1.窗口聚合算子
在Flink中窗口聚合算子主要分类两类
- 滚动聚合算子(增量聚合)
- 全窗口聚合算子(全量聚合)
1.1 滚动聚合算子
滚动聚合算子一次只处理一条数据,通过算子中的累加器对聚合结果进行更新,当窗口触发时再从累加器中取结果数据,一般使用算子如下:
- aggregate
- max
- maxBy
- min
- minBy
- reduce
- sum
这里以aggregate算子作为示例
// ...
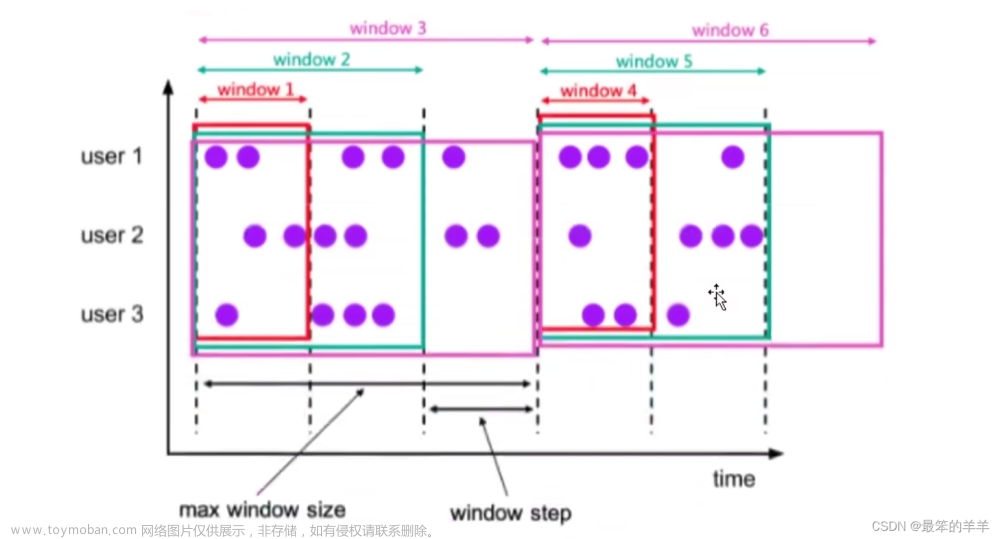
// 每10s统计一次每个用户最近30s的行为条数
SingleOutputStreamOperator<Tuple2<String, Integer>> result = watermarked.keyBy(userEvent -> userEvent.getUId())
.window(SlidingEventTimeWindows.of(Time.seconds(30), Time.seconds(10))) // 参数1:窗口长度 参数2:滑动步长即计算频率
.aggregate(new AggregateFunction<UserEvent2, Tuple2<String, Integer>, Tuple2<String, Integer>>() {
// 这里给一个初始值
@Override
public Tuple2<String, Integer> createAccumulator() {
return Tuple2.of("", 0);
}
// 在累加器中统计每个用户行为条数(来一条更新一次)
@Override
public Tuple2<String, Integer> add(UserEvent2 value, Tuple2<String, Integer> accumulator) {
Tuple2<String, Integer> result = Tuple2.of(value.getUId() + "-" + value.getName(), accumulator.f1 + 1);
return result;
}
// 将累加器中的更新结果给到getResult方法,输出
@Override
public Tuple2<String, Integer> getResult(Tuple2<String, Integer> accumulator) {
return accumulator;
}
// 这个方法在流式计算中可以不用实现,在上下游数据进行合并时需要用到,以spark为例,上有map和下游reduce的计算结果需要合并时需要实现这个方法
@Override
public Tuple2<String, Integer> merge(Tuple2<String, Integer> a, Tuple2<String, Integer> b) {
Tuple2<String, Integer> merged = Tuple2.of(a.f0, a.f1 + b.f1);
return merged;
}
});
// ...
只展示部分代码,冗余代码已省略.
图解如下:
1.2 全窗口聚合算子
全窗口聚合算子会将数据记录在状态容器中,当窗口触发时会将整个窗口中的数据交给聚合函数,根据具体逻辑将这些数据进行计算,常用算子如下:
- apply
- process
这里以apply算子为例文章来源:https://www.toymoban.com/news/detail-724206.html
// ...
// 每10s统计一次最近30s每个用户行为发生事件最大两条数据
SingleOutputStreamOperator<UserEvent2> userEventTimeTop2 = keyedStream.window(SlidingEventTimeWindows.of(Time.seconds(30), Time.seconds(10)))
// 泛型1: 数据数据类型 泛型2: 输出数据类型 泛型3: key类型 泛型4: 窗口类型
.apply(new WindowFunction<UserEvent2, UserEvent2, String, TimeWindow>() {
/**
*@Param s 本次传入的key
*@Param window 本次传入窗口的各种元信息
*@Param input 本次输入的所有数据
*@Param out 输出数据
**/
@Override
public void apply(String s, TimeWindow window, Iterable<UserEvent2> input, Collector<UserEvent2> out) throws Exception {
// 创建集合接收迭代器中的数据
ArrayList<UserEvent2> userEvent2List = new ArrayList<>();
// 遍历迭代器,也就是输入数据
for (UserEvent2 userEvent2 : input) {
// 将数据添加到集合中
userEvent2List.add(userEvent2);
}
// 将集合中的数据根据用户行为发生事件进行排序
Collections.sort(userEvent2List, new Comparator<UserEvent2>() {
@Override
public int compare(UserEvent2 o1, UserEvent2 o2) {
// 倒序排序
return Integer.parseInt(o2.getTime()) - Integer.parseInt(o1.getTime());
}
});
// 将每个用户行为发生时间最大的两条数据输出
for (int i = 0; i < Math.min(userEvent2List.size(), 2); i++) {
out.collect(userEvent2List.get(i));
}
}
});
// ...
只展示部分代码,冗余代码已省略.
图解如下: 文章来源地址https://www.toymoban.com/news/detail-724206.html
文章来源地址https://www.toymoban.com/news/detail-724206.html
到了这里,关于Flink之窗口聚合算子的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!