目录
扫描输入(Scanner)
Scanner的分隔符
使用正则表达式扫描
StringTokenizer
本笔记参考自: 《On Java 中文版》
扫描输入(Scanner)
先看看在Scanner类加入之前,Java是如何处理文件或标准输入的:
【例子:老版本的文本处理】
import java.io.BufferedReader;
import java.io.IOException;
import java.io.StringReader;
public class SimpleRead {
public static BufferedReader input =
new BufferedReader(new StringReader(
"小红 \n22 1.4514"));
public static void main(String[] args) {
try {
System.out.println("你的名字是什么?");
String name = input.readLine();
System.out.println(name);
System.out.println("你几岁了?" +
"你最喜欢的浮点数是多少?");
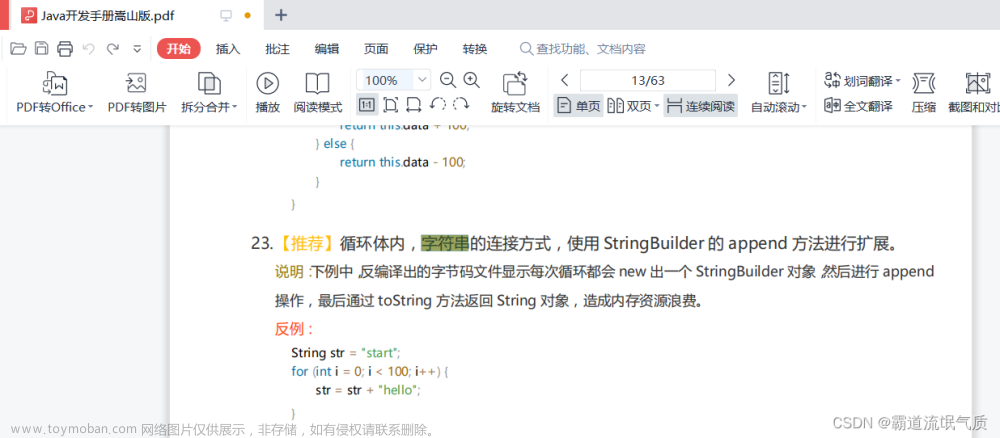
System.out.println("请输入:<年龄> <浮点数>");
String numbers = input.readLine();
System.out.println(numbers);
String[] numArray = numbers.split(" ");
int age = Integer.parseInt(numArray[0]);
double favorite = Double.parseDouble(numArray[1]);
System.out.format("你好,%s。%n", name);
System.out.format("5年后你就" + (age + 5) + "岁了。");
System.out.format("我最喜欢的浮点数是%f。", favorite / 2);
}catch (IOException e){
System.out.println("I/O exception");
}
}
}程序执行的结果是:

其中,用于接受输入的代码只有前几行:

内部的StirngReader用于将输入转换为一个可读的流对象,这一对象最终被储存在了BufferedReader对象中。当我们需要使用时,可以配合BufferReader的readLine()方法:

这种处理输入的方式在需要拆分输入时会变得尤为复杂(特别是在面对多行输入时):

我们需要先将输入拆分成各个元素,然后逐一处理它们。
Java 5的Scanner类减轻了处理输入的负担:
【例子:使用Scanner类处理输入文本】
import java.util.Scanner;
public class BetterRead {
public static void main(String[] args) {
Scanner stdin = new Scanner(SimpleRead.input);
System.out.println("你的名字是什么?");
String name = stdin.nextLine();
System.out.println(name);
System.out.println("你几岁了?" +
"你最喜欢的浮点数是多少?");
System.out.println("请输入:<年龄> <浮点数>");
int age = stdin.nextInt();
double favorite = stdin.nextDouble();
System.out.println(age + " " + favorite);
System.out.format("你好,%s。%n", name);
System.out.format("5年后你就" + (age + 5) + "岁了。");
System.out.format("我最喜欢的浮点数是%f。", favorite / 2);
}
}程序执行,输出和之前的例子一致:

Scanner类版本繁多的构造器允许我们输入任何参数,包括File、InputStream、String和Readable等。
另外,Scanner将输入、分词和解析这些操作都包含在了不同种类的“next”方法中。由于这些方法都只在输入流能够提供一个完整的数据分词时才进行返回,因此在不确定的情况下,可以使用对应的“hasNext”方法进行判断。
Scanner没有返回IOException,这是因为这个类默认IOException表示输入结束。但我们依旧可以使用它的ioException()方法查看最近发生的异常。
Scanner的分隔符
Scanner默认使用空格分割输入数据,但也可以使用正则表达式指定特殊的分隔符模式:
【例子:在Scanner中使用正则表达式】
import java.util.Scanner;
public class ScannerDelimiter {
public static void main(String[] args) {
Scanner scanner = new Scanner("12, 42, 78, 99, 42");
scanner.useDelimiter("\\s*,\\s*");
while (scanner.hasNextInt())
System.out.println(scanner.nextInt());
}
}程序执行的结果是:

这种处理方式同样适用于文件输入。
使用正则表达式扫描
Scanner允许我们自定义正则表达式模式进行扫描,这在面对复杂的数据时很有用。
【例子:扫描防火墙日志,提取威胁数据】
import java.util.Scanner;
import java.util.regex.MatchResult;
public class ThreatAnalyzer {
static String threatData =
"51.12.12.32@08/08/2015\n" +
"204.45.234.40@08/10/2015\n" +
"58.27.82.161@08/11/2015\n";
public static void main(String[] args) {
Scanner scanner = new Scanner(threatData);
String pattern = "(\\d+[.]\\d+[.]\\d+[.]\\d+)@" +
"(\\d{2}/\\d{2}/\\d{4})";
while (scanner.hasNext(pattern)) {
scanner.next(pattern);
MatchResult match = scanner.match();
String ip = match.group(1);
String date = match.group(2);
System.out.format(
"威胁:%s 来自 %s%n", date, ip);
}
}
}程序执行的结果是:

注意:由于这种模式只和下一个输入的分词进行匹配。因此在使用分隔符之前,需要注意是否与分词的格式相匹配。
StringTokenizer
在正则表达式(Java 1.4)和Scanner类(Java 5)被引入之前,Java中对字符串进行拆分的工作大多由StringTokenizer负责。因此这里简单对比不同的技术:
【例子:与StringTokenizer进行比较】
import java.util.Arrays;
import java.util.Scanner;
import java.util.StringTokenizer;
public class ReplacingStringTokenizer {
public static void main(String[] args) {
String input = "A B C D E F G";
StringTokenizer stoke = new StringTokenizer(input);
while (stoke.hasMoreElements())
System.out.print(stoke.nextToken() + " ");
System.out.println();
System.out.print(Arrays.toString(input.split(" ")));
System.out.println();
Scanner scanner = new Scanner(input);
while (scanner.hasNext())
System.out.print(scanner.next() + " ");
}
}程序执行的结果是:
 文章来源:https://www.toymoban.com/news/detail-723437.html
文章来源:https://www.toymoban.com/news/detail-723437.html
若要以更复杂的形式拆分字符串,StringTokenizer会显得更为乏力。因此StringTokenizer在现在逐渐被淘汰了。文章来源地址https://www.toymoban.com/news/detail-723437.html
到了这里,关于初识Java 16-3 字符串的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!