作者:禅与计算机程序设计艺术
1.简介
Flink是一个开源的分布式流处理框架,它允许快速轻松地进行实时数据处理,提供了一个完整的数据流程解决方案。它支持低延迟的实时数据计算、高吞吐量的实时数据传输以及复杂事件处理(CEP)。Flink在Apache顶级项目中排名第二,同时也被很多公司用来构建实时的分析系统、实时报表系统和实时机器学习系统等。最近几年,Flink社区发展非常迅速,已经成为最热门的开源大数据平台之一。作为一个开源的分布式流处理框架,Flink在架构、功能和性能上都有着独特的优势。
本教程旨在带领读者了解Flink是什么,以及它如何帮助我们进行实时数据处理。
2.基本概念术语说明
Flink的文档和相关论文都经过精心编写,对一些关键术语和概念做了详细的解释。这里我们将简要介绍一下这些术语和概念。
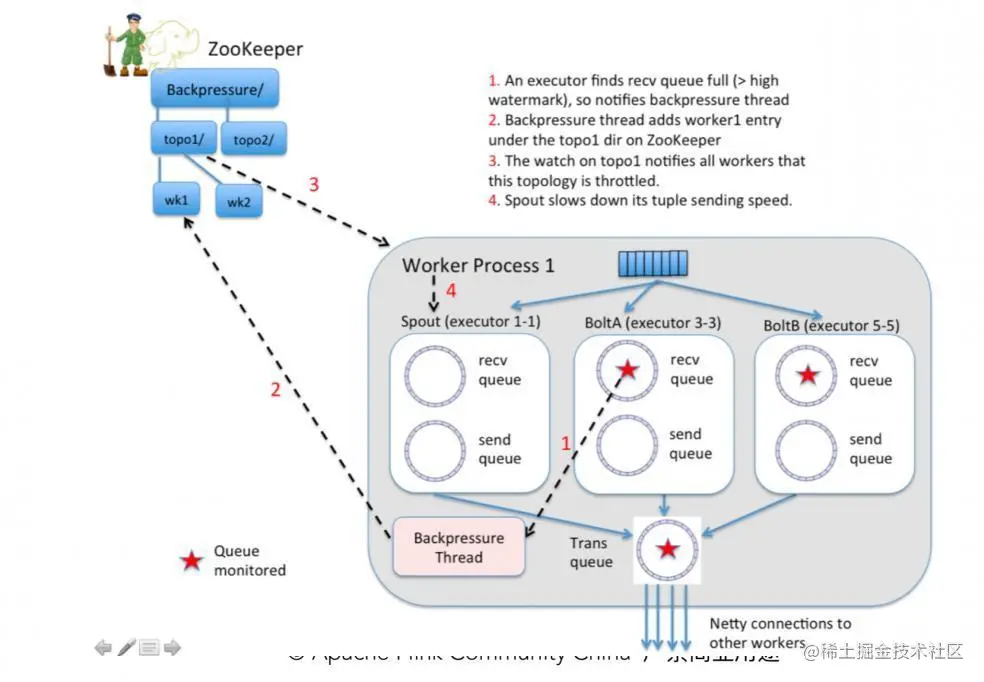
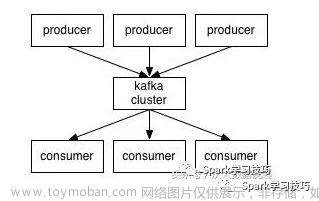
1.Stream processing: 数据流处理(英语:stream processing)是一种基于数据流的计算模型。数据会从源头到达目的地,通过一系列的处理过程一步步过滤、转换和输出结果。流处理通常采用无界数据集,即不断积累新数据。因此,流处理需要能够处理海量的数据。
2.Dataflow programming model: 流处理编程模型(英语:dataflow programming model)是一种用于描述数据流处理任务的编程模型。它采用离散的数据流模型,即数据在数据流中的传递。这种模型一般用于实现分布式计算系统,如 Apache Hadoop 和 Apache Spark。文章来源:https://www.toymoban.com/news/detail-724745.html
3.Task scheduling: 任务调度(英语:task scheduling)是指负责将作业分配给可用的执行资源。它使多个作业可以在同一时间片段同时运行&#x文章来源地址https://www.toymoban.com/news/detail-724745.html
到了这里,关于Introduction to Flink Streaming Platform for Big Data的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!