1. 初识 ElasticSearch
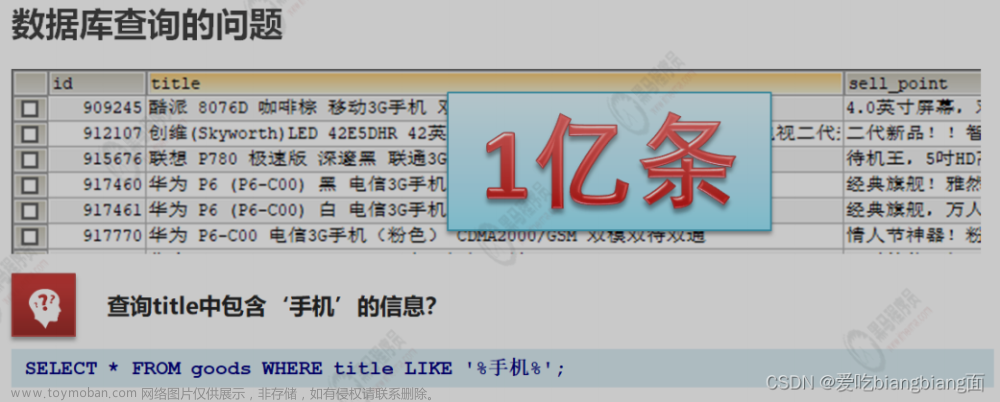
传统数据库查询的问题:如果使用模糊查询,左边有通配符,不会走索引,全表扫描,效率比较慢
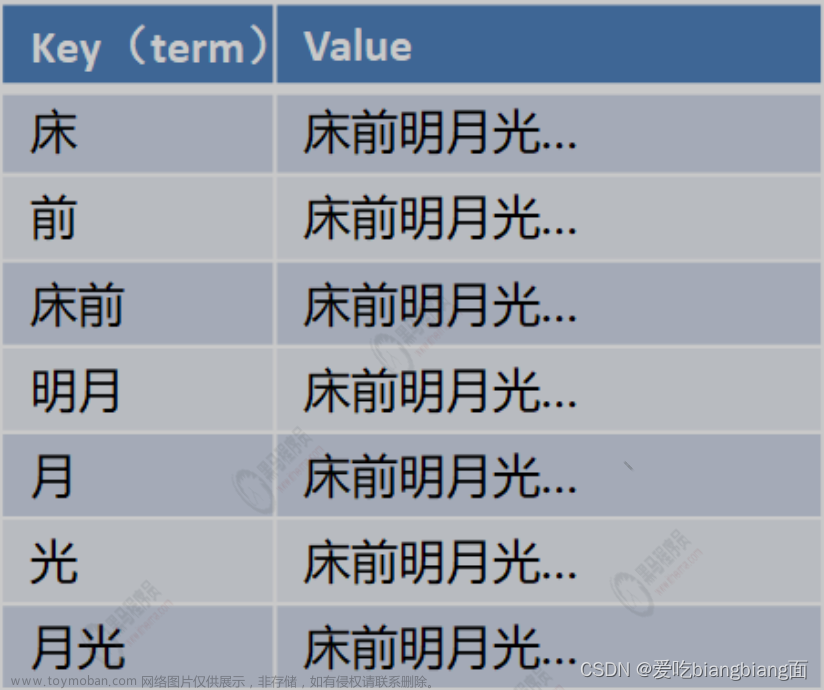
倒排索引
将文档进行分词,形成词条和
id
的对应关系即为反向索引。
以唐诗为例,所处包含
“
前
”
的诗句
正向索引:由《静夜思》
-->
窗前明月光
--->“
前
”
字
反向索引:
“
前
”
字
-->
窗前明月光
-->
《静夜思》
反向索引的实现就是对诗句进行分词,分成单个的词,由词推据,即为反向索引
“
床前明月光
”-->
分词
将一段文本按照一定的规则,拆分为不同的词条(
term
)
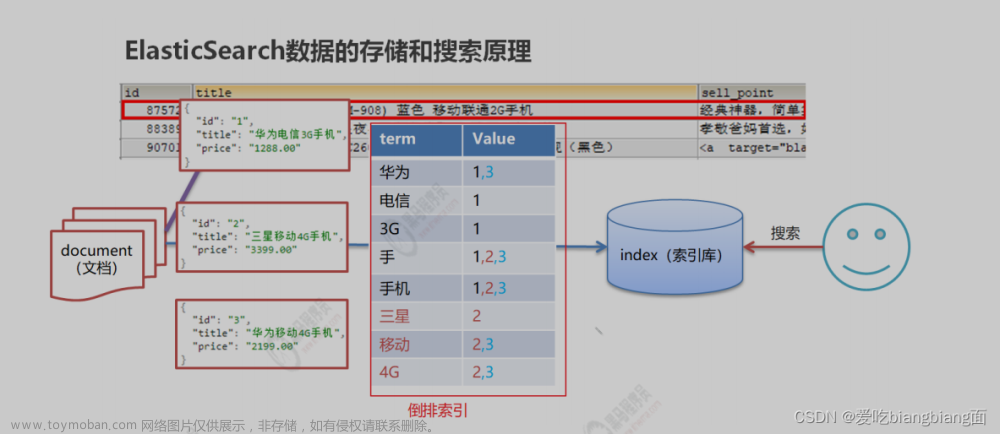
ES存储和查询的原理
es的存储结构:
index(索引) :相当于 mysql的表映射:相当于 mysql 的表结构document(文档 ) :相当于 mysql的表中的数据
Es查询:
使用倒排索引,对
title
进行分词
ES概念详解
•ElasticSearch 是一个基于 Lucene 的搜索服务器• 是一个分布式、高扩展、高实时的搜索与数据分析引擎• 基于 RESTful web 接口•Elasticsearch 是用 Java 语言开发的,并作为 Apache 许可条款下的开放源码发布,是一种流 行的企业级搜索引擎• 官网: https://www.elastic.co/应用场景• 搜索:海量数据的查询• 日志数据分析• 实时数据分析
2. 安装 ElasticSearch
https://download.csdn.net/download/weixin_44680802/88362801?spm=1001.2014.3001.5503https://download.csdn.net/download/weixin_44680802/88362801?spm=1001.2014.3001.5503
3. ElasticSearch 核心概念
索引(index)
ElasticSearch
存储数据的地方,可以理解成关系型数据库中的表。
映射(
mapping
)
mapping
定义了每个字段的类型、字段所使用的分词器等。相当于关系型数据库中的表结构。
文档(
document
)
Elasticsearch
中的最小数据单元,常以
json
格式显示。一个
document
相当于关系型数据库中的一行数据。
倒排索引
一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,对应一个包含它的文档
id
列表。
类型(
type
)
在
Elasticsearch7.X
默认
type
为
_doc
\- ES 5.x 中一个 index 可以有多种 type 。\- ES 6.x 中一个 index 只能有一种 type 。\- ES 7.x 以后,将逐步移除 type 这个概念,现在的操作已经不再使用,默认 _doc
4. 操作 ElasticSearch
RESTful
风格介绍
1.RESTful(Representational State Transfer
),表述性状态转移,是一组架构约束条件和原则。满足这些约束条件和原则的应用程序或设计就是RESTful
。就是一种定义接口的规范。
2.
基于
HTTP
。
3.
使用
XML
格式定义或
JSON
格式定义。
4.
每一个
URI
代表
1
种资源。
5.
客户端使用
GET
、
POST
、
PUT
、
DELETE 4
个表示操作方式的动词对服务端资源进行操作:
GET
:用来获取资源
POST
:用来新建资源(也可以用于更新资源)
PUT
:用来更新资源
DELETE
:用来删除资源
操作索引
新增
put http://ip: 端口/索引名称 #这里确实是put,不是post
查询
GET http://ip: 端口 / 索引名称 # 查询单个索引信息GET http://ip: 端口 / 索引名称 1, 索引名称 2... # 查询多个索引信息GET http://ip: 端口 /_all # 查询所有索引信息
删除索引
DELETE http://ip: 端口 / 索引名称
关闭、打开索引
POST http://ip: 端口 / 索引名称 /_closePOST http://ip: 端口 / 索引名称 /_open
ES
数据类型
1. 简单数据类型
字符串
聚合:相当于
mysql
中的
sum
(求和)
text :会分词,不支持聚合keyword :不会分词,将全部内容作为一个词条,支持聚合
数值
布尔:
boolean
二进制:
binary
范围类型
integer_range, float_range, long_range, double_range, date_range
日期
:date
2. 复杂数据类型
数组:
[ ] Nested:
nested
(for arrays of JSON objects
数组类型的
JSON
对象
)
对象:
{ } Object: object(for single JSON objects
单个
JSON
对象
)
操作映射
创建映射
PUT person
#添加映射
PUT /person/_mapping
{
"properties":{
"name":{
"type":"text"
},
"age":{
"type":"integer"
}
}
}#创建索引并添加映射
PUT /person1
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
}
}
}
}
更改映射-添加字段
#添加字段
PUT /person1/_mapping
{
"properties": {
"adress": {
"type": "text"
},
}
}查询映射
GET person1/_mapping详细的mapping操作请点击这篇文章:
http://t.csdn.cn/Ex2Hxhttp://t.csdn.cn/Ex2Hx
操作文档
添加文档,指定id
POST /person1/_doc/2
{
"name":"张三",
"age":18,
"address":"北京"
}
GET /person1/_doc/1添加文档,不指定id
#添加文档,不指定id
POST /person1/_doc/
{
"name":"张三",
"age":18,
"address":"北京"
}
查询所有文档
GET /person1/_search
删除指定id文档
DELETE /person1/_doc/15.分词器
分词:即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词,比如““我爱编程”会被分为"我"∵爱"∵"编”"程”,这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。如果要使用中文,建议使用ik分词器!
•IKAnalyzer
是一个开源的,基于
java
语言开发的轻量级的中文分词工具包
•
是一个基于
Maven
构建的项目
•
具有
60
万字
/
秒的高速处理能力
•
支持用户词典扩展定义
•
下载地址:
https://github.com/medcl/elasticsearch-analysis-ik/archive/v7.4.0.zip
安装包在资料文件夹中提供,其中也有安装文档
https://download.csdn.net/download/weixin_44680802/88362801?spm=1001.2014.3001.5503https://download.csdn.net/download/weixin_44680802/88362801?spm=1001.2014.3001.5503
IK提供了两个分词算法:
ik_smart和ik_max_word,其中 ik_ smart为最少切分, ik_ max_word为最细粒度划分
查看ik_smart的
分词效果
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "乒乓球明年总冠军"
}
查看ik_max_word 的分词效果
GET /_analyze
{
"analyzer": "ik_smart",
"text": "乒乓球明年总冠军"
}
使用
IK
分词器
-
查询文档
•
词条查询:
term
词条查询不会分析查询条件,只有当词条和查询字符串完全匹配时才匹配搜索
•
全文查询:
match
全文查询会分析查询条件,先将查询条件进行分词,然后查询,求并集
1.
创建索引,添加映射,并指定分词器为
ik
分词器
PUT person2
{
"mappings": {
"properties": {
"name": {
"type": "keyword"
},
"address": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
2.
添加文档
POST /person2/_doc/1
{
"name":"张三",
"age":18,
"address":"北京海淀区"
}
POST /person2/_doc/2
{
"name":"李四",
"age":18,
"address":"北京朝阳区"
}
POST /person2/_doc/3
{
"name":"王五",
"age":18,
"address":"北京昌平区"
}
3.
查询映射
GET person2
4.
查看分词效果
GET _analyze
{
"analyzer": "ik_max_word",
"text": "北京海淀"
}
5.
词条查询:
term
查询
person2
中匹配到
"
北京
"
两字的词条
GET /person2/_search
{
"query": {
"term": {
"address": {
"value": "北京"
}
}
}
}
6.
全文查询:
match
全文查询会分析查询条件,先将查询条件进行分词,然后查询,求并集
GET /person2/_search
{
"query": {
"match": {
"address":"北京昌平"
}
}
}6. ElasticSearch JavaAP
SpringBoot整合ES
①搭建
SpringBoot
工程
②引入
ElasticSearch
相关坐标
<!--引入es的坐标-->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.4.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.4.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.4.0</version>
</dependency>
③测试 ElasticSearchConfig
@Configuration
@ConfigurationProperties(prefix="elasticsearch")
public class ElasticSearchConfig {
private String host;
private int port;
public String getHost() {
return host;
}
public void setHost(String host) {
this.host = host;
}
public int getPort() {
return port;
}
public void setPort(int port) {
this.port = port;
}
@Bean
public RestHighLevelClient client(){
return new RestHighLevelClient(RestClient.builder(
new HttpHost(host,port,"http")));
}
}测试类
@SpringBootTest
class ElasticsearchDay01ApplicationTests {
@Autowired
RestHighLevelClient client;
/**
* 测试
*/
@Test
void contextLoads() {
System.out.println(client);
}
}索引操作
添加索引
/**
* 添加索引
* @throws IOException
*/
@Test
public void addIndex() throws IOException {
//1.使用client获取操作索引对象
IndicesClient indices = client.indices();
//2.具体操作获取返回值
//2.1 设置索引名称
CreateIndexRequest createIndexRequest=new CreateIndexRequest("itheima");
CreateIndexResponse createIndexResponse =
indices.create(createIndexRequest, RequestOptions.DEFAULT);
//3.根据返回值判断结果
System.out.println(createIndexResponse.isAcknowledged());
}添加索引,并添加映射
/** * 添加索引,并添加映射 */ @Test public void addIndexAndMapping() throws IOException { //1.使用client获取操作索引对象 IndicesClient indices = client.indices(); //2.具体操作获取返回值 //2.具体操作,获取返回值 CreateIndexRequest createIndexRequest = new CreateIndexRequest("itcast"); //2.1 设置mappings String mapping = "{\n" + " \"properties\" : {\n" + " \"address\" : {\n" + " \"type\" : \"text\",\n" + " \"analyzer\" : \"ik_max_word\"\n" + " },\n" + " \"age\" : {\n" + " \"type\" : \"long\"\n" + " },\n" + " \"name\" : {\n" + " \"type\" : \"keyword\"\n" + " }\n" + " }\n" + " }"; createIndexRequest.mapping(mapping,XContentType.JSON); CreateIndexResponse createIndexResponse = indices.create(createIndexRequest, RequestOptions.DEFAULT); //3.根据返回值判断结果 System.out.println(createIndexResponse.isAcknowledged()); }
查询索引
/**
* 查询索引
*/
@Test
public void queryIndex() throws IOException {
IndicesClient indices = client.indices();
GetIndexRequest getRequest=new GetIndexRequest("itcast");
GetIndexResponse response = indices.get(getRequest,
RequestOptions.DEFAULT);
Map<String, MappingMetaData> mappings = response.getMappings();
//iter 提示foreach
for (String key : mappings.keySet()) {
System.out.println(key+"==="+mappings.get(key).getSourceAsMap());
}
}
删除索引
/**
* 删除索引
*/
@Test
public void deleteIndex() throws IOException {
IndicesClient indices = client.indices();
DeleteIndexRequest deleteRequest=new DeleteIndexRequest("itheima");
AcknowledgedResponse delete = indices.delete(deleteRequest,
RequestOptions.DEFAULT);
System.out.println(delete.isAcknowledged());
}索引是否存在 文章来源:https://www.toymoban.com/news/detail-723651.html
/**
* 索引是否存在
*/
@Test
public void existIndex() throws IOException {
IndicesClient indices = client.indices();
GetIndexRequest getIndexRequest=new GetIndexRequest("itheima");
boolean exists = indices.exists(getIndexRequest,
RequestOptions.DEFAULT);
System.out.println(exists);
}文档操作文章来源地址https://www.toymoban.com/news/detail-723651.html
添加文档
,
使用
map
作为数据
@Test
public void addDoc1() throws IOException {
Map<String, Object> map=new HashMap<>();
map.put("name","张三");
map.put("age","18");
map.put("address","北京二环");
IndexRequest request=new IndexRequest("itcast").id("1").source(map);
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
System.out.println(response.getId());
}
添加文档
,
使用对象作为数据
@Test
public void addDoc2() throws IOException {
Person person=new Person();
person.setId("2");
person.setName("李四");
person.setAge(20);
person.setAddress("北京三环");
String data = JSON.toJSONString(person);
IndexRequest request=new
IndexRequest("itcast").id(person.getId()).source(data,XContentType.JSON);
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
System.out.println(response.getId());
}
修改文档:添加文档时,如果
id
存在则修改,
id
不存在则添加
/**
* 修改文档:添加文档时,如果id存在则修改,id不存在则添加
*/
@Test
public void UpdateDoc() throws IOException {
Person person=new Person();
person.setId("2");
person.setName("李四");
person.setAge(20);
person.setAddress("北京三环车王");
String data = JSON.toJSONString(person);
IndexRequest request=new
IndexRequest("itcast").id(person.getId()).source(data,XContentType.JSON);
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
System.out.println(response.getId());
}
根据
id
查询文档
/**
* 根据id查询文档
*/
@Test
public void getDoc() throws IOException {
//设置查询的索引、文档
GetRequest indexRequest=new GetRequest("itcast","2");
GetResponse response = client.get(indexRequest, RequestOptions.DEFAULT);
System.out.println(response.getSourceAsString());
}
根据
id
删除文档
/**
* 根据id删除文档
*/
@Test
public void delDoc() throws IOException {
//设置要删除的索引、文档
DeleteRequest deleteRequest=new DeleteRequest("itcast","1");
DeleteResponse response = client.delete(deleteRequest,
RequestOptions.DEFAULT);
System.out.println(response.getId());
}到了这里,关于ElasticSearch从入门到精通(一)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!










