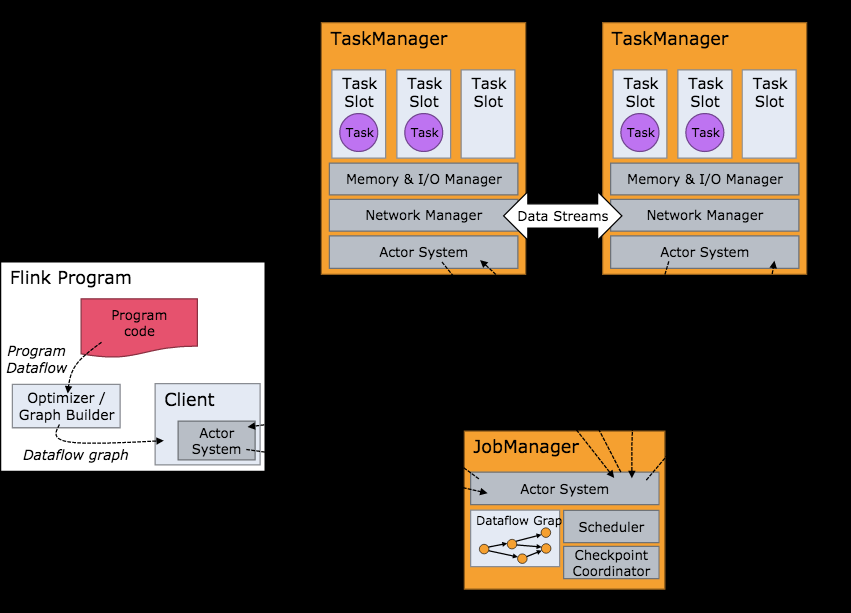
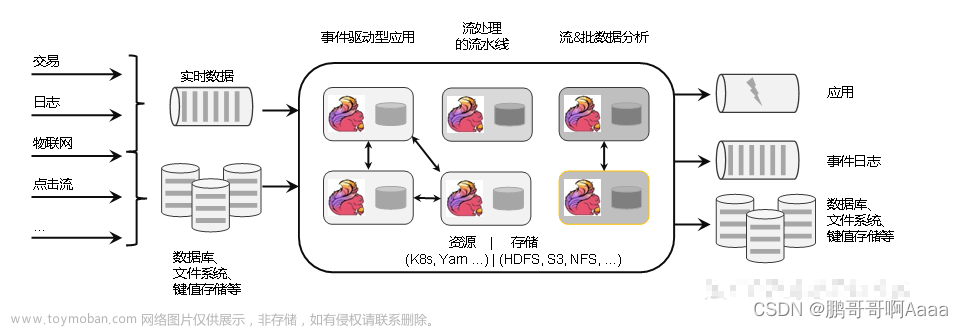
1.5 流处理基础概念
在某些场景下,流处理打破了批处理的一些局限。Flink作为一款以流处理见长的大数据引擎,相比其他流处理引擎具有众多优势。本节将对流处理的一些基本概念进行细化,这些概念是入门流处理的必备基础,至此你将正式进入数据流的世界。
1.5.1 延迟和吞吐
在批处理场景中,我们主要通过一次计算的总耗时来评价性能。在流处理场景,数据源源不断地流入系统,大数据框架对每个数据的处理越快越好,大数据框架能处理的数据量越大越好。例如1.2.3小节中提到的股票交易案例,如果系统只能处理一两只股票或处理时间长达一天,那么说明这个系统非常不靠谱。衡量流处理的“快”和“量”两方面的性能,一般用延迟(Latency)和吞吐(Throughput)这两个指标。文章来源:https://www.toymoban.com/news/detail-723343.html
1.延迟
延迟表示一个事件被系统处理的总时间,一般以毫秒为单位。根据业务不同,我们一般关心平均延迟(Average Latency)和分位延迟(Percentile Latency)。假设一个食堂的自助取餐流水线是一个流处理系统,每个就餐者前来就餐是它需要处理的事件,从就餐者到达食堂到他拿到所需菜品并付费离开的总耗时,就是这个就餐者的延迟。如果正赶上午餐高峰期,就餐者极有可能排队,这个排队时间也要算在延迟中。例如,99分位延迟表示对所有就餐者的延迟进行统计和排名,取排名第99%位的就餐者延迟。一般商业系统更关注分位延迟,因为分位延迟比平均延迟更能反映这个系统的一些潜在问题。还是以食堂的自助餐流水线为例,该流水线的平均延迟可能不高,但是在就餐高峰期,延迟一般会比较高。如果延迟过高,部分就餐者会因为等待时间过长而放弃排队,用文章来源地址https://www.toymoban.com/news/detail-723343.html
到了这里,关于浅谈大数据之Flink-2的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!