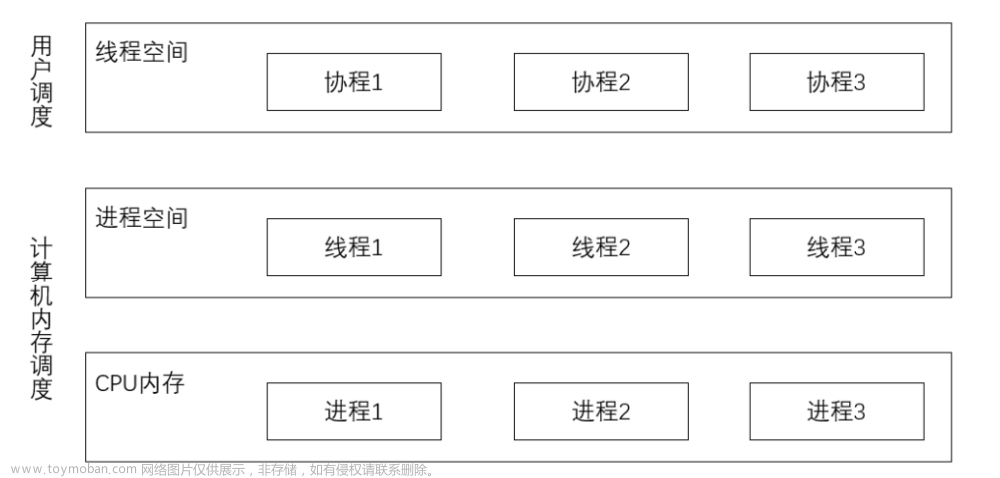
🍋引言
在网络爬虫的世界里,效率是关键。为了快速地获取大量数据,我们需要运用一些高级技巧,如多线程和多进程。在本篇博客中,我们将学习如何使用Python的多线程和多进程来构建一个高效的网络爬虫,以便更快速地获取目标网站上的信息。
🍋为什么要使用多线程和多进程?
在单线程爬虫中,我们按照顺序一个个页面地下载和解析数据。这在小型网站上可能没有问题,但在处理大规模数据时会变得非常缓慢。多线程和多进程可以帮助我们同时处理多个页面,从而提高爬虫的效率。
-
多线程:在一个进程内,多个线程可以并发执行,共享相同的内存空间。这意味着它们可以更快速地完成任务,但需要小心线程安全问题。
-
多进程:多个进程是独立的,每个进程都有自己的内存空间。这可以避免线程安全问题,但在创建和管理进程时会产生额外的开销。
🍋线程的常用方法
-
threading.Thread(target, args=(), kwargs={}):创建一个线程对象,用于执行指定的目标函数。
target:要执行的目标函数。
args:目标函数的位置参数,以元组形式传递。
kwargs:目标函数的关键字参数,以字典形式传递。 -
thread.start():启动线程,使其开始执行目标函数。
-
thread.join(timeout=None):等待线程完成执行。可选的timeout参数用于指定最长等待时间,如果超时,将继续执行主线程。
-
thread.is_alive():检查线程是否在运行。如果线程仍在执行中,返回True;否则返回False。
-
threading.current_thread():返回当前线程对象,可以用于获取当前线程的信息。
-
threading.active_count():返回当前活动线程的数量。
-
threading.enumerate():返回当前所有活动线程的列表。
-
threading.Thread.getName()和threading.Thread.setName(name):获取和设置线程的名称。
-
threading.Thread.isDaemon()和threading.Thread.setDaemon(daemonic):获取和设置线程的守护状态。守护线程在主线程结束时会被强制终止。
-
threading.Thread.ident:获取线程的唯一标识符。
-
threading.Lock():创建一个互斥锁对象,用于实现线程同步。
-
lock.acquire():获取锁,进入临界区。
-
lock.release():释放锁,退出临界区。
-
.sleep() 方法是线程对象(threading.Thread)中的一个非常常用的方法之一,它用于使线程暂停执行一段指定的时间,但是用到的库是time
🍋线程锁(也称为互斥锁或简称锁)
用于线程间的同步,主要有以下两个目的:
-
防止竞争条件(Race Condition): 竞争条件指的是多个线程在同时访问共享资源时,由于执行顺序不确定而导致的不确定性和错误。当多个线程尝试同时修改共享数据时,可能会导致数据不一致性和错误结果。线程锁可以防止竞争条件,使得只有一个线程能够访问共享资源,其他线程需要等待锁释放。
-
确保数据一致性: 在多线程环境下,当多个线程同时访问和修改共享数据时,可能会导致数据的不一致性。使用锁可以确保在任何时候只有一个线程能够访问和修改共享数据,从而确保数据的一致性。
这里可以举个例子:
当我们在银行取钱的时候,如果没有线程锁的保护,一大堆人同时取钱,那么余额就不好计算了。所以在多个线程同时进行存款和取款操作,但由于线程锁的保护,这些操作不会导致账户数据的混乱或错误。最后,我们打印出最终的账户余额,以确保数据一致性。
🍋小案例
这里我们通过一个小案例感受一下多线程的魅力吧~
import time
import threading
import requests
from bs4 import BeautifulSoup
urls = []
for j in range(1, 5):
url = f'https://example.com/page{j}'
urls.append(url)
# 存储字典
results = {}
lock = threading.Lock()
def func(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.title.string
# 使用线程锁确保字典操作的线程安全
with lock:
results[url] = title
# 创建线程列表
threads = []
start = time.time()
# 创建并启动线程
for url in urls:
thread = threading.Thread(target=func, args=(url,))
threads.append(thread)
thread.start()
# 等待所有线程完成
for thread in threads:
thread.join()
stop = time.time()
# 打印爬取结果
for url, title in results.items():
print(f'URL: {url}, Title: {title}')
print(stop-start)
这里我们用测试网页中的title
在这个示例中,我们定义了一个包含多个网页url的列表 urls,然后创建了多个线程来并发地爬取这些网页的标题。每个线程使用 requests 库发送请求,解析网页内容,提取标题,并将结果存储在一个共享的 results 字典中。为了确保字典操作的线程安全,我们使用了一个线程锁 lock。最后用time测试了一次时间。
🍋实战—手办网
先将之前相关爬取手办网放在下方
# 导入模块
import requests
from bs4 import BeautifulSoup
import time
import threading
# 定义url和请求头
_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36",
"Cookie": "utoken=UTKbd23efb1729a444898977cf2a91381c0; JSESSIONID=9EF5C8BA4F3C3E29278A9972A946408A; Hm_lvt_05b494824003cbf80b23e846462269d1=1688387237,1688712147,1689130492,1689145041; allOrder=release; Hm_lpvt_05b494824003cbf80b23e846462269d1=1689145105utoken=UTKbd23efb1729a444898977cf2a91381c0; JSESSIONID=9EF5C8BA4F3C3E29278A9972A946408A; Hm_lvt_05b494824003cbf80b23e846462269d1=1688387237,1688712147,1689130492,1689145041; allOrder=release; Hm_lpvt_05b494824003cbf80b23e846462269d1=1689145105utoken=UTKbd23efb1729a444898977cf2a91381c0; JSESSIONID=9EF5C8BA4F3C3E29278A9972A946408A; Hm_lvt_05b494824003cbf80b23e846462269d1=1688387237,1688712147,1689130492,1689145041; allOrder=release; Hm_lpvt_05b494824003cbf80b23e846462269d1=1689145105"
}
"""
https://www.hpoi.net/hobby/all?order=release&r18=-1&workers=&view=3&category=100&page=1
https://www.hpoi.net/hobby/all?order=release&r18=-1&workers=&view=3&category=100&page=2
https://www.hpoi.net/hobby/all?order=release&r18=-1&workers=&view=3&category=100&page=3
"""
start = time.time()
# 获取前五页的url
urls = []
for i in range(1,5):
url ='https://www.hpoi.net/hobby/all?order=release&r18=-1&workers=&view=3&category=100&page={}'.format(i)
urls.append(url)
items = []
for d_url in urls:
# 发送请求
response = requests.get(d_url, headers=_headers)
content = response.content.decode('utf8')
# 实例化对象
soup = BeautifulSoup(content, 'lxml')
# 名称
data = soup.find_all('ul',class_="hpoi-glyphicons-list")
for i in data:
data_1 = i.find_all('li')
for j in data_1:
data_2 = j.find_all('div',class_="hpoi-detail-grid-right")
for k in data_2:
title = k.find_all('a')[0].string
changshang = k.find_all('span')[0].text[3:]
chuhe = k.find_all('span')[1].text[3:]
price = k.find_all('span')[2].text[3:]
data_3 = {
"名称": title,
"厂商":changshang,
"出荷":chuhe,
"价位":price
}
items.append(data_3)
print(items)
stop = time.time()
print(stop-start)
运行结果如下
之后我们使用多线程进行实现
# 导入模块
import requests
from bs4 import BeautifulSoup
import time
import threading
# 定义url和请求头
_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36",
"Cookie": "utoken=UTKbd23efb1729a444898977cf2a91381c0; JSESSIONID=9EF5C8BA4F3C3E29278A9972A946408A; Hm_lvt_05b494824003cbf80b23e846462269d1=1688387237,1688712147,1689130492,1689145041; allOrder=release; Hm_lpvt_05b494824003cbf80b23e846462269d1=1689145105utoken=UTKbd23efb1729a444898977cf2a91381c0; JSESSIONID=9EF5C8BA4F3C3E29278A9972A946408A; Hm_lvt_05b494824003cbf80b23e846462269d1=1688387237,1688712147,1689130492,1689145041; allOrder=release; Hm_lpvt_05b494824003cbf80b23e846462269d1=1689145105utoken=UTKbd23efb1729a444898977cf2a91381c0; JSESSIONID=9EF5C8BA4F3C3E29278A9972A946408A; Hm_lvt_05b494824003cbf80b23e846462269d1=1688387237,1688712147,1689130492,1689145041; allOrder=release; Hm_lpvt_05b494824003cbf80b23e846462269d1=1689145105"
}
"""
https://www.hpoi.net/hobby/all?order=release&r18=-1&workers=&view=3&category=100&page=1
https://www.hpoi.net/hobby/all?order=release&r18=-1&workers=&view=3&category=100&page=2
https://www.hpoi.net/hobby/all?order=release&r18=-1&workers=&view=3&category=100&page=3
"""
start = time.time()
# 获取前五页的url
items = []
def shouban(url):
# for d_url in urls:
# 发送请求
response = requests.get(url, headers=_headers)
content = response.content.decode('utf8')
# 实例化对象
soup = BeautifulSoup(content, 'lxml')
# 名称
data = soup.find_all('ul',class_="hpoi-glyphicons-list")
for i in data:
data_1 = i.find_all('li')
for j in data_1:
data_2 = j.find_all('div',class_="hpoi-detail-grid-right")
for k in data_2:
title = k.find_all('a')[0].string
changshang = k.find_all('span')[0].text[3:]
chuhe = k.find_all('span')[1].text[3:]
price = k.find_all('span')[2].text[3:]
data_3 = {
"名称": title,
"厂商":changshang,
"出荷":chuhe,
"价位":price
}
items.append(data_3)
urls = []
t_list = []
for i in range(1,5):
url =f'https://www.hpoi.net/hobby/all?order=release&r18=-1&workers=&view=3&category=100&page={i}'
t1 = threading.Thread(target=shouban, args=(url,))
t1.start()
t_list.append(t1)
for i in t_list:
i.join()
stop = time.time()
print(items)
print(stop-start)
运行结果如下
注意:可以适当添加sleep,防止被封,如果爬取大量数据,多线程表现的会更明显一点
🍋总结
通过使用多线程和多进程,我们可以显著提高网络爬虫的效率,更快地获取大量数据。然而,要小心线程安全问题和进程管理的开销。在实际项目中,还需要考虑异常处理、数据存储等更多细节,感谢看到结尾的小伙伴,感谢您的支持!
 文章来源:https://www.toymoban.com/news/detail-723890.html
文章来源:https://www.toymoban.com/news/detail-723890.html
挑战与创造都是很痛苦的,但是很充实。文章来源地址https://www.toymoban.com/news/detail-723890.html
到了这里,关于Python实战:用多线程和多进程打造高效爬虫的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!