本文是按照自己的理解进行笔记总结,如有不正确的地方,还望大佬多多指点纠正,勿喷。
课程内容:
1、中小公司Redis缓存架构以及线上问题分析
2、大厂线上大规模商品缓存数据冷热分离实战
3、实战解决大规模缓存击穿导致线上数据库压力暴增
4、黑客攻击导致缓存穿透线上数据库宕机Bug
5、一行代码解决线上缓存穿透问题
6、一次大V直播带货导致线上商品系统崩溃原因分析
7、突发性热点缓存重建导致系统压力暴增问题分析
8、基于DCL机制解决热点缓存并发重建问题实战
9、Redis分布式锁解决缓存与数据库双写不一致问题实战
10、大促压力暴增导致分布式锁串行争用问题优化实战
11、一次微博明星热点事件导致系统崩溃原因分析
12、利用多级缓存架构解决Redis线上集群缓存雪崩问题
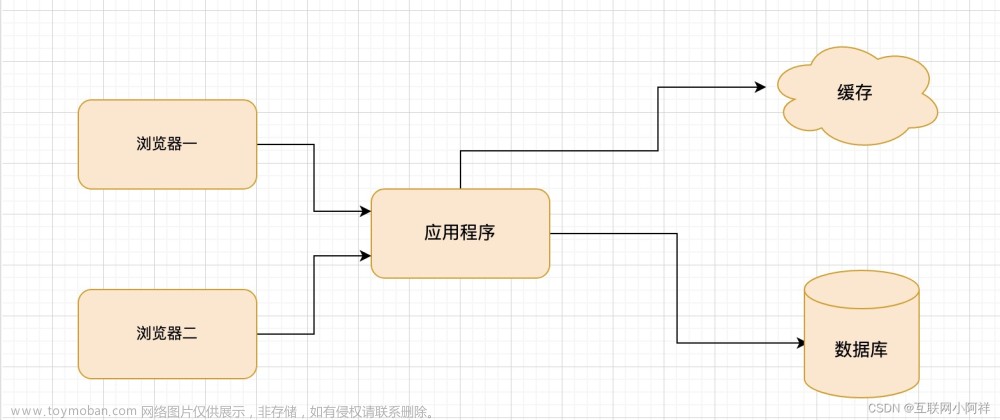
1. 冷热数据分离
我们建议放缓存的地方都加一个超时时间,只需要对热点数据进行缓存,一些其他的冷门的数据就不用放到缓存里面占用时间了。
如果对于每天都有访问的数据就一直放在缓存里面,对于那些数据每查询一次可以加一点缓存超时延期。也就是读延期。这样以来那些有人访问的数据会一直在缓存里面,而那些没人访问的数据达到缓存的设定时间,就会从缓存里面移除。这样以来就做到了数据的冷热分离
2. 缓存设计
2.1 缓存击穿(失效)
由于大批量缓存在同一时间失效可能导致大量请求同时穿透缓存直达数据库,可能会造成数据库瞬间压力过大甚至挂掉,对于这种情况我们在批量增加缓存时最好将这一批数据的缓存过期时间设置为一个时间段内的不同时间。
如果商品上架或者更新商品,有那这批量更新、批量导入的。对商品进行批量操作,那商品的失效时间是一样的,同时过期。结果都没有缓存了,结果又有大量的请求。就是缓存里面没有了,但是数据库里面还有。
示例伪代码:
这个问题怎么解决呢?
那么我们可以把设置的超时时间设置成随机时间,在原来超时时间的基础上加一个随机数。
2.2 缓存穿透
缓存穿透是指查询一个根本不存在的数据,缓存层和存储层都不会命中,通常出于容错的考虑,如果从存储层查不到数据则不写入缓存层。
第一种情况:就是比如商品上架之后,一不小心把他彻底删除了,这样删除之后导致数据库以及缓存里面都没有了这个数据。结果后端数据全部没有了,而前端还一直有高并发的数据一直过来,导致大量的请求过来查数据库没有,查缓存也没有,这样一来缓存以及数据库的压力都比较大,特别是数据库。这个就叫做缓存穿透,有一个“透”字,就是把整个后端全部穿透了。
还有一种情况,就是如果是大型互联网,每天都有黑客来攻击你,假如他知道了你这个玩也链接中的数字就是你商品的id,那这个时候别人就可以攻击了,就是造一堆商品不存在的id,然后就用压测的软件去大量请求这个不存在商品,DDoS攻击,这样就会把数据层全部打穿、穿透。
缓存穿透将导致不存在的数据每次请求都要到存储层去查询,失去了缓存保护后端存储的意义。
造成缓存穿透的基本原因有两个:
第一,自身业务代码或者数据出现问题。
第二,一些恶意攻击、爬虫等造成大量空命中。缓存穿透问题解决方案:
那么这样的缓存穿透怎么解决呢?
可以设置一个空缓存。或者我们给一个特殊的标志,为了加以区分其他的情况,可以设置一个“{}”这样的空缓存。
这样看来是解决了黑客的攻击问题,但是如果有些黑客比较聪明,他不是拿一个商品攻击你,他每次都换着id去请求,一个数据库中有成千上万个空数据,那这样就会导致生成成千上万个空“{}”的缓存,又达到了攻击,那怎么解决呢?
过期,设置过期时间。空缓存可以设置几分钟过期之类的。如果他一直使用同一个商品,我们也可以设置一个商品的读延期时间。延期缓存就延期一两分钟的样子可以。
2.3 缓存雪崩
缓存雪崩指的是缓存层支撑不住或宕掉后,流量会像奔逃的野牛一样,打向后端存储层。
由于缓存层承载着大量请求,有效地保护了存储层,但是如果缓存层由于某些原因不能提供服务(比如超大并发过来,缓存层支撑不住,或者由于缓存设计不好,类似大量请求访问bigkey,导致缓存能支撑的并发急剧下降),于是大量请求都会打到存储层,存储层的调用量会暴增,造成存储层也会级联宕机的情况。
预防和解决缓存雪崩问题,可以从以下三个方面进行着手。
- 保证缓存层服务高可用性,比如使用Redis Sentinel或Redis Cl
uster。 - 依赖隔离组件为后端限流熔断并降级。比如使用Sentinel或Hystrix限流降级组件。
比如服务降级,我们可以针对不同的数据采取不同的处理方式。当业务应用访问的是非核心数据(例如电商商品属性,用户信息等)时,暂时停止从缓存中查询这些数据,而是直接返回预定义的默认降级信息、空值或是错误提示信息;当业务应用访问的是核心数据(例如电商商品库存)时,仍然允许查询缓存,如果缓存缺失,也可以继续通过数据库读取。 - 提前演练。在项目上线前,演练缓存层宕掉后,应用以及后端的负载情况以及可能出现的问题,在此基础上做一些预案设定。
3. 大V直播带货导致线上商品系统崩溃原因分析
像一些特别大的直播带货主播可能会上一些非常冷门的商品,就是之前根本没有买的商品,也没有访问的商品。但是当这些大主播们在直播间让大家抢这些商品的时候,可能一下几百万人去请求这个商品,但是这个商品在缓存里面没有,因为他是冷门的商品嘛。
假设现在一下有几万个请求来调用这个方法,然后查缓存是没有的,这个时候就会走到数据库这边来。但是数据的抗压能力很弱的。不过这个是小概率事件,因为可能这个冷门的商品在上架之前先进行访问就会缓存起来,我们不考虑这种情况,我们就考虑这种小概率的事件,就是这个冷门的商品缓存失效了,然后又有很多人来访问,现在就会压力全给到数据库,数据库承受压力很小的,这样就会导致数据库可能会挂掉。这样就会防止这种情况的。
虽然是小概率事件,我们还是要规避的。这就是突发性热点缓存重建导致系统压力暴增问题
4. 突发性热点缓存重建导致系统压力暴增问题
这个问题怎么解决呢?
最简单的方式就是加锁。就是单例模式里面有一个DCL(Double Check Lock)双重检测锁。这个就可以解决这个问题。
就是双重查询

对于那些突发性的热点缓存,并发重建的问题就解决了。一下来了几万条数据需要重建缓存,没关系,只有一个人能重建缓存。这个时候其他的请求就得等着这个重建缓存,但是等这个重建完成之后,进到这块代码的时候发现缓存里面有数据了,就不会再添加缓存了。
其实这样做还是回有问题,就是synchronized只在单节点内是有效的。如果这个是一个web应用的一个集群,用这个代码做的话,他的每个web服务器上都要重建一次,synchronized{this}中使用this肯定是不行的。就是比如101商品是在A的直播间里面加锁了,那么现在来了一个102商品在B直播间,是不是也阻塞住了,这样是不应该的,关键现在是不同的商品,现在因为一个商品会导致别的商品阻塞住。这个时候就可以使用分布式锁。把这个锁替换成分布式锁就得到了解决。分布式锁就是解决多节点间的并发问题。而且重建只需要建一次。



如果我们在开发的时候,开发着开发着发现里面的代码开始比较多了,且里面还有重复的,这个时候我们就可以重构一下:


这个时候仍然会有一个小问题
如果这个里面的数据是不存在的,然后里面放的是空缓存,但是我们这个时候返回的是null,再走到上面就会又去查数据库,这个时候是没必要的,因此需要区分一下。


5. 缓存数据库双写不一致问题
下面这两种情况全部都是缓存数据库双写不一致问题:


删除缓存同样也会有这样的问题

分布式锁就可以解决这个问题,

意思就是在一个线程操作的时候加上分布式锁即可

现在开始加锁

在更新、创建的地方都应该加这样的分布式锁,直接复制过去即可。
其实看着这样写了很多代码,会觉得在执行的时候效率很低。其实不是的,因为这个解决的是小概率事件,其中90%还是在缓存了就会读到。
其实在一些电商平台,基本上95%还是读操作,只有你加入购物车了或者是下单了才会涉及到写操作。也就是电商平台就是读多写少的问题,针对这个问题使用分布式锁去解决问题,可以借助分布式的读写锁优化,这种情况下可以借助分布式的读写锁redisson优化。读就加读锁,写就加写锁,因为写写会冲突,读写会冲突,但是读读是不会有冲突的。
如果现在大家伙都在读,在加读锁的时候是互相不冲突的,大家都可以进行读。也就是并行执行。秒杀之前大家都是读,都去并发执行,效率是很高的,也就那1s时间是有写读或者写写共存的情况。

- 第一句代码使用 Redisson 的 getReadWriteLock() 方法获取了一个名为 LOCK_PRODUCT_UPDATE_PREFIX + productId 的读写锁 productUpdateLock,用于保证对 productId 对应的数据的读写操作是互斥的。
- 第二句代码通过 productUpdateLock 的 writeLock() 方法获取了一个写入锁 writeLock,用于保证对 productId 对应的数据的写操作是互斥的。
- 第三句代码使用 writeLock 的 lock() 方法获取了写入锁,并阻塞当前线程,直到获取到锁为止。然后,该线程可以执行对 productId 对应数据的写操作。
这把读写锁,这个锁的key必须是一样的。
下面是读锁的底层源码:

如果第一个线程是写锁,现在来了一个线程,首先判断这个锁的模式,如果是读锁,那就把这个在写锁上加1,如果是写锁你就在这等着。
分布式锁有很多的优化场景,要根据不同的场景使用不同的锁。
下面这块应该使用不了读写锁优化,那么应该怎么来进行优化。

假如我们知道有99.99%的线程会在1s钟将这个方法里面的所有的步骤执行完,因此这个时候串行就可以转成并行

就是我等1s时间,如果我还加不上锁我就走了,返回方法。
package com.hs.distributlock.service;
import com.alibaba.fastjson.JSON;
import com.hs.distributlock.entity.ProductEntity;
import com.hs.distributlock.mapper.ProductMapper;
import org.redisson.Redisson;
import org.redisson.api.RLock;
import org.redisson.api.RReadWriteLock;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Service;
import org.springframework.util.StringUtils;
import java.util.Objects;
import java.util.Random;
import java.util.concurrent.TimeUnit;
/**
* @Description: 高并发缓存架构
* @Author 胡尚
* @Date: 2023/3/25 20:10
*/
@Service
public class ProductService {
@Autowired
StringRedisTemplate redisTemplate;
@Autowired
Redisson redisson;
@Autowired
ProductMapper productMapper;
/**
* 缓存穿透默认值
*/
public static final String PRODUCT_PENETRATE_DEFAULT = "{}";
/**
* 突发性热点缓存重建时加的锁
*/
public static final String LOCK_PRODUCT_HOT_CACHE_CREATE_PREFIX = "lock:product:hot_cache_create:";
/**
* 突发性热点缓存重建时加的锁
*/
public static final String LOCK_CACHE_DB_UNLIKE_PREFIX = "lock:cache_db_unlike:";
public void updateProduct(ProductEntity entity){
// 解决缓存与数据库双写 数据不一致问题 而加写锁
RReadWriteLock readWriteLock = redisson.getReadWriteLock(LOCK_CACHE_DB_UNLIKE_PREFIX + entity.getId());
RLock wLock = readWriteLock.writeLock();
wLock.lock();
try {
// 更新DB 更新缓存
productMapper.update(entity);
String json = JSON.toJSONString(entity);
redisTemplate.opsForValue().set("product:id:" + entity.getId(), json, 12*60*60+getRandomTime(), TimeUnit.SECONDS);
}finally {
wLock.unlock();
}
}
public void insertProduct(ProductEntity entity){
// 解决缓存与数据库双写 数据不一致问题 而加写锁
RReadWriteLock readWriteLock = redisson.getReadWriteLock(LOCK_CACHE_DB_UNLIKE_PREFIX + entity.getId());
RLock wLock = readWriteLock.writeLock();
wLock.lock();
try {
// 更新DB 更新缓存
productMapper.insert(entity);
String json = JSON.toJSONString(entity);
redisTemplate.opsForValue().set("product:id:" + entity.getId(), json, 12*60*60+getRandomTime(), TimeUnit.SECONDS);
}finally {
wLock.unlock();
}
}
/**
* 重点方法,这其中使用了双重检测去查询缓存,还加了读锁去解决缓存和数据库双写导致的数据不一致问题
*/
public ProductEntity queryProduct(Long id) throws InterruptedException {
String productKey = "product:id:" + id;
// 从缓存取数据
ProductEntity entity = queryCache(productKey);
if (entity != null){
return entity;
}
// 突发性热点缓存重建问题,避免大量请求直接去请求DB,进而加锁拦截
RLock lock = redisson.getLock(LOCK_PRODUCT_HOT_CACHE_CREATE_PREFIX + id);
lock.tryLock(3, 30, TimeUnit.SECONDS);
try {
// 第二次验证 从缓存取数据
entity = queryCache(productKey);
if (entity != null){
return entity;
}
// 缓存与DB数据双写不一致问题 加锁
RReadWriteLock readWriteLock = redisson.getReadWriteLock(LOCK_CACHE_DB_UNLIKE_PREFIX + id);
RLock rLock = readWriteLock.readLock();
rLock.lock();
try {
// 查询数据库 更新缓存
entity = queryDatabase(productKey, id);
}finally {
rLock.unlock();
}
}finally {
lock.unlock();
}
return entity;
}
/**
* 从缓存中查询
*/
private ProductEntity queryCache(String key){
ProductEntity entity = null;
String json = redisTemplate.opsForValue().get(key);
if (StringUtils.hasLength(json)){
// 判断是否为解决缓存穿透而手动存储的值,如果是则直接返回一个新对象,并和前端约定好错误提示
if (Objects.equals(PRODUCT_PENETRATE_DEFAULT, json)){
return new ProductEntity();
}
entity = JSON.parseObject(json, ProductEntity.class);
// 延期
redisTemplate.expire(key, 12*60*60+getRandomTime(), TimeUnit.SECONDS);
}
return entity;
}
/**
* 从数据库中查询,如果查询到了就将数据在缓存中保存一份,如果没有查询到则往缓存中存一个默认值来解决缓存击穿问题
*/
private ProductEntity queryDatabase(String productKey, long id){
ProductEntity entity = productMapper.get(id);
// 如果数据库中也没有查询到,那么就往缓存中存一个默认值,去解决缓存击穿问题
if (entity == null){
redisTemplate.opsForValue().set(productKey, PRODUCT_PENETRATE_DEFAULT, 60*1000, TimeUnit.SECONDS);
} else {
redisTemplate.opsForValue().set(productKey, JSON.toJSONString(entity), 12*60*60+getRandomTime(), TimeUnit.SECONDS);
}
return entity;
}
private Integer getRandomTime(){
return new Random().nextInt(5) * 60 * 60;
}
}
在这段代码中,使用了Redisson提供的分布式锁来解决缓存和数据库双写导致的数据不一致问题。具体来说,使用了Redisson提供的读写锁(RReadWriteLock)来对缓存和数据库进行加锁。
在updateProduct和insertProduct方法中,首先获取了一个写锁(RReadWriteLock.writeLock())wLock,然后使用wLock.lock()方法获取锁并阻塞当前线程,直到获取到锁为止。在获取到锁之后,更新了数据库中的数据,然后更新了缓存中的数据,最后释放锁,以便其他线程能够获取锁并进行操作。
在queryProduct方法中,首先从缓存中查询数据,如果缓存中不存在,则使用Redisson提供的分布式锁(RLock)来解决突发性热点缓存重建问题。具体来说,使用redisson.getLock(LOCK_PRODUCT_HOT_CACHE_CREATE_PREFIX + id)获取一个名为LOCK_PRODUCT_HOT_CACHE_CREATE_PREFIX + id的锁lock,然后使用lock.tryLock(3, 30, TimeUnit.SECONDS)方法获取锁并阻塞当前线程,直到获取到锁为止。在获取到锁之后,再次从缓存中查询数据,如果缓存中不存在,则使用Redisson提供的读写锁(RReadWriteLock)来对缓存和数据库进行加锁。
具体来说,使用redisson.getReadWriteLock(LOCK_CACHE_DB_UNLIKE_PREFIX + id)获取一个名为LOCK_CACHE_DB_UNLIKE_PREFIX + id的读写锁readWriteLock,然后使用readWriteLock.readLock()获取一个读锁rLock,使用rLock.lock()方法获取锁并阻塞当前线程,直到获取到锁为止。在获取到读锁之后,查询数据库并更新缓存中的数据,最后释放读锁,以便其他线程能够获取锁并进行操作。最后,释放热点缓存重建锁,以便其他线程能够获取锁并进行操作。
需要注意的是,获取锁后必须执行对应的解锁操作,以便其他线程能够获取锁并进行操作。在上述代码示例中,使用了try-finally语句块来确保锁的释放。这样,即使在执行操作时抛出异常,也能够保证锁会被正确释放。
6. 一次微博明星热点事件导致系统崩溃原因分析
可能同时上百万的人访问,一个单个节点redis就是再缓存大概能支持10万个,因此redis可能也扛不住,redis扛不住,web请求可能就会报错。
也就是缓存雪崩文章来源:https://www.toymoban.com/news/detail-723012.html
针对这种问题我们可以限流。这个即使前端代码层已经有限流,也要在后端也进行限流。万一前端没有限流成功,后端可以。也就是多加一级缓存,也就是多级缓存架构。文章来源地址https://www.toymoban.com/news/detail-723012.html
到了这里,关于5. 一线大厂高并发缓存架构实战与性能优化的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!