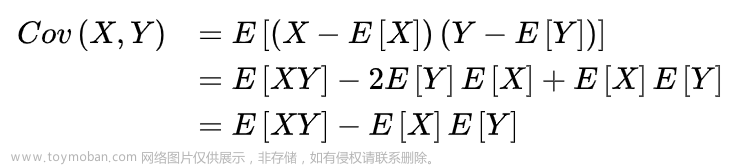接下来说说数据统计部分,这里主要介绍数据采样,标准差,协方差和相关系数的使用方法。
1、数据采样
Excel 的数据分析功能中提供了数据抽样的功能,如下图所示。Python 通过 sample 函数完成数据采样。
2、数据抽样
Sample 是进行数据采样的函数,设置 n 的数量就可以了。函数自动返回参与的结果。
1#简单的数据采样
2df_inner.sample(n=3)
3、简单随机采样
Weights 参数是采样的权重,通过设置不同的权重可以更改采样的结果,权重高的数据将更有希望被选中。这里手动设置 6 条数据的权重值。将前面 4 个设置为 0,后面两个分别设置为 0.5。
1 #手动设置采样权重
2 weights = [0, 0, 0, 0, 0.5, 0.5]
3 df_inner.sample(n=2, weights=weights)
手动设置采样权重1:从采样结果中可以看出,后两条权重高的数据被选中。
手动设置采样权重2:Sample 函数中还有一个参数 replace,用来设置采样后是否放回。
1 #采样后不放回
2 df_inner.sample(n=6, replace=False)
4、描述统计
Excel 中的数据分析中提供了描述统计的功能。Python 中可以通过 Describe 对数据进行描述统计。
Describe 函数是进行描述统计的函数,自动生成数据的数量,均值,标准差等数据。下面的代码中对数据表进行描述统计,并使用 round 函数设置结果显示的小数位。并对结果数据进行转置。
1#数据表描述性统计
2df_inner.describe().round(2).T
5、标准差
Python 中的 Std 函数用来接算特定数据列的标准差。
1 #标准差
2 df_inner[‘price’].std()
3 1523.3516556155596
6、协方差
Excel 中的数据分析功能中提供协方差的计算,python 中通过 cov 函数计算两个字段或数据表中各字段间的协方差。
Cov 函数用来计算两个字段间的协方差,可以只对特定字段进行计算,也可以对整个数据表中各个列之间进行计算。
1#两个字段间的协方差
2df_inner[‘price’].cov(df_inner[‘m-point’])
317263.200000000001
7、相关分析
Excel 的数据分析功能中提供了相关系数的计算功能,python 中则通过 corr 函数完成相关分析的操作,并返回相关系数。
1)相关系数
Corr 函数用来计算数据间的相关系数,可以单独对特定数据进行计算,也可以对整个数据表中各个列进行计算。相关系数在-1 到 1 之间,接近 1 为正相关,接近-1 为负相关,0 为不相关。
1 #相关性分析
2 df_inner[‘price’].corr(df_inner[‘m-point’])
3 0.77466555617085264
8、数据输出
第九部分是数据输出,处理和分析完的数据可以输出为 xlsx 格式和 csv 格式。
1)写入 excel
1#输出到 excel 格式
2df_inner.to_excel(‘excel_to_python.xlsx’, sheet_name=‘bluewhale_cc’)
2)写入CVS
1 #输出到 CSV 格式
2 df_inner.to_csv(‘excel_to_python.csv’)
在数据处理的过程中,大部分基础工作是重复和机械的,对于这部分基础工作,我们可以使用自定义函数进行自动化。以下简单介绍对数据表信息获取自动化处理。
1 #创建数据表
2 df = pd.DataFrame({‘id’:[1001,1002,1003,1004,1005,1006],
3’date’:pd.date_range(‘20130102’, periods=6),
4’city’:['Beijing ', ‘SH’, ’ guangzhou ', ‘Shenzhen’, ‘shanghai’, 'BEIJING '],
5 ‘age’:[23,44,54,32,34,32],
6 ‘category’:[‘100-A’,‘100-B’,‘110-A’,‘110-C’,‘210-A’,‘130-F’],
7 ‘price’:[1200,np.nan,2133,5433,np.nan,4432]},
8 columns =[‘id’,‘date’,‘city’,‘category’,‘age’,‘price’])
9
10 #创建自定义函数
11 def table_info(x):
12 shape=x.shape
13 types=x.dtypes
14 colums=x.columns
15 print(‘数据维度(行,列):\n’,shape)
16 print(‘数据格式:\n’,types)
17 print(‘列名称:\n’,colums)
18
19 #调用自定义函数获取 df 数据表信息并输出结果
20 table_info(df)
21
22 数据维度(行,列):
23 (6, 6)
24 数据格式:
25 id int64
26 date datetime64[ns]
27 city object
28 category object
29 age int64
30 price float64
31 dtype: object
32 列名称:
33 Index([‘id’, ‘date’, ‘city’, ‘category’, ‘age’, ‘price’], dtype=‘object’)
以上就是如何用Python做数据统计的全部内容了。文章来源:https://www.toymoban.com/news/detail-725147.html
文章来源:网络 版权归原作者所有
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系小编,我们将立即处理文章来源地址https://www.toymoban.com/news/detail-725147.html
到了这里,关于用Python做数据分析之数据统计的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!