介绍
puppeteer是一个可以控制chrome的库,可以模拟一些交互行为,以及进行前端自动化测试。
启动方法
启动浏览器,然后打开一个页面,之后跳转到一个网址打开页面
// Launch the browser
const browser = await puppeteer.launch({ headless: "new" });
// Create a page
const page = await browser.newPage();
// Go to your site
await page.goto("https://www.baidu.com");
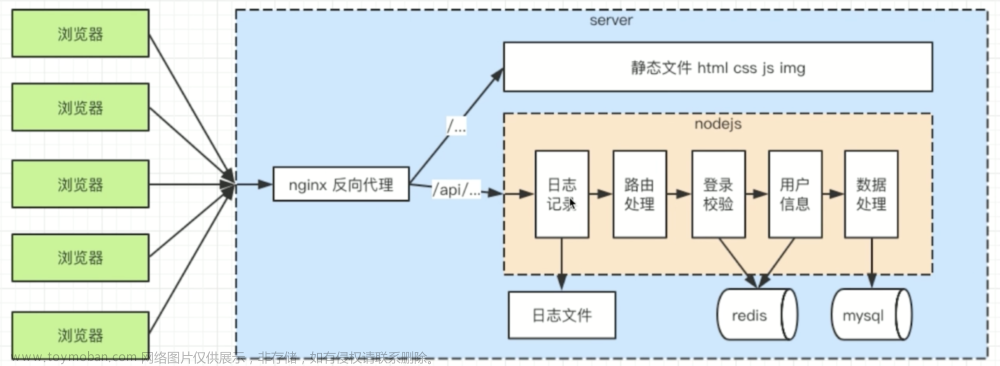
功能一、爬虫
优势
- 与普通爬虫相比它更简单,因为它用的是真实的chrome环境,不需要我们配置各种header的参数
- 它能等待js动态生成的内容之后进行爬虫
- 他能能够截图并保存为图片
如何实现
获取网页元素
这里用waitForSelector用选择器进行爬取,这边都是异步的函数,这也是puppeteer的优势,它可以等待一些动态变化之后再爬取
// Query for an element handle.
const element = await page.waitForSelector("span.title-content-title");
// Get the text content of the element
const textContent = await page.evaluate(
(element) => element.textContent,
element
);
截图
保存图片用screenshot方法,保存pdf用pdf方法(而且pdf是带链接的)
await page.screenshot({
path: "1.png",
fullPage: true,
});
await page.pdf({
path: "1.pdf",
fullPage: true,
});
爬虫小demo
let puppeteer = require("puppeteer");
(async () => {
// Launch the browser
const browser = await puppeteer.launch({ headless: "new" });
// Create a page
const page = await browser.newPage();
// Go to your site
await page.goto("https://www.baidu.com");
// Query for an element handle.
const element = await page.waitForSelector("span.title-content-title");
// Get the text content of the element
const textContent = await page.evaluate(
(element) => element.textContent,
element
);
console.log(textContent);
// Dispose of handle
await element.dispose();
// Close browser.
await browser.close();
})();
功能二、执行脚本
上面爬虫的那个evaluate方法就是执行脚本的方法,执行脚本之后可以返回一个值作为结果。
const result = await page.evaluate(() => {
// 在此处编写要执行的脚本
return xxx;
});
百度搜索脚本demo
// 执行脚本
const result = await page.evaluate(() => {
// 在此处编写要执行的脚本
let input = document.querySelector("input#kw");
input.value = "nodejs教学";
let search = document.querySelector("input#su");
search.click();
return "已搜索";
});
console.log(result); // 输出脚本执行结果
// 等待两秒等待页面加载完成
await page.waitForTimeout(2000);
await page.screenshot({
path: "nodejs.png",
fullPage: true,
});
结果生成的图片 文章来源:https://www.toymoban.com/news/detail-725454.html
文章来源:https://www.toymoban.com/news/detail-725454.html
功能三、获取cookie(这个只能是模拟浏览器当前进入网页的cookie不是平时用的下载的的浏览器的cookie)
let cookie = await page.cookies();
功能四、监控网页,进行性能分析
// 跟踪
// 启动跟踪
await page.tracing.start({ path: "trace.json" });
。。。。。。
// 停止跟踪
await page.tracing.stop();
// 导出跟踪结果
const tracingData = await page.tracing.export();
// 保存跟踪结果为JSON文件
require('fs').writeFileSync('trace.json', tracingData);
这里生成的json文件可以通过浏览器的F12里的性能里上传按钮上传,之后就能看到可视化的性能分析,结果图如下 文章来源地址https://www.toymoban.com/news/detail-725454.html
文章来源地址https://www.toymoban.com/news/detail-725454.html
到了这里,关于puppeteer学习笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!