域的重要作用:
-
参数估计:正态分布的性质使得它在参数估计中非常有用。通过对数据进行最大似然估计,可以估计出正态分布的均值和标准差,从而对数据的总体特征有更好的了解。
-
假设检验:许多假设检验方法都基于正态分布的性质,例如t-检验、F-检验等。这些检验方法用于比较不同组之间的均值或方差,以确定它们是否显著不同。
-
统计推断:正态分布在统计推断中扮演着关键角色。通过对正态分布的参数进行估计和假设检验,可以得出关于总体的推断,如置信区间和假设的可信度。
-
中心极限定理:中心极限定理表明,大量独立随机变量的均值趋向于服从正态分布。这一定理使得正态分布成为在大样本条件下进行统计推断的基础,因为它解释了为什么许多现实世界的数据在均值附近呈正态分布。
-
模型拟合:正态分布通常用于拟合数据,因为它对许多自然和社会现象的数据分布具有较好的拟合性。这对于建立统计模型和预测未来数据点非常重要。
-
可视化:正态分布的概率密度函数图形是一种常用的可视化工具,用于理解数据的分布特征。通过绘制正态分布曲线,可以快速了解数据的中心位置和分散度。
-
风险管理和金融:在金融领域,正态分布通常用于建模资产价格的波动性,这对于风险管理和投资决策至关重要。
-
工程和自然科学:正态分布在工程、物理学、生物学等自然科学领域中广泛用于建模和分析现象,例如测量误差、天气模型等。
总之,正态分布的数学性质和应用广泛性使其成为统计学和数据分析中不可或缺的工具。它有助于我们理解和解释各种自然和社会现象的统计性质,从而支持科学研究、决策制定和问题解决。
-------------------
正态分布的峰度和偏度是描述分布形状的两个统计特征:
-
偏度(Skewness):偏度衡量了数据分布的偏斜程度。正态分布的偏度接近于0,表示分布是对称的,均值位于分布的中心,两侧的数据对称分布。当偏度为正时,数据分布右偏(尾部向右延伸),当偏度为负时,数据分布左偏(尾部向左延伸)。偏度的绝对值越大,偏斜程度越明显。
-
峰度(Kurtosis):峰度衡量了数据分布的尖锐度或平坦度。正态分布的峰度接近于3,这是正态分布的基准峰度。当峰度大于3时,分布被认为是具有尖峰形状(尾部较重),称为正偏峰度或"过度尖锐"。当峰度小于3时,分布被认为是具有平坦形状(尾部较轻),称为负偏峰度或"过度平坦"。
综上所述,正态分布的偏度接近0,表示对称分布,而峰度接近3,表示适度的尖峰形状。这两个统计量用于描述正态分布的形状特征,但对于其他类型的分布,它们的值可能会不同。在实际应用中,偏度和峰度可以帮助我们识别数据的分布特点,并与正态分布进行比较,以判断数据是否近似符合正态分布。
-------------------
正态分布检验用于确定给定数据集是否符合正态分布的假设。在统计学和数据分析中,通常有几种方法来进行正态分布检验,其中一些常见的方法包括:
-
Shapiro-Wilk检验:Shapiro-Wilk检验是一种广泛使用的方法,用于检验数据是否符合正态分布。它的原假设是数据符合正态分布。如果p值小于显著性水平(通常为0.05),则可以拒绝原假设,表示数据不符合正态分布。
-
D'Agostino和Pearson检验:这是另一种常见的正态分布检验方法。它基于数据的偏度和峰度来判断数据是否符合正态分布。与Shapiro-Wilk检验类似,如果p值小于显著性水平,可以拒绝正态分布假设。
-
Kolmogorov-Smirnov检验:这种检验方法用于比较给定数据与理论正态分布的拟合情况。它基于累积分布函数的差异来判断数据是否符合正态分布。
不同的正态性检验方法在使用上有不同的前提要求和特点。以下是一些常见的正态性检验方法以及它们的主要前提和特点:
Shapiro-Wilk测试:
- 前提要求: 数据是连续型的,并且样本量通常不宜太小(通常建议样本量大于5或10)。
- 特点: 这是一种相对较强大的正态性检验方法,适用于各种数据集大小。它对非正态性的敏感性相对较高,可以用于小样本和大样本。
Kolmogorov-Smirnov测试:
- 前提要求: 数据是连续型的。对于单样本检验,通常要求样本量不宜太小,对于双样本检验,两个样本的大小应该接近。
- 特点: 这个测试适用于比较数据与理论正态分布的累积分布函数。它比较灵活,可用于单样本和两样本比较。但对于小样本数据,可能不够敏感。
Anderson-Darling测试:
- 前提要求: 数据是连续型的。通常用于大样本数据。
- 特点: 这个测试是Shapiro-Wilk的扩展,对大样本数据效果较好,通常用于更大的样本量。它提供了一些不同权重的统计量,可用于不同的分布检验。
Q-Q图(Quantile-Quantile图):
- 前提要求: 适用于连续型数据。不需要特定的样本量,但图形解释可能需要经验。
- 特点: 这是一种可视化方法,通过直观比较数据的分位数和理论正态分布的分位数来判断数据是否符合正态分布。它提供了一个快速的初步印象,但不提供具体的p-value。
Lilliefors测试:
- 前提要求: 适用于小样本数据,通常用于样本量较小的情况。
- 特点: 这是Kolmogorov-Smirnov测试的变体,专门用于小样本数据。与标准Kolmogorov-Smirnov测试相比,它对小样本数据更敏感。
每种测试方法都有其适用范围和局限性,选择合适的方法取决于您的数据特点和研究问题。通常,建议结合多种方法的结果来做出最终的判断。此外,正态性检验通常是统计分析的一个步骤,而不是最终结论。
这些是一些常见的正态分布检验方法,你可以根据你的数据和需要选择适合的方法来验证数据是否符合正态分布。请注意,正态分布检验不一定要求数据完全服从正态分布,而是用于确定数据是否与正态分布具有显著的偏差。
import scipy.stats as stats
import numpy as np
# 生成模拟数据,这里使用NumPy生成随机正态分布数据
np.random.seed(0) # 设置随机种子以保持一致性
data = np.random.normal(0, 1, 1000) # 均值为0,标准差为1的正态分布数据,生成1000个数据点
# 使用Shapiro-Wilk检验
statistic, p_value = stats.shapiro(data)
if p_value > 0.05:
print("Shapiro-Wilk检验:数据符合正态分布")
else:
print("Shapiro-Wilk检验:数据不符合正态分布")
# 使用D'Agostino和Pearson检验
statistic, p_value = stats.normaltest(data)
if p_value > 0.05:
print("D'Agostino和Pearson检验:数据符合正态分布")
else:
print("D'Agostino和Pearson检验:数据不符合正态分布")
# 使用Kolmogorov-Smirnov检验
statistic, p_value = stats.kstest(data, 'norm')
if p_value > 0.05:
print("Kolmogorov-Smirnov检验:数据符合正态分布")
else:
print("Kolmogorov-Smirnov检验:数据不符合正态分布")
多种方式正态检验
import numpy as np
import pandas as pd
import scipy.stats as stats
import matplotlib.pyplot as plt
data = np.random.normal(loc=12, scale=2.5, size=340)
df = pd.DataFrame({'Data': data})
# 描述性统计分析
mean = df['Data'].mean()
std_dev = df['Data'].std()
skewness = df['Data'].skew()
kurtosis = df['Data'].kurtosis()
print("均值:", mean)
print("标准差:", std_dev)
print("偏度:", skewness)
print("峰度:", kurtosis)
# 创建一个2x1的子图布局
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(6, 6))
# 可视化 - stats.probplot正态概率图(Q-Q图)
stats.probplot(data, plot=ax1, dist='norm', fit=True, rvalue=True) #ax1作为绘图的位置
ax1.set_title("Q-Q Plot")
# 可视化 - 直方图
ax2.hist(data, bins=10, rwidth=0.8, density=True) # bins个柱状图,宽度是rwidth(0~1),=1没有缝隙
ax2.set_title("Histogram with Kernel Density Estimate")
# 调整子图之间的间距
plt.tight_layout()
# 显示图形
plt.show()
# 正态性检验 - Shapiro-Wilk检验
stat, p = stats.shapiro(data)
print("Shapiro-Wilk检验统计量:", stat)
print("Shapiro-Wilk检验p值:", p)
# Anderson-Darling检验
result = stats.anderson(df['Data'], dist='norm')
print("Anderson-Darling检验统计量:", result.statistic)
print("Anderson-Darling检验临界值:", result.critical_values)
# 执行单样本K-S检验,假设数据服从正态分布
statistic, p_value = stats.kstest(data, 'norm')
print("K-S检验统计量:", statistic)
print("K-S检验p值:", p_value)
# 执行正态分布检验
k2, p_value = stats.normaltest(data)
print(f"normaltest正态分布检验的统计量 (K^2): {k2}")
print(f"normaltest检验p值: {p_value}") 
scipy.stats 模块是 SciPy 库中的一个子模块,用于执行各种统计分析和概率分布相关的操作。该模块提供了许多函数,用于执行统计测试、拟合概率分布、生成随机变量等。以下是一些常见的 scipy.stats 模块的功能:
-
统计检验:
scipy.stats提供了许多统计检验方法,例如 t-检验、ANOVA、卡方检验、正态性检验等。这些方法用于分析数据集之间的差异,检验假设以及确定数据是否符合某些分布。 -
概率分布:该模块包含了许多连续和离散概率分布的实现,如正态分布、指数分布、泊松分布、伽马分布等。这些分布可以用于模拟和分析不同类型的随机变量。
-
拟合分布:你可以使用
fit函数来拟合数据到特定的概率分布。这对于确定数据是否符合某个已知分布以及估计分布的参数非常有用。 -
生成随机变量:
scipy.stats允许你生成随机变量,这些随机变量遵循指定的概率分布。这对于模拟实验和生成随机数据点非常有用。 -
描述性统计:你可以使用该模块来计算数据的描述性统计,如均值、标准差、中位数、百分位数等。
-
概率密度函数和累积分布函数:你可以使用该模块来计算概率密度函数(PDF)和累积分布函数(CDF)以及它们的反函数。
-
统计量计算:该模块提供了各种统计量的计算,如相关系数、协方差、偏度、峰度等。
-
假设检验:除了常见的 t-检验和卡方检验外,还提供了一些高级的假设检验方法,如Kolmogorov-Smirnov检验、Anderson-Darling检验等。
这只是 scipy.stats 模块的一部分功能。它是在统计学、数据分析和科学计算中非常有用的工具,可以用于处理和分析各种类型的数据,并进行统计推断和假设检验。如果需要特定功能的详细信息,可以查阅 SciPy 官方文档或进一步探索该模块的功能。
---------------------
Q-Q图(Quantile-Quantile Plot)是一种非常有用的可视化工具,用于比较实际数据分布与理论分布(如正态分布)之间的相似性。通过绘制一个散点图,Q-Q图可以帮助你直观地观察数据的分布与理论分布之间的关系。
Q-Q图的制作步骤如下:
-
收集实际数据:首先,你需要收集或准备你要分析的实际数据集。
-
排序数据:将实际数据按升序排列,以便后续的分位数计算。
-
计算分位数:对于每个数据点,计算其在整个数据集中的百分位排名,通常使用累积分布函数(CDF)来计算。这些分位数值表示了数据点在整个分布中的相对位置。
-
生成理论分位数:根据选择的理论分布(例如正态分布),计算与相同百分位排名对应的理论分位数。这些理论分位数是从理论分布中得到的,如果数据符合该理论分布,它们应该服从相同的分布。
-
绘制Q-Q图:将实际数据的分位数和理论分布的分位数绘制成散点图。通常,x轴表示理论分位数,y轴表示实际数据的分位数。如果数据近似符合理论分布,散点应该大致沿着一条45度对角线排列。
-
解释结果:观察Q-Q图上的点的分布。如果它们紧密地沿着45度对角线排列,那么数据很可能符合所选择的理论分布。如果点偏离对角线,可能表示数据不符合理论分布。
Q-Q图是一种强大的工具,可以帮助你直观地评估数据的分布特征,并检查数据是否近似符合理论分布,如正态分布。如果点在Q-Q图上紧密地沿着一条直线排列,这是一个很好的迹象,表明数据与所选择的理论分布相符。 scipy.stats.probplot 函数用于创建概率图(probability plot),用于可视化样本数据与理论分布(通常是正态分布)之间的拟合程度。这有助于你判断样本数据是否符合某个特定的理论分布。
import numpy as np
import matplotlib.pyplot as plt
import scipy.stats as stats
# 生成一些模拟身高数据(正态分布)
# 假设你有一个包含100个身高观测值的数据集,你想要检查这些身高数据是否符合正态分布
np.random.seed(0)
heights = np.random.normal(loc=170, scale=10, size=100)
# 绘制Q-Q图
stats.probplot(heights, dist="norm", plot=plt)
plt.title("Q-Q Plot for Heights")
plt.xlabel("Theoretical Quantiles")
plt.ylabel("Sample Quantiles")
plt.show()

要绘制Q-Q图并比较实际数据的分位数与理论正态分布的分位数,首先需要计算这些分位数。分位数表示数据集中某个特定百分比的值。通常使用累积分布函数(CDF)来计算分位数。对于正态分布,可以使用以下方法计算分位数:
-
计算理论正态分布的分位数:
- 对于给定的概率(百分比)p(例如,p=0.25表示25%分位数,即下四分位数),可以使用正态分布的累积分布函数(CDF)计算相应的分位数。这通常使用统计软件或库来完成,因为它涉及到高级数学计算。
-
计算实际数据的分位数:
- 对于你的实际数据集,需要将数据从小到大排序。
- 然后,使用以下公式计算每个数据点的分位数: 分位数 = ((i - 0.5)/ n) * 100% 其中,i 是数据点在排序后的位置,n 是数据集中的总数据点数。
-
绘制Q-Q图:文章来源:https://www.toymoban.com/news/detail-722845.html
- 现在你有了理论正态分布和实际数据的分位数,可以将它们绘制在Q-Q图上。
- x轴表示理论正态分布的分位数,y轴表示实际数据的分位数。
- 如果数据点紧密地沿着一条对角线分布,那么数据可能符合正态分布。
我们使用NumPy生成一个示例数据集,假设它服从正态分布。然后,我们计算实际数据和理论正态分布的分位数,并使用matplotlib和seaborn库绘制Q-Q图。Q-Q图用于可视化实际数据和理论分布之间的拟合程度。如果数据点紧密地沿着红色虚线分布,表示数据接近正态分布。文章来源地址https://www.toymoban.com/news/detail-722845.html
import numpy as np
import scipy.stats as stats
import matplotlib.pyplot as plt
import seaborn as sns
# 生成一个示例数据集,假设服从正态分布
data = np.random.normal(loc=0, scale=1, size=1000)
# 计算实际数据的分位数
percentiles = np.percentile(data, [0, 25, 50, 75, 100])
# 计算理论正态分布的分位数
theoretical_percentiles = stats.norm.ppf([0, 0.25, 0.5, 0.75, 1], loc=0, scale=1)
# 绘制Q-Q图
plt.figure(figsize=(8, 6))
sns.set(style="whitegrid")
sns.scatterplot(x=theoretical_percentiles, y=percentiles)
plt.xlabel("Theoretical Quantiles")
plt.ylabel("Sample Quantiles")
plt.title("Q-Q Plot")
plt.plot([-2, 2], [-2, 2], color='red', linestyle='--') # 添加对角线
plt.show()
到了这里,关于正态分布的概率密度函数|多种正态分布检验|Q-Q图的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!