1. Annoy vs Milvus简介
Annoy 和 Milvus 都是用于向量索引和相似度搜索的开源库,它们可以高效地处理大规模的向量数据。
Annoy(Approximate Nearest Neighbors Oh Yeah):
- Annoy 是一种近似最近邻搜索算法,它通过构建一个树状结构来加速最近邻搜索。
- Annoy 支持支持欧氏距离,曼哈顿距离,余弦距离,汉明距离或点 (内) 乘积距离等多种度量方式。
- Annoy 是一个轻量级的库,易于使用和集成,如果向量维度不是太多(例如 < 100 维),效果会比较好。
- 目前 Annoy 主要支持 Python 和 C++ 接口。
Milvus:
- Milvus 是一个基于向量相似度搜索的开源引擎,它可以将大规模向量数据快速存储和检索。
- Milvus 使用了各种索引和算法优化技术,提供了高效的向量搜索能力。
- Milvus 支持欧式距离、内积相似度等多种度量方式,且具有扩展性和可定制性。
- Milvus 提供了 Python、Java 和 Go 等多种编程语言的接口。
- Milvus 还提供了图形用户界面 (GUI) 和可视化工具来辅助管理和查询向量数据库。
选择 Annoy 还是 Milvus 取决于您的具体需求和应用场景:
- 如果对于
近似最近邻搜索的速度和轻量级集成更为关注,可以选择 Annoy。(demo 入门) - 如果需要
管理和查询大规模的向量数据库,并希望具备更多的功能和可扩展性,可以选择 Milvus。(工业级应用)
2.Annoy
Annoy (Approximate Nearest Neighbors Oh Yeah) 是一个带有 Python bindings 的 C ++ 库,用于搜索空间中给定查询点的近邻点。它还会创建大型的基于文件的只读数据结构,并将其映射到内存中,以便许多进程可以共享相同的数据。annoy 的学习成本非常低,能较快的掌握,非常适合项目的快速开发,于此对比的是,faiss 和 Milvus 的学习成本较高,用起来较为复杂。
用于空间检索近邻的数据。检索过程分成三步:
- 建立索引过程;
- 近邻查询过程;
- 返回最终近邻节点;
首先先来一张 2D 数据分布图:
接下来按照步骤 1,2 和 3 进行分析。
2.1 建立索引过程
Annoy 的目标是建立一个数据结构,使得查询一个点的最近邻点的时间复杂度是次线性。Annoy 通过建立一个二叉树来使得每个点查找时间复杂度是 O(log n)。以下图为例,随机选择两个点,以这两个节点为初始中心节点,执行聚类数为 2 的 kmeans 过程,最终产生收敛后两个聚类中心点。这两个聚类中心点之间连一条线段(灰色短线),建立一条垂直于这条灰线,并且通过灰线中心点的线(黑色粗线)。这条黑色粗线把数据空间分成两部分。在多维空间的话,这条黑色粗线可以看成等距垂直超平面。
在划分的子空间内进行不停的递归迭代继续划分,直到每个子空间最多只剩下 K 个数据节点。

通过多次递归迭代划分的话,最终原始数据会形成类似下图的二叉树结构。二叉树底层是叶子节点记录原始数据节点,其他中间节点记录的是分割超平面的信息。Annoy 建立这样的二叉树结构是希望满足这样的一个假设: 相似的数据节点应该在二叉树上位置更接近,一个分割超平面不应该把相似的数据节点分割二叉树的不同分支上。
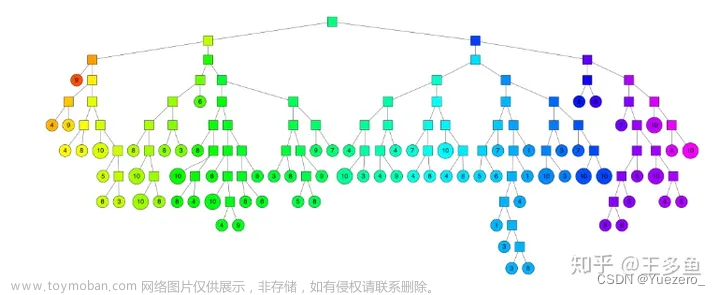
根据上述步骤,建立多棵二叉树树,构成一个森林。
2.2 近邻查询过程
上面已完成节点索引建立过程。如何进行对一个数据点进行查找相似节点集合呢?比如下图的红色节点,查找的过程就是不断看他在分割超平面的哪一边。从二叉树索引结构来看,就是从根节点不停的往叶子节点遍历的过程。通过对二叉树每个中间节点(分割超平面相关信息)和查询数据节点进行相关计算来确定二叉树遍历过程是往这个中间节点左孩子节点走还是右孩子节点走。通过以上方式完成查询过程。
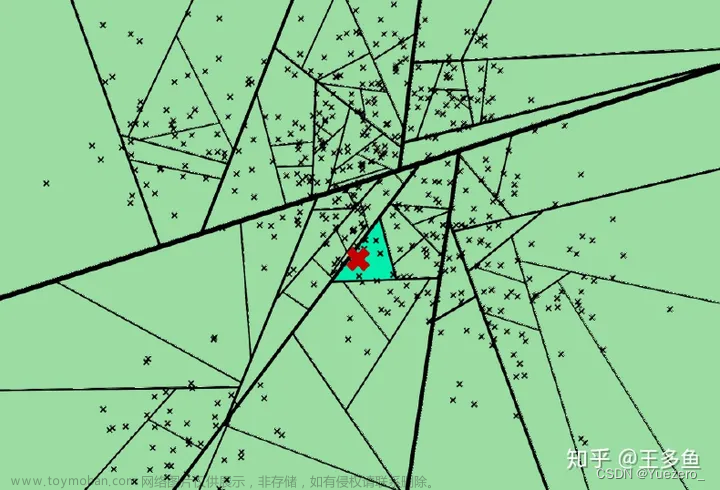
查询过程采用优先队列机制:采用一个优先队列来遍历二叉树,从根节点往下的路径,根据查询节点与当前分割超平面距离进行排序。
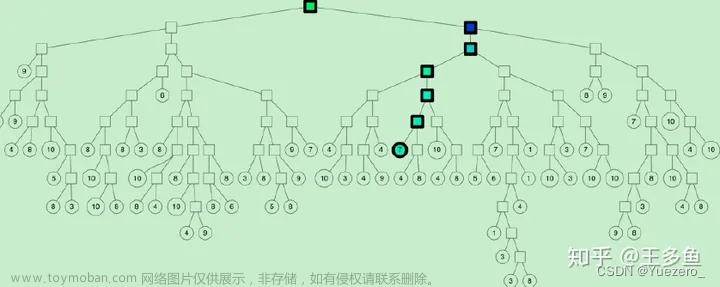
2.3 返回最终近邻节点
步骤 1 会构建多棵二叉树树,每棵树都返回一堆近邻点后,如何得到最终的Top N相似集合呢?首先所有树返回近邻点都插入到优先队列中,求并集去重, 然后计算和查询点距离,最终根据距离值从近距离到远距离排序,返回 Top-N 近邻节点集合。
2.4 完整的 Python API
-
AnnoyIndex(f, metric)返回可读写的新索引,用于存储 f 维度向量。metric 可以"angular","euclidean","manhattan","hamming","dot"。 -
a.add_item(i, v)用于给索引添加向量 v,i(任何非负整数)是给向量 v 的表示。 -
a.build(n_trees)用于构建 n_trees 的森林。查询时,树越多,精度越高。在调用build后,无法再添加任何向量。 -
a.save(fn, prefault=False)将索引保存到磁盘。保存后,不能再添加任何向量。 -
a.load(fn, prefault=False)从磁盘加载索引。如果 prefault 设置为 True,它将把整个文件预读到内存中。默认值为 False。 -
a.unload()释放索引。 -
a.get_nns_by_item(i, n, search_k=-1, include_distances=False)返回第 i 个 item 的 n 个最近邻的 item。在查询期间,它将检索多达 search_k(默认 n_trees * n)个点。search_k 为您提供了更好的准确性和速度之间权衡。如果设置 include_distances 为 True,它将返回一个包含两个列表的 2 元素元组:第二个包含所有对应的距离。 -
a.get_nns_by_vector(v, n, search_k=-1, include_distances=False)与上面的相同,但按向量 v 查询。 -
a.get_item_vector(i)返回第 i 个向量前添加的向量。 -
a.get_distance(i, j)返回向量 i 和向量 j 之间的距离。注意:此函数用于返回平方距离。 -
a.get_n_items()返回索引中的向量数。 -
a.get_n_trees()返回索引中的树的数量。 -
a.on_disk_build(fn)用以在指定文件而不是 RAM 中建立索引(在添加向量之前执行,在建立之后无需保存)。
Notes:
Annoy 使用归一化向量的欧式距离作为其角距离,对于两个向量 u,v,其等于 sqrt(2(1-cos(u,v)))
C ++ API 非常相似:调用 annoy 只需使用#include "annoylib.h"。
权衡
调整 Annoy 仅需要两个主要参数:树的数量 n_trees 和搜索期间要检查的节点的数量search_k。
-
n_trees在构建索引期间提供该值,并且会影响构建时间和索引大小。较大的值将给出更准确的结果,但索引较大。 -
search_k是在运行时提供的,并且会影响搜索性能。较大的值将给出更准确的结果,但返回时间将更长。
如果search_k未提供,它将默认为n * n_trees * D,n是近似最近邻居的数目,并且D是一个常数,取决于向量维度。否则,search_k和n_trees是大致独立的,即如果 search_k 保持不变,n_trees不会影响搜索时间,反之亦然。基本上,在您可以负担的内存使用量的情况下建议在n_trees可能大的值,并且在给定查询时间的限制的情况下建议设置search_k尽可能大。
3.Milvus从1.0到2.0的迭代优化

2018 年 10 月,写下了向量数据库 Milvus 的第一行代码;在历经了 29 个月、19 个版本的迭代与全球 1000 家用户的实践验证后,终于在 2021 年 3 月迎来了 Milvus 1.0 版本。Milvus 解决了对向量数据进行增删改查(CRUD)操作和数据持久化的问题,但随着新需求的出现,更多问题也逐渐浮现出来。本文旨在总结过去三年的经验,聊聊 Milvus 2.0 期待解决的问题,以及为什么 Milvus 2.0 是解决这些问题的良药。
3.1 Milvus 1.0 不足之处
1. 数据孤岛: Milvus 1.0 仅支持处理非结构化数据产生的向量数据,缺乏标量查询能力。数据存储的割裂造成应用设计的复杂度增加和数据冗余,且标量和向量混合查询也因缺少统一的优化器导致性能不佳。
2. 实时性与效率的冲突: 与 Elasticsearch 类似,Milvus 1.0 是一套近实时系统,需要定期或者主动落盘来确保数据可见。这种模型给流式处理带来很大的复杂性和不确定性。另一方面,离线批量导入场景核心关注处理效率,批量写入在处理全量离线数据的场景下依然消耗了大量资源。
3. 可扩展性和弹性不足: Milvus 1.0 依赖 Mishards 中间件实现分布式扩展,下层依赖共享存储实现典型的 Shared Storage 架构,但整体扩展性不足,主要体现在以下三个方面:
-
写节点是一个单点,无法横向扩展。
-
读节点的扩展基于一致性 hash 进行路由。一致性哈希尽管实现简单,但数据调度不够灵活,仅仅解决了数据分布均匀性的问题,不能很好地解决数据和算力不匹配的问题。
-
依赖 MySQL 管理元数据 —— 单机 MySQL 能支持的查询量和数据量都有限。
4. 可用性不足: 在传统的 CAP 定理中,Milvus 用户往往更加偏向于可用性(Availability)而不是一致性(Consistency)。Milvus 1.0 版本缺少多副本热备、跨机房容灾等能力,在可用性上并不理想。放弃一部分数据的准确性也有助于获得更好的性能。
5. 成本高昂: Milvus 1.0 依赖共享存储保证数据的持久性,而共享存储的成本通常是本地存储或者对象存储成本的 10 倍以上。由于向量搜索算法非常依赖计算资源和内存,过高的成本也成为了用户探索更大数据量和更多业务规则的阻碍。
6. 使用繁琐:
1)分布式版本部署复杂,运维成本高。
2)缺少好的图形化集群管理工具。
3)API 复杂,开发效率较低。
缝缝补补还是推倒重来,这是一个值得思考的问题。Milvus 项目发起人星爵认为,就像传统汽车巨头宝马奔驰永远造不出特斯拉,Milvus 需要成为非结构化数据领域的颠覆者,用户最终会像拥抱新能源汽车一样拥抱云原生的解决方案。Milvus 2.0 应云而生,作为贡献给非结构化数据处理的礼物。
3.2 架构设计理念升级, Milvus 2.0到来
围绕以下三个理念,重新定义下一代云原生向量数据库:
-
云原生优先**:**认为,只有存储计算分离的架构才能发挥云的弹性,实现按需扩容的模式。另一个值得注意是 Milvus 2.0 采取了读写分离、实时离线分离、计算瓶颈 / 内存瓶颈 / IO 瓶颈分离的微服务化设计模式,这有助于面对复杂的工作负载选择最佳的资源配比。
-
**日志即数据:**Milvus 引入消息存储作为系统的骨架,数据的插入修改只通过消息存储交互,执行节点通过订阅消息流来执行数据库的增删改查操作。这一设计的优势在于降低了系统的复杂度,将数据库关键的持久化和闪回等能力都下钻到存储层;另一方面,日志订阅机制提供了极大的灵活性,为系统未来的拓展奠定了基础。
-
**批流一体:**Milvus 2.0 实现了 unified Lambda 流式处理架构,增量数据和离线数据一体化处理。相比 Kappa 架构,Milvus 引入对日志流的批量计算将日志快照和构建索引存入对象存储,这大大提高了故障恢复速度和查询效率。为了将无界的流式数据拆分成有界的窗口,Milvus 采用 watermark 机制,通过写入时间(也可以是事件发生时间)将数据切分为多个小的处理单元,并维护了一条时间轴便于用户基于某个时间点进行查询。
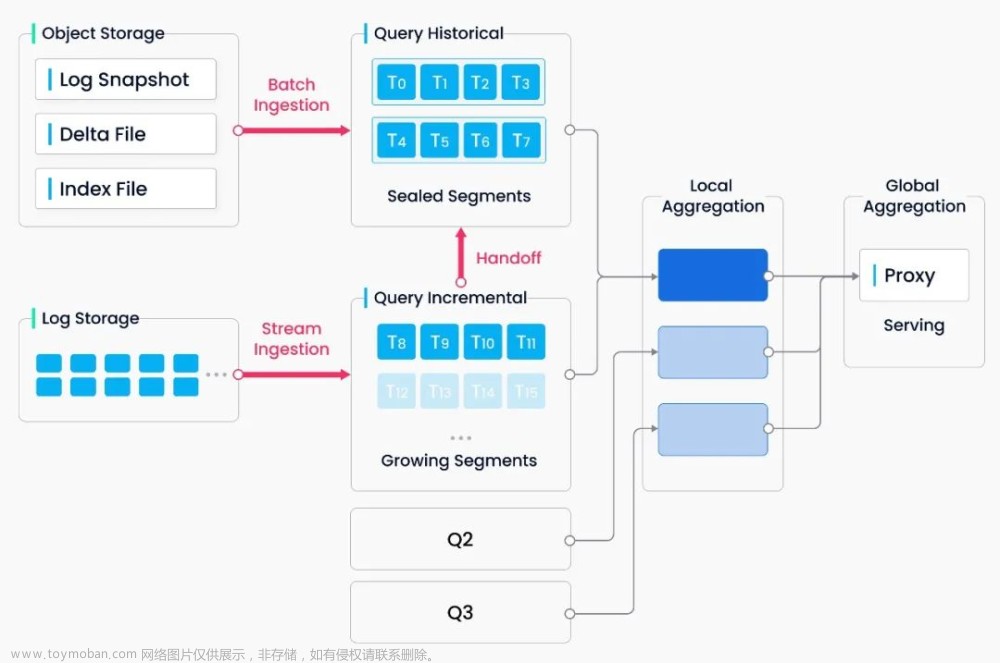
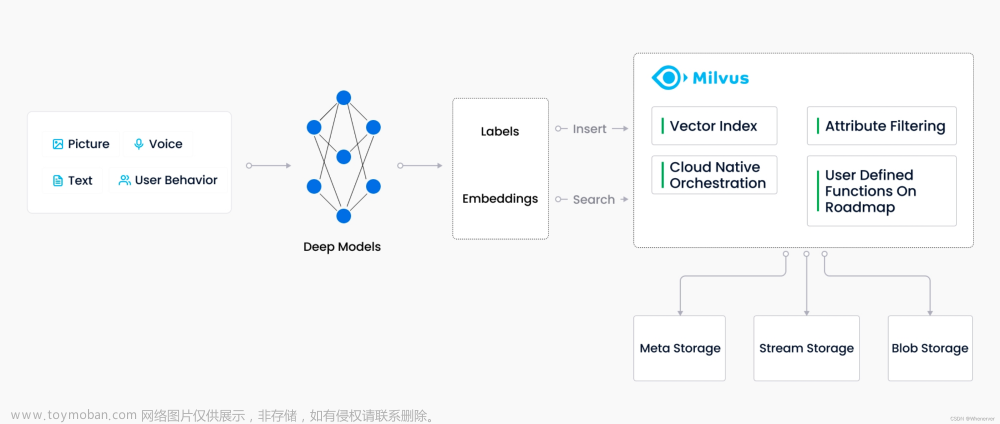
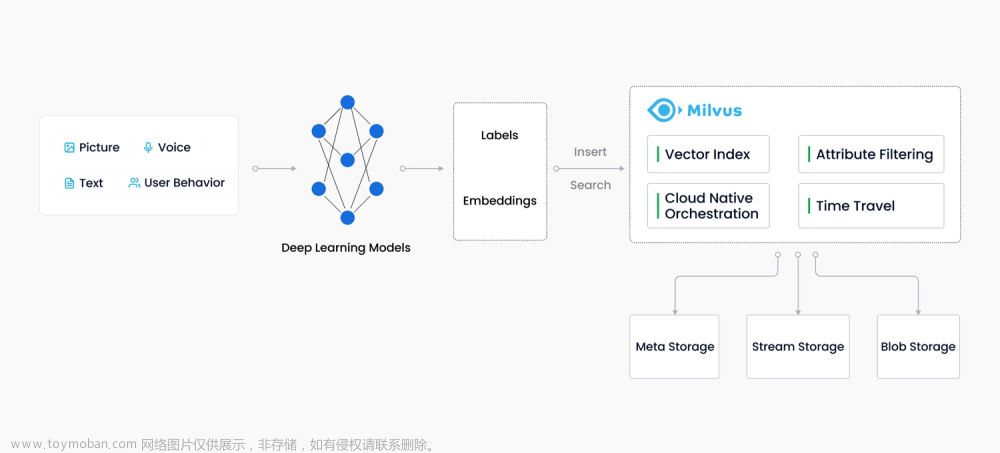
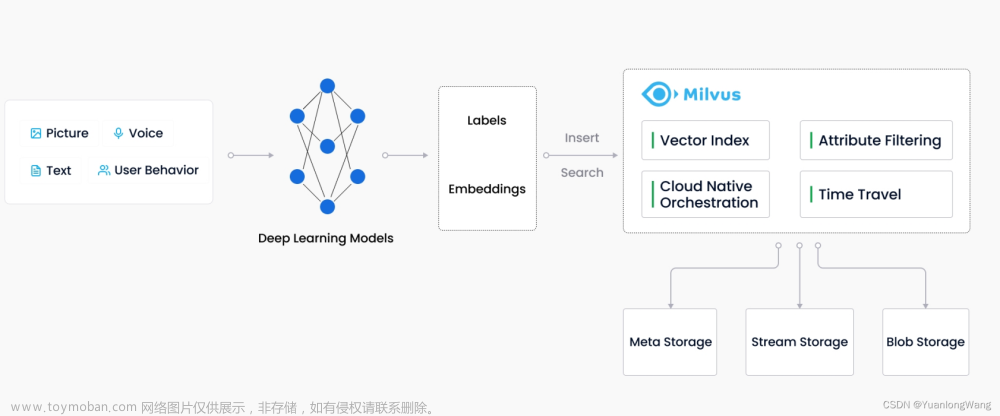
Milvus 系统严格遵从存储与计算分离、控制平面与数据平面分离的设计原则,整个系统分为四个部分: 接入层(Access Layer)、协调服务(Coordinator Service)、执行节**点**(Worker Node)和存储层(Storage)。
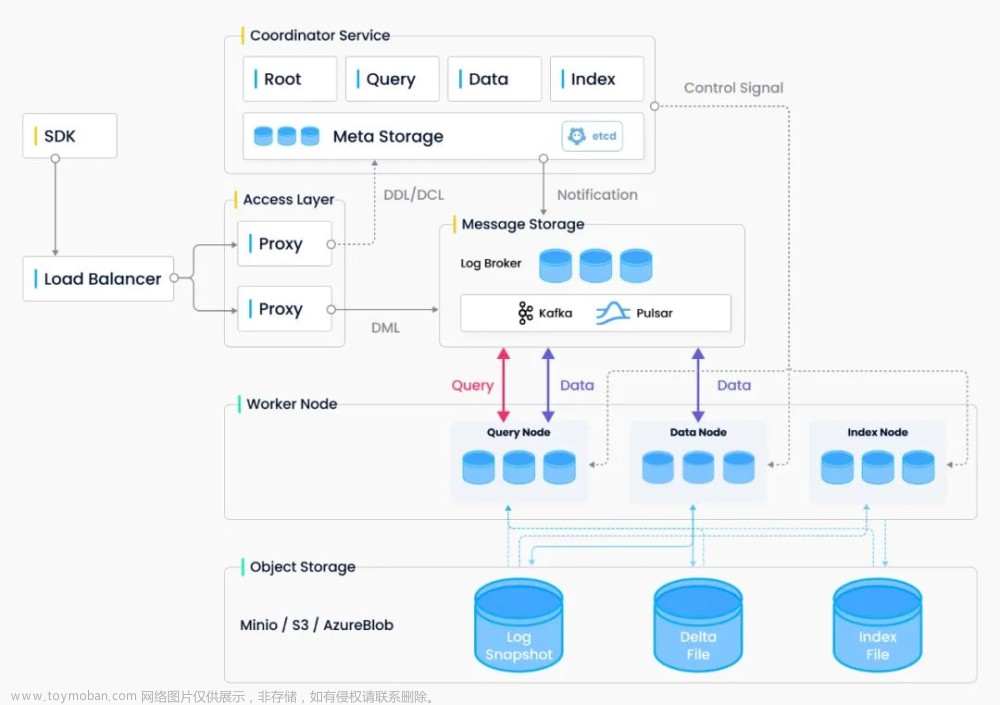
系统框架图
-
**接入层:**系统的门面,包含了一组对等的 proxy 节点。接入层是暴露给用户的统一 endpoint,负责转发请求并收集执行结果。
-
**协调服务:**系统的大脑。总共有四类协调者角色,分别为 root coord、data coord、query coord 和 index coord。
-
**执行节点:**系统的四肢。执行节点只负责被动执行协调服务发起的命令,响应接入层发起的读写请求。目前有三类执行节点,即 data node、query node 和 index node。
-
**存储服务:**系统的骨骼。Milvus 依赖三类存储:元数据存储、消息存储和对象存储。元数据存储便于协调服务存储 collection schema、数据消费位点等元信息,基于 etcd 实现。消息存储主要用于存储系统增量日志数据,实现可靠的异步通知机制,目前基于 Pulsar 实现。对象存储主要用于存储日志快照和索引数据,目前基于 MinIO 或 S3 实现。
3.3 功能亮点
Milvus 2.0 作为一款开源分布式向量数据库产品,始终将产品的易用性放在系统设计的第一优先级。一款数据库的使用成本不仅包含了运行态的资源消耗成本,也包含了运维成本和接入学习成本。Milvus 新版本支持了大量降低用户使用成本的功能。
1. 持续可用
实现数据的可靠存储和可持续的服务是对数据库产品的基本要求。理念是 Fail cheap, fail small, fail often。Fail cheap 指的是 Milvus 采取的存储计算分离架构,节点失败恢复的处理十分简单,且代价很低。Fail small 指的是 Milvus 采取分而治之的思想,每个协调服务仅处理读 / 写 / 增量 / 历史数据中的一个部分,设计被大大简化。Fail often 指的是混沌测试的引入,通过故障注入模拟硬件异常、依赖失效等场景,加速问题在测试环境被发现的概率。
2. 向量 / 标量混合查询
为了解决结构化数据和非结构化数据的割裂问题,Milvus 2.0 支持标量存储和向量标量混合查询。混合查询帮助用户找出符合过滤表达式的近似邻,目前 Milvus 支持等于、大于、小于等关系运算以及 NOT、AND、OR 、IN 等逻辑运算。
3. 多一致性
Milvus 2.0 是基于消息存储构建的分布式数据库,遵循 PACELC 定理所定义的,必须在一致性和可用性 / 延迟之间进行取舍。绝大多数 Milvus 场景在生产中不应过分关注数据一致性的问题,原因是接受少量数据不可见对整体召回率的影响极小,但对于性能的提升帮助很大。尽管如此,认为强一致性、有界一致性、会话一致性等一致性保障语义依然有其独特的应用场景。比如,在功能测试场景下,用户可能期待使用强一致语义保证测试结果的正确性,因此 Milvus 支持请求级别的可调一致性级别。
4. 时间旅行:
数据工程师经常会因为脏数据、代码逻辑等问题需要回滚数据。传统的数据库通常通过快照方式来实现数据回滚,有时甚至需要重新训练,带来高昂的额外开销和维护成本。Milvus 对所有数据增删操作维护了一条时间轴,用户查询时可以指定时间戳以获取某个时间点之前的数据视图。基于 Time Travel,Milvus 还可以很轻量地实现备份和数据克隆功能。
5. ORM Python SDK:
对象关系映射(Object Relational Mapping)技术使用户更加关注于业务模型而非底层的数据模型,便于开发者维护表、字段与程序之间的关联关系。为了弥补 AI 算法概念验证(Proof of concept)到实际生产部署之间的缺口,设计了 Milvus ORM API,而其背后的实现可以是通过嵌入式的 Library、单机部署、分布式集群,也可能是云服务。通过统一的 API 提供一致的使用体验,避免云端两侧重复开发、测试与上线效果不一致等问题。
6. 丰富的周边支持:
**1. 图形化管理界面:**Milvus Insight 是 Milvus 图形化管理界面,包含了集群状态可视化、元数据管理、数据查询等实用功能。Milvus Insight 源码也会作为独立项目开源,期待有更多感兴趣的人加入共同建设。
2. 支持基于 helm 和 docker-compose 的一键部署。
**3. 性能监控:**Milvus 2.0 使用开源时序数据库 Prometheus 存储性能和监控数据,同时依赖 Grafana 进行指标展示。
以上是 Milvus 2.0 版本的简单介绍,如有兴趣了解更多 Milvus 2.0 的相关内容,请参阅完整的 **Milvus 2.0 发版说明:**https://github.com/milvus-io/milvus/releases。
3.4 关于未来发展
回顾 Milvus 的发展历程,认为基于大数据 + AI 的应用架构依然过于复杂,简化非结构化数据处理一直是 Milvus 社区努力的方向。接下来的 Milvus 项目会重点关注以下几个方向:
**DB for AI:**作为一款数据库,除了基本的 CRUD 功能之外,Milvus 必然还需要更强大的数据查询能力、更智能的查询优化器、更全的数据管理功能等。下一阶段将重点补齐 Milvus 2.0 目前还不支持的 DML 功能和数据类型,比如删除、更新操作和支持 string 数据类型。
**AI for DB:**向量索引类型、索引参数、用户工作负载、硬件类型、成本性能等的约束构成了一个非常庞大的 tradeoff,尽可能避免手动调优有助于降低使用复杂度。已经着手分析系统负载,收集访问热度的数据,后续将引入自动参数调优工作以降低用户的理解成本。
**成本优化:**向量召回的最大挑战是需要在限定时间内处理海量数据,这项工作既是计算密集型,也是访存密集型。在物理执行层引入 GPU、FPGA 等异构硬件加速可以大幅降低 CPU 开销。正在开发磁盘内存混合的 ANN 索引算法,可以在有限的内存下实现海量向量的高性能查询。于此同时,也在评估开源的 ScaNN、NGT 等向量索引算法的性能。
**易用性:**Milvus 易用性的提升体现在集群管理工具、多语言 SDK、部署工具、运维工具等许多方面,能够让大家快速上手使用是最有成就感的工作。
Zilliz 以重新定义数据科学为愿景,致力于打造一家全球领先的开源技术创新公司,并通过开源和云原生解决方案为企业解锁非结构化数据的隐藏价值。文章来源:https://www.toymoban.com/news/detail-724560.html
Zilliz 构建了 Milvus 向量数据库,以加快下一代数据平台的发展。Milvus 目前是 LF AI & Data 基金会的毕业项目,能够管理大量非结构化数据集。技术在新药发现、计算机视觉、推荐引擎、聊天机器人等方面具有广泛的应用。文章来源地址https://www.toymoban.com/news/detail-724560.html
到了这里,关于Annoy vs Milvus:哪个向量数据库更适合您的AI应用?知其然知其所以然的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!