原创 | 文 BFT机器人

01
背景
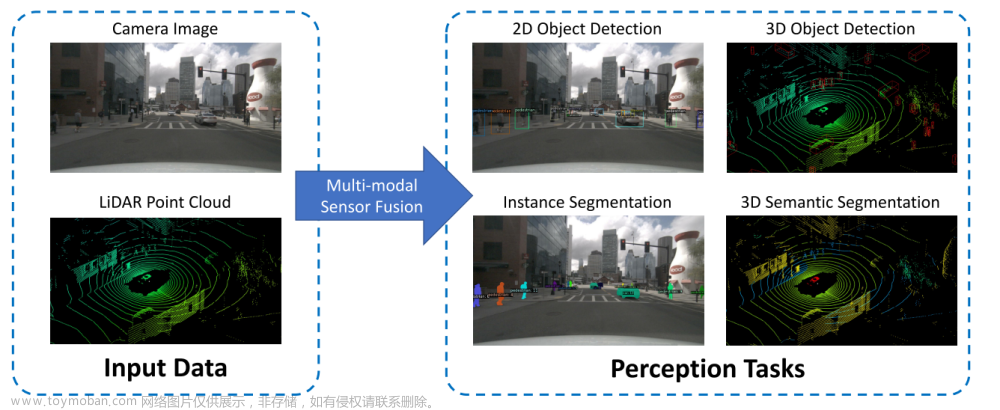
多视角三维物体检测网络,用于实现自动驾驶场景高精度三维目标检测,该网络使用激光雷达点云和RGB图像进行感知融合,以预测定向的三维边界框,相比于现有技术,取得了显著的精度提升。同时现代自动驾驶汽车通常配备多个传感器,如雷达和相机,激光扫描仪具有精确的深度信息,而相机保留了更详细的语义信息,激光雷达点云和RGB图像的融合应该能够实现更高的性能和安全性。本文提出并设计了一个深度融合方案结合多视图的区域特征,实现不同路径的中间层交互。
02
理论研究
在本文中提出的一种多视点三维物体检测网络(MV3D),该网络以多模态数据为输入,并预测了三维空间中物体的全三维范围。利用多模态信息的主要思想是进行基于区域的特征融合。首先提出了一种多视图编码方案,以获得稀疏三维点云的紧凑有效表示。三维提案网络利用点云的鸟瞰图表示来生成高精度的三维候选框。3D对象建议的好处是它可以投影到三维空间的任何视图中。多视图融合网络通过将三维建议从多个视图投影到特征图上来提取区域特征。深度融合的方法使得来自不同视图的中间层能够进行交互。本文在采用多视图特征表示的情况下,该网络进行定向三维盒回归,可以准确地预测三维空间中物体的三维位置、大小和方向。

图1 多视点三维目标检测网络
图像中的三维对象检测,是基于图像的方法通常依赖于精确的深度估计或地标检测。我们的工作展示了如何合并激光雷达点云来改进三维定位。并且在自动驾驶的环境中,利用多种数据模式的工作很少,我们的网络与它们不同,它对每个列使用相同的基础网络,并添加辅助路径和损失进行正则化。

图2 MV3D网络中输入的图片
对于MV3D网络,文中介绍了如何从鸟瞰图表示的点云中高效地生成3D物体候选框。不仅使用了一个基于卷积神经网络的物体候选框生成器,该生成器可以从鸟瞰图中提取出物体的候选框。
为了提高检测精度,还使用了一种基于锚的方法,即将一些预定义的3D 锚框与鸟瞰图中的像素点对应起来,从而生成更加准确的物体候选框。此外,为了解决物体候选框过小的问题,作者还使用了特征图上采样的方法,将特征图的分辨率提高一倍,从而使得物体候选框更加准确。同时也介绍了如何将来自多个视角的特征进行融合,以提高物体检测的精度和鲁棒性。具体来说,文中使用了一种深度融合方案,即将来自不同视角的特征进行逐层融合,从而使得网络可以更好地利用多视角信息。
此外,为了增强不同路径之间的交互,作者还使用了一种特殊的跨路径连接方式,即将不同路径的中间层进行交互,从而使得网络可以更好地利用不同路径之间的信息。

图3 本文提出的基于区域的融合网络的训练策略
03
实验与分析
本文提出的方法在基于激光雷达的2D检测方法中,在硬设置中比最近提出的Vote3Deep方法高出14.93%的精度。然而,值得注意的是,在2D检测方面,基于图像的方法通常比基于激光雷达的方法表现更好,因为它们直接优化2D盒子,而基于雷达的方法优化3D盒子。尽管如此,与最先进的二维检测方法相比,文章中的方法仍然获得了有竞争力的结果。


图4 实验模型在KITTI数据集上的检测和消融实验结果比较
文中提出设计为稳健而高效,可以处理复杂的场景,如遮挡和杂乱的环境,这种用于道路场景中三维目标检测的多视角感觉融合模型。我们的模型同时利用了激光雷达点云和图像,通过生成三维提案并将它们投影到多个视图中以进行特征提取来对齐不同的模式。总体而言,本文中的自动驾驶多视角三维物体检测网络是提高自动驾驶场景下物体检测精度和鲁棒性的有前途的方法。
END
作者 | 小雨点
排版 | 小河
审核 | 猫文章来源:https://www.toymoban.com/news/detail-723158.html
若您对该文章内容有任何疑问,请与我们联系,我们将及时回应。文章来源地址https://www.toymoban.com/news/detail-723158.html
到了这里,关于解读 | 自动驾驶系统中的多视点三维目标检测网络的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!