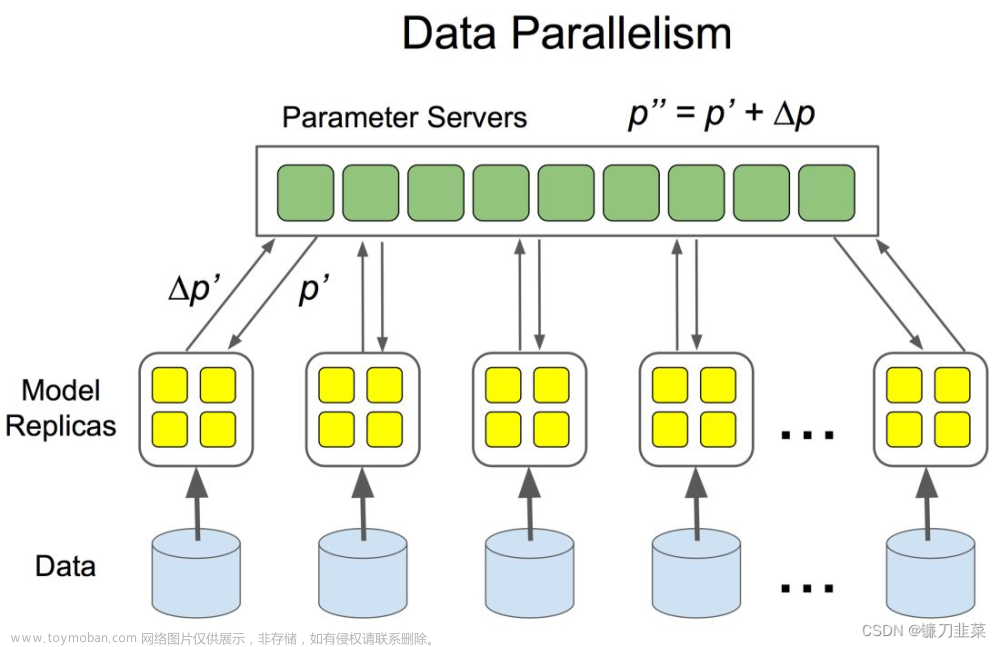
正如标题所写,我们正常的普通训练都是单机单卡或单机多卡。而往往一个高精度的模型需要训练时间很长,所以DDP分布式数据并行和混合精度可以加速模型训练。混精可以增大batch size.
如下提供示例代码,经过官网查阅验证的。原始代码由百度文心一言提供。
问题:pytorch 分布式数据并行与学习率周期和混合精度训练的示例代码
该问题分别问了(当前2023年10月16日)百度文心一言,google bard,科大讯飞星火,chatgpt4,bing。目前看来只有文心给出最接近正确答案。当前版本 pythorch 2.0.1。关于混精 torch.cuda.amp.autocast(args...)`` is equivalent to ``torch.autocast("cuda", args...),混精可以参考:
- https://pytorch.org/tutorials/recipes/recipes/amp_recipe.html?highlight=torch%20cuda%20amp%20autocast
- https://pytorch.org/docs/stable/amp.html#gradient-scaling
1、SPAWN方式
在使用这些助手(都是免费的)时,发现对于不同问题,各自的优劣不同,所以可以都试一下。
在PyTorch中,分布式数据并行(Distributed Data Parallel,DDP)可以在多个GPU上并行训练模型,提高训练速度。学习率周期(Learning Rate Schedules)用于调整训练过程中学习率的变化,而混合精度训练则可以提高训练速度并减少内存使用。
以下是一个使用PyTorch的分布式数据并行、学习率周期和混合精度训练的示例代码:
import os
import torch
import torch.nn as nn
import torch.optim as optim
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.optim.lr_scheduler import ExponentialLR, CosineAnnealingLR
from torch.cuda.amp import GradScaler, autocast
def setup(rank, world_size):
"""
Args:
rank: Unique identifier of each process
world_size: Total number of processes
"""
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
# initialize the process group
dist.init_process_group(backend="nccl", rank=rank, world_size=world_size)
torch.cuda.set_device(rank)
def cleanup():
dist.destroy_process_group()
# 定义模型
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(10, 10)
def forward(self, x):
return self.fc(x)
# 训练函数
def train(rank, world_size):
print(f"Running basic DDP example on rank {rank}.")
gpu=rank
setup(rank=rank,world_size=world_size,)
torch.manual_seed(0)
model = SimpleModel().cuda(gpu)
ddp_model = DDP(model, device_ids=[gpu])
# 使用混合精度训练
scaler = GradScaler()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.01)
# 使用学习率周期
scheduler1 = ExponentialLR(optimizer, gamma=0.9)
scheduler2 = CosineAnnealingLR(optimizer, T_max=50, eta_min=0)
# 模拟数据
data = torch.randn(32, 10).to(gpu)
target = torch.randn(32, 10).to(gpu)
for epoch in range(100):
optimizer.zero_grad()
with autocast(): # 启用混合精度训练
output = ddp_model(data)
loss = nn.MSELoss()(output, target)
scaler.scale(loss).backward() # 使用scaler进行梯度缩放
scaler.step(optimizer) # 更新参数
scaler.update() # 更新GradScaler状态
scheduler1.step() # 使用ExponentialLR调整学习率
scheduler2.step() # 使用CosineAnnealingLR调整学习率
print(f"Rank {rank}, Epoch {epoch}, Loss {loss.item()}")
#模型保存
#如是是多gpu训练保存时需要使用model.module
#model.module if is_parallel(model) else model
cleanup()
if __name__ == "__main__":
world_size = torch.cuda.device_count() # 获取可用GPU的数量
mp.spawn(train, args=(world_size,), nprocs=world_size, join=True) # 在每个GPU上运行train函数
这个示例代码在每个GPU上并行训练一个简单的线性模型。每个进程(即每个GPU)都有自己的模型副本,并且每个进程都独立计算梯度。然后,所有进程都会聚集他们的梯度并平均,然后用于一次总体参数更新。这个过程会根据学习率周期来调整每个epoch后的学习率
本部分参考官方的:https://pytorch.org/tutorials/beginner/ddp_series_multigpu.html?highlight=torch%20multiprocessing 是写单GPU和多GPU的区别。
2、torchrun 方式
首先是写一个ddp.py,内容如下:
import os
import torch
import torch.nn as nn
import torch.optim as optim
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.optim.lr_scheduler import ExponentialLR, CosineAnnealingLR
from torch.cuda.amp import GradScaler, autocast
# 定义模型
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(10, 10)
def forward(self, x):
return self.fc(x)
# 训练函数
def train():
dist.init_process_group("nccl")
rank = dist.get_rank()
print(f"Start running basic DDP example on rank {rank}.")
gpu = rank % torch.cuda.device_count()
torch.manual_seed(0)
model = SimpleModel().to(gpu)
ddp_model = DDP(model, device_ids=[gpu])
# 使用混合精度训练
scaler = GradScaler()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.01)
# 使用学习率周期
scheduler1 = ExponentialLR(optimizer, gamma=0.9)
scheduler2 = CosineAnnealingLR(optimizer, T_max=50, eta_min=0)
# 模拟数据
data = torch.randn(32, 10).to(gpu)
target = torch.randn(32, 10).to(gpu)
for epoch in range(100):
optimizer.zero_grad()
with autocast(): # 启用混合精度训练
output = ddp_model(data)
loss = nn.MSELoss()(output, target)
scaler.scale(loss).backward() # 使用scaler进行梯度缩放
scaler.step(optimizer) # 更新参数
scaler.update() # 更新GradScaler状态
scheduler1.step() # 使用ExponentialLR调整学习率
scheduler2.step() # 使用CosineAnnealingLR调整学习率
print(f"Rank {rank}, Epoch {epoch}, Loss {loss.item()}")
dist.destroy_process_group()
if __name__ == "__main__":
train()
单机多卡,执行:
torchrun --nproc_per_node=4 --standalone ddp.py
如果是多机多卡:文章来源:https://www.toymoban.com/news/detail-723680.html
torchrun --nnodes=2 --nproc_per_node=8 --rdzv_id=100 --rdzv_backend=c10d --rdzv_endpoint=$MASTER_ADDR:29400 elastic_ddp.py
本部分参考:
https://pytorch.org/tutorials/intermediate/ddp_tutorial.html#save-and-load-checkpoints
其它参考:https://github.com/lyuwenyu/RT-DETR/tree/main 可以看到pytorch的训练低层方法。
https://github.com/huggingface/pytorch-image-models 这个也有文章来源地址https://www.toymoban.com/news/detail-723680.html
到了这里,关于1、pytorch分布式数据训练结合学习率周期及混合精度的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!