目录
案例需求
代码
结果
解析
案例需求:
使用netcat工具向9999端口不断的发送数据,通过SparkStreaming读取端口数据并统计不同单词出现的次数
-- 1. Spark从socket中获取数据:一行一行的获取
-- 2. Driver程序执行时,streaming处理过程不能结束
-- 3. 采集器在正常情况下启动后就不应该停止,除非特殊情况
-- 4. 采集器位于一个executor中,是一个线程,执行时需要一个核,如果设定的总核数为1时,那么在运行时因为没有核数,所以不会有打印结果,所以sparkStreaming使用的核数至少为2个
-- 5. print()方法,默认是打印10行结果
-- 6. netcat的指令:
在Windows下:nc -lp 9999
在linux下: nc -lk 9999代码:
package cn.olo.stream
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object StreamDemo {
def main(args: Array[String]): Unit = {
// 连接SparkStreaming
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkStreaming")
/*
1.方法:StreamingContext(形参)
2.形参:
形参1:conf: SparkConf:spark配置对象
形参2:batchDuration: Duration:采集时间
*/
val ssc = new StreamingContext(sparkConf,Seconds(5))
// 需求:使用netcat工具向9999端口不断的发送数据,通过SparkStreaming读取端口数据并统计不同单词出现的次数
// 1. 获取netcat工具9999端口的连接,并开始接收数据
// 从socket中获取数据:一行一行的获取
val socketDS: ReceiverInputDStream[String] = ssc.socketTextStream("localhost",9999)
// 2. 数据处理
val wordDS: DStream[String] = socketDS.flatMap(_.split(" "))
val wordToSumDS: DStream[(String, Int)] = wordDS.map((_,1)).reduceByKey(_ + _ )
// 3. 打印数据
wordToSumDS.print()
// 4. Driver程序执行时,streaming处理过程不能结束
// 采集器在正常情况下启动后就不应该停止,除非特殊情况
// 启动采集器
ssc.start()
// 等待采集器的结束
ssc.awaitTermination()
}
}
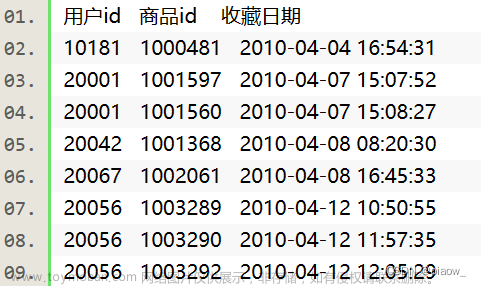
结果:

 文章来源:https://www.toymoban.com/news/detail-723494.html
文章来源:https://www.toymoban.com/news/detail-723494.html
解析:
a、采集周期时间之间,每一个采集周期生成一个RDD,按照时间的顺序依次进行
b、在每一个采集周期内,会执行wordcount计算,最终得出:统计出每一个采集周期时间的wordcount文章来源地址https://www.toymoban.com/news/detail-723494.html
到了这里,关于spark stream入门案例:netcat准实时处理wordCount(scala 编程)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!