python+Selenium登录报错
错误信息:InvalidCookieDomainException: invalid cookie domain: Cookie 'domain' mismatch (Session info: MicrosoftEdge=110.0.1587.46)
原代码:文章来源:https://www.toymoban.com/news/detail-723069.html
def login(url,cookies):
driver.get(url)
time.sleep(6)
driver.delete_all_cookies()
for cookie in cookies:
driver.add_cookie(cookie)
driver.get(url)
driver.refresh()
if __name__ == '__main__':
url = 'https://www.******.com/'
cookies = json.load(open('cookies.json','r'))
driver = webdriver.Edge()
driver.maximize_window()
login(url=url, cookies=cookies)
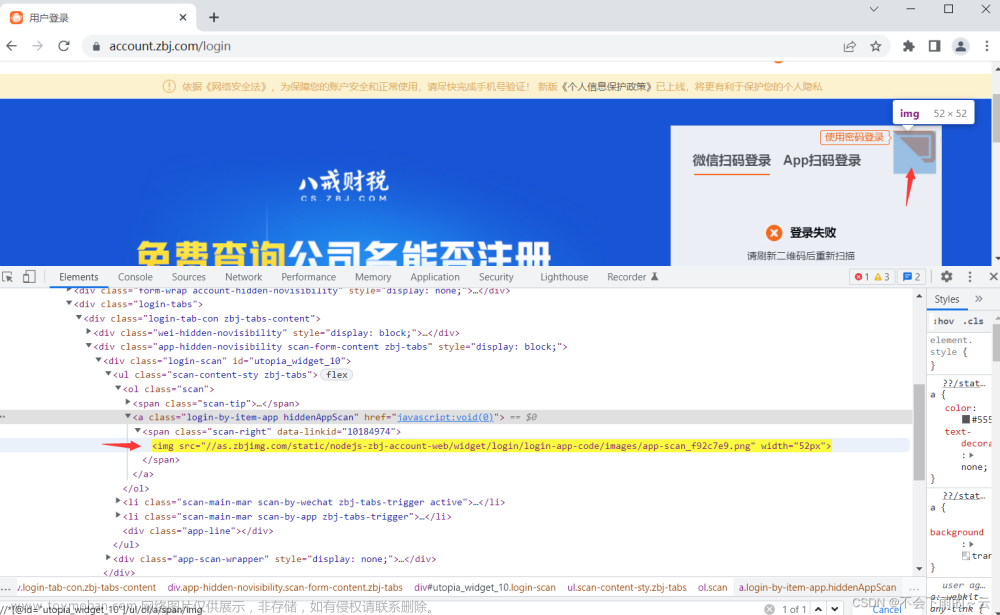
原因: 请看下图的domain:遮挡部分一致,但前面有的有www.,有的没有:
解决办法:修改不一样的domain,具体以哪个为主需视情况而定。修改后的代码(def部分不变):文章来源地址https://www.toymoban.com/news/detail-723069.html
if __name__ == '__main__':
url = 'https://www.*****.com/'
cookies = json.load(open('cookies.json','r'))
for cookie in cookies:
cookie['domain']='.*****.com' # 区别在这儿
driver = webdriver.Edge()
driver.maximize_window()
login(url=url, cookies=cookies)
到了这里,关于python+Selenium模拟登录报错:`InvalidCookieDomainException`的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!