目录
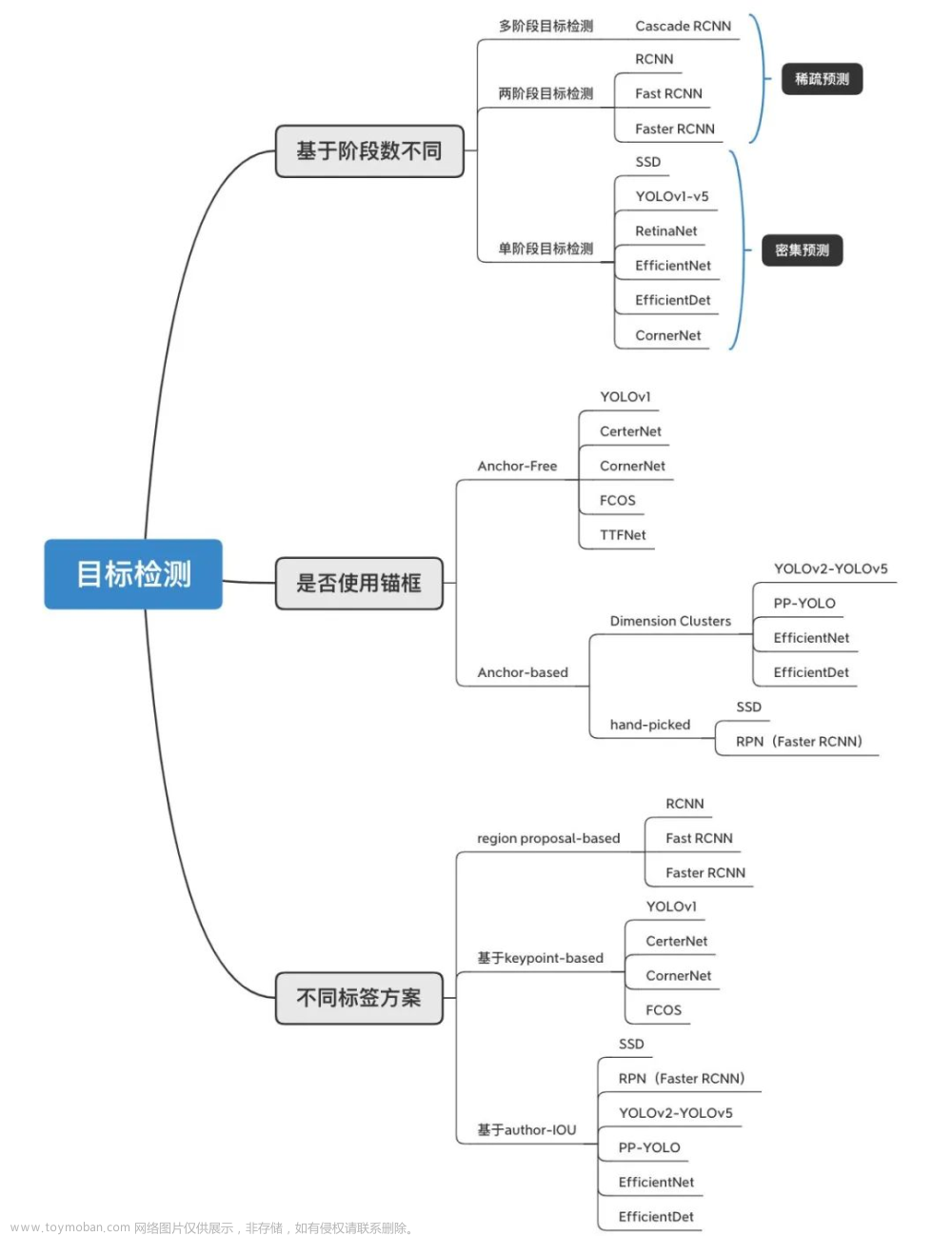
问题1:目标检测的算法分类
问题2:卷积神经网络的组成
问题3:输入层的作用
问题4:卷积层作用
问题5:卷积核类型
问题6:1×1卷积核作用
问题7:卷积核是否越大越好
问题8:棋盘效应及解决办法
问题9:如何减少卷积层参数
问题10:神经网络可视化工具
问题11:池化层作用
问题12:卷积层和池化层的区别
问题13:激活函数层作用
问题14:全连接层作用
问题15:如何提高卷积神经网络的泛化能力
问题16:讲一下BN、LN、IN、GN这几种归一化方法
问题17:softmax公式,如果乘上一个系数a, 则概率分布怎么变?
问题18:如何解决正负样本不平衡问题
问题19:训练网络不收敛的原因
问题20:优化算法,Adam, Momentum, Adagard,SGD特点
问题21:小目标难检测原因
问题1:目标检测的算法分类
基于深度学习的目标检测算法主要分为两类
two-stage目标检测算法
- 主要思路:先进行区域(Region Proposal,RP)生成,再通过卷积神经网络进行样本分类。
- 任务路线:特征提取一生成目标候选区域一分类/定位回归。
one-stage 目标检测算法
- 主要思路:不用进行区域生成,直接在网络中提取特征来预测物体分类和位置
- 任务路线:特征提取一分类/定位回归。
问题2:卷积神经网络的组成
卷积神经网络的基本结构由以下几个部分组成:输入层(input layer),卷积层(convolution layer),池化层(pooling layer),激活函数层和全连接层(full-connection layer)。

问题3:输入层的作用
在处理图像的CNN中,输入层一般代表了一张图片的像素矩阵。可以用三维矩阵代表一张图片。三维矩阵的长和宽代表了图像的大小,而三维矩阵的深度代表了图像的色彩通道。比如黑白图片的深度为1,而在RGB色彩模式下,图像的深度为3。
问题4:卷积层作用
卷积神经网络的核心是卷积层,卷积层的核心部分是卷积操作。
对图像(不同的数据窗口数据)和滤波矩阵(一组固定的权重:因为每个神经元的多个权重固定,所以又可以看做一个恒定的滤波器filter)做内积(逐个元素相乘再求和)的操作就是所谓的卷积操作,也是卷积神经网络的名字来源。
在CNN中,滤波器filter对局部输入数据进行卷积计算。每计算完一个数据窗口内的局部数据后,数据窗口不断平移滑动,直到计算完所有数据。这个过程中,有这么几个参数:
- 深度depth:神经元个数,决定输出的depth厚度。同时代表滤波器个数。
- 步长stride:决定滑动多少步可以到边缘。
- 填充值zero-padding:在外围边缘补充若干圈0,方便从初始位置以步长为单位可以刚好滑到末尾位置,通俗地讲就是为了总长能被步长整除。

问题5:卷积核类型
转置(Transposed)卷积
有时我们需要对输入进行如增加尺寸(也称为“上采样”)等处理。先对原始特征矩阵进行填充,使其维度扩大到适配卷积目标输出维度,然后进行普通的卷积操作的一个过程。转置卷积常见于目标检测领域中对小目标的检测和图像分割领域中还原输入图像的尺度。
扩张/空洞(Dilated/Atrous)卷积
引入一个称作扩张率(Dilation Rate)的参数,使同样尺寸的卷积核可以获得更大的感受视野,相应地,在相同感受视野的前提下比普通卷积采用更少的参数。同样是 3x3 的卷积核尺寸,扩张卷积可以提取 5x5 范围的区域特征,在实时图像分割领域广泛应用。
可分离卷积
标准的卷积操作是同时对原始图像 HxWxC 三个方向的卷积运算,假设有3个相同尺寸的卷积核,这样的卷积操作需要用到的参数为 HxWxCxK个;若将长、宽与深度方向的卷积操作进行分离操作,变为先与 HXW方向卷积,再与C方向卷积的两步卷积操作,则同样有 K 个相同的尺寸的卷积核,只需要 (HxW+C) XK个参数,便可得到同样的输出尺度。可分离卷积 (SeperableConvolution)通常应用在模型压缩或一些轻量的卷积神经网络中,如MobileNet、Xception 等



问题6:1×1卷积核作用
对于1x1卷积核的作用主要可以归纳为以下几点
- 增加网络深度(增加非线性映射次数)
- 升维/降维
- 跨通道的信息交互
- 减少卷积核参数(简化模型)

问题7:卷积核是否越大越好
设置较大的卷积核可以获取更大的感受野。但是这种大卷积核反而会导致计算量大幅增加,不利于训练更深层的模型,相应的计算性能也会降低。后来的卷积经网络(VGG、GoogLeNet 等),发现通过堆叠2个3X3 卷积核可以获得与 5X5 卷积核同的感受视野,同时参数量会更少 (3X3X2+1<5X5X1+1),3X3 卷积核被广泛应用许多卷积神经网络中。
但是,这并不表示更大的卷积核就没有作用,在某些领域应用卷积神经网络时仍然可以采用较大的卷积核。在将卷积神经网络应用在自然语言处理领域时,神经网络通常都是由较为浅层的卷积层组成的,但是文本特征有时又需要有较广的感受野让模型能够组合更多的特征(如词组和字符),此时接采用较大的卷积核将是更好的选择。
综上所述,卷积核的大小并没有绝对的优劣,需要视具体的应用场景而定,但是极大和极小的卷积核都是不合适的,单独的 1X1极小卷积核只能用作分离卷积而不能对输入的原始特征进行有效的组合,极大的卷积核通常会组合过多的无意义特征,从而浪费大量的计算资源。
问题8:棋盘效应及解决办法
由以上现象得知,当过滤器尺寸无法被卷积步长整除时,转置卷积就会出现不均匀重叠,造成图像中某个部位的颜色比其他部位更深,因而会带来棋盘效应。
如何避免和减轻棋盘效应:
(1) 确认使用的过滤器的大小是能够被卷积步长整除的,从而来避免重叠问题
(2) 可以采用卷积步长为 1的转置卷积来减轻棋盘效应。
参考文章:卷积操作总结(三)—— 转置卷积棋盘效应产生原因及解决 - 知乎

问题9:如何减少卷积层参数
- 使用堆叠小卷积核代替大卷积核:VGG 网络中 2个 3X3 的卷积核可以代替 1个5X5 的卷积核。
- 使用分离卷积操作: 将原本 KXKXC 的卷积操作分离为 KXKX1和1X1XC的两部分操作。
- 添加 1X1的卷积操作:与分离卷积类似,但是通道数可变,在 KXKXC 卷积前添加1X1XC2的卷积核。
- 在卷积层前使用池化操作:池化可以降低卷积层的输入特征维度
问题10:神经网络可视化工具
神经网络的可视化工具有Netron、draw_convnet、NNSVG、PlotNeuralNet、Tensorboard、Caffe等。
参考文章:【深度学习 | 机器学习】干货满满 | 近万字总结了 12 个令人惊艳的神经网络可视化工具!_旅途中的宽~的博客-CSDN博客
问题11:池化层作用
池化层又称为降采样层(Downsampling Layer),作用是对感受野内的特征进行筛选提取区域内最具代表性的特征,能够有效地减小输出特征尺度,进而减少模型所需要的参数量。 主要有平均池化(Average Pooling)、最大池化(Max Pooling)等。简单来说池化就是在该区域上指定一个值来代表整个区域。池化层的超参数:池化窗口和池化步长。池化操作也可以看做是一种卷积操作。

问题12:卷积层和池化层的区别
卷积层和池化层在结构上具有一定的相似性,都是对感受野内的特征进行提取,并且根据步长设置获取到不同维度的输出,但是其内在操作是有本质区别
卷积层 池化层 结构 零填充时输出维度不变,而通道数改变 通常特征维度会降低,通道数不变 稳定性 输入特征发生细微改变时,输出结果会改变 感受野内的细微变化不影响输出结果 作用 感受野内提取局部关联特征 感受野内提取泛化特征,降低维度 参数量 与卷积核尺寸、卷积核个数相关 不引入额外参数
问题13:激活函数层作用
激活函数(非线性激活函数,如果激活函数使用线性函数的话,那么它的输出还是一个线性函数。)但使用非线性激活函数可以得到非线性的输出值。常见的激活函数有Sigmoid、tanh和Relu等。一般我们使用Relu作为卷积神经网络的激活函数。Relu激活函数提供了一种非常简单的非线性变换方法,函数图像如下所示:

问题14:全连接层作用
在经过多轮卷积层和池化层的处理之后,在CNN的最后一般会由1到2个全连接层来给出最后的分类结果。经过几轮卷积层和池化层的处理之后,可以认为图像中的信息已经被抽象成了信息含量更高的特征。我们可以将卷积层和池化层看成自动图像特征提取的过程。在提取完成之后,仍然需要使用全连接层来完成分类任务

问题15:如何提高卷积神经网络的泛化能力
- 使用更多的数据:竟可能标注更多的训练数据,这是提高泛化能力最理想的方法,更多的数据让模型得到更充分的学习,自然提高了泛化能力。
- 使用更大的batch_size:在相同迭代次数和学习率的条件下,每批次采用更多的数据将有助于模型更好的学习到正确的模式,模型输出结果也会更加稳定。
- 数据过采样:很多情况下我们拿到手的数据都存在类别不均匀的情况,模型这个时候过多的拟合某类数量多的数据导致其输出结果偏向于该类数据,此时如果我们过采样其他类别的数据,使得数据量比较均衡可以一定程度提高泛化能力。
- 数据增强:数据增强是指在数据有限的情况通过一些几何操作对图像进行变换,使得同类数据的表现形式更加丰富,以此提高模型的泛化能力。
- 修改损失函数:这方面有大量的工作,如目标检测中的Focal Loss, GHM Loss,IOU Loss等都是为了提升模型的泛化能力。
- 修改网络:如果网络过浅并且参数量过少往往会使得模型的泛化能力不足导致欠拟合,此时一般考虑使用简单的堆叠卷积层增加网络的参数,提高模型的特征提取能力。而如果网络过深且训练数据量比较少,那么就容易导致模型过拟合,此时一般需要简化网络结构减少网络层数或者使用resnet的残差结构以及BN层。
- 权重惩罚:权重惩罚也即是正则化操作,一般是在损失函数中添加一项权重矩阵的正则项作为惩罚项,用来惩罚损失值较小时网络权重过大的情况,此时往往是网络权值过拟合了数据样本。
- Dropout策略:如果网络最后有全连接层可以使用Dropout策略,相当于对深度学习模型做了Ensemble,有助于提高模型的泛化能力。
问题16:讲一下BN、LN、IN、GN这几种归一化方法
BN
- BatchNormalization,假设特征在不同输入以及H、W层级上是均匀分布的,所以在NHW上统计每个channel的均值和方差,参数量为2C;
- 缺点是容易受到batch内数据分布影响,如果batch_size小的话,计算的均值和方差不具有代表性。而且不适用于序列模型中,因为序列模型中通常各个样本的长度都是不同的。此外当训练数据和测试数据分布有差别时也并不适用。
LN
- Layer Normalization,LN是独立于batch size的算法,样本数多少不会影响参与LN计算的数据量,从而解决BN的两个问题;
- 缺点是在BN和LN都能使用的场景中,BN的效果一般优于LN,原因是基于不同数据,同一特征得到的归一化特征更不容易损失信息。
IN
- Instance Normalization,IN的计算就是把每个HW单独拿出来归一化处理,不受通道和batch_size 的影响,常用在风格化迁移,因为它统计了每个样本的每个像素点的信息;
- 缺点是如果特征图可以用到通道之间的相关性,那么就不建议使用它做归一化处理。
GN
- Group Normalization,其首先将channel分为许多组(group),对每一组做归一化,及先将feature的维度由[N, C, H, W]reshape为[N, G,C//G , H, W],归一化的维度为[C//G , H, W];
- GN的归一化方式避开了batch size对模型的影响,特征的group归一化同样可以解决 I n t e r n a l InternalInternal C o v a r i a t e CovariateCovariate S h i f t ShiftShift 的问题,并取得较好的效果。

问题17:softmax公式,如果乘上一个系数a, 则概率分布怎么变?
当a>1时变陡峭,当a<1是变平滑

问题18:如何解决正负样本不平衡问题
- 过采样:对训练集里面样本数量较少的类别(少数类)进行过采样,合成新的样本来缓解类不平衡。
- 欠采样:对训练集里面样本数量较多的类别(多数类)进行欠采样,抛弃一些样本来缓解类不平衡。
- 合成新的少数类
问题19:训练网络不收敛的原因
数据处理原因
- 没有做数据归一化;
- 没有做数据预处理;
- 没有使用正则化;
参数设置原因
- Batch Size设的太大;
- 学习率设的不合适;
网络设置原因
- 网络存在坏梯度,比如当Relu对负值的梯度为0,反向传播时,梯度为0表示不传播;
- 参数初始化错误;
- 网络设定不合理,网络太浅或者太深;
问题20:优化算法,Adam, Momentum, Adagard,SGD特点
- Adagard在训练的过程中可以自动变更学习的速率,设置一个全局的学习率,而实际的学习率与梯度历史平方值总和的平方根成反比。用adagrad将之前梯度的平方求和再开根号作为分母,会使得一开始学习率呈放大趋势,随着训练的进行学习率会逐渐减小。
- Momentum参考了物理中动量的概念,前几次的梯度也会参与到当前的计算中,但是前几轮的梯度叠加在当前计算中会有一定的衰减。用来解决梯度下降不稳定,容易陷入鞍点的缺点。
- SGD为随机梯度下降,每一次迭代计算数据集的mini-batch的梯度,然后对参数进行跟新。优点是更新速度快,缺点是训练不稳定,准确度下降。
- Adam利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率,在经过偏置的校正后,每一次迭代后的学习率都有个确定的范围,使得参数较为平稳,结合momentum和adagrad两种算法的优势。
问题21:小目标难检测原因
小目标在原图中尺寸比较小,通用目标检测模型中,一般的基础骨干神经网络(VGG系列和Resnet系列)都有几次下采样处理,导致小目标在特征图的尺寸基本上只有个位数的像素大小,导致设计的目标检测分类器对小目标的分类效果差。
小目标在原图中的数量较少,检测器提取的特征较少,导致小目标的检测效果差。神经网络在学习中被大目标主导,小目标在整个学习过程被忽视,导致导致小目标的检测效果差。
Tricks
(1) data-augmentation.简单粗暴,比如将图像放大,利用 image pyramid多尺度检测,最后将检测结果融合.缺点是操作复杂,计算量大,实际情况中不实用;
(2) 特征融合方法:FPN这些,多尺度feature map预测,feature stride可以从更小的开始;
(3)合适的训练方法:CVPR2018的SNIP以及SNIPER;
(4)设置更小更稠密的anchor,回归的好不如预设的好, 设计anchor match strategy等,参考S3FD;
(5)利用GAN将小物体放大再检测,CVPR2018有这样的论文;
(6)利用context信息,建立object和context的联系,比如relation network;
(7)有密集遮挡,如何把location 和Classification 做的更好,参考IoU loss, repulsion loss等.
(8)卷积神经网络设计时尽量采用步长为1,尽可能保留多的目标特征。
(9)matching strategy。对于小物体不设置过于严格的 IoU threshold,或者借鉴 Cascade R-CNN 的思路。
问题22:描述YOLOv5框架
1 网络结构
YOLOv5的网络结构主要由以下几部分组成:
- Backbone: New CSP-Darknet53
- Neck: SPPF, New CSP-PAN
- Head: YOLOv3 Head
下面是我根据yolov5l.yaml绘制的网络整体结构,YOLOv5针对不同大小(n, s, m, l, x)的网络整体架构都是一样的,只不过会在每个子模块中采用不同的深度和宽度。还需要注意一点,官方除了n, s, m, l, x版本外还有n6, s6, m6, l6, x6,区别在于后者是针对更大分辨率的图片比如1280x1280,当然结构上也有些差异,后者会下采样64倍,采用4个预测特征层,而前者只会下采样到32倍且采用3个预测特征层。
通过和YOLOv4对比,其实YOLOv5在Backbone部分没太大变化。但是YOLOv5在v6.0版本后相比之前版本有一个很小的改动,把网络的第一层(原来是Focus模块)换成了一个6x6大小的卷积层,两者在理论上其实等价的。下图是原来的Focus模块(和之前Swin Transformer中的Patch Merging类似),将每个2x2的相邻像素划分为一个patch,然后将每个patch中相同位置(同一颜色)像素给拼在一起就得到了4个feature map,然后在接上一个3x3大小的卷积层。这和直接使用一个6x6大小的卷积层等效。
在Neck部分的变化还是相对较大的,首先是将SPP换成成了SPPF,两者的作用是一样的,但后者效率更高。SPP结构如下图所示,是将输入并行通过多个不同大小的MaxPool,然后做进一步融合,能在一定程度上解决目标多尺度问题。
而
SPPF结构是将输入串行通过多个5x5大小的MaxPool层,这里需要注意的是串行两个5x5大小的MaxPool层是和一个9x9大小的MaxPool层计算结果是一样的,串行三个5x5大小的MaxPool层是和一个13x13大小的MaxPool层计算结果是一样的。
2 数据增强
在YOLOv5代码里,关于数据增强策略还是挺多的,这里简单罗列部分方法:
- Mosaic,将四张图片拼成一张图片
- Copy paste,将部分目标随机的粘贴到图片中,前提是数据要有
segments数据才行,即每个目标的实例分割信息。下面是Copy paste原论文中的示意图。
- MixUp,就是将两张图片按照一定的透明度融合在一起,具体有没有用不太清楚,毕竟没有论文,、也没有消融实验。代码中只有较大的模型才使用到了
MixUp,而且每次只有10%的概率会使用到。Albumentations,主要是做些滤波、直方图均衡化以及改变图片质量等等
Augment HSV(Hue, Saturation, Value),随机调整色度,饱和度以及明度。
Random horizontal flip,随机水平翻转
3 训练策略
在YOLOv5源码中使用到了很多训练的策略,这里简单总结几个我注意到的点,还有些没注意到的请大家自己看下源码:
- Multi-scale training(0.5~1.5x),多尺度训练,假设设置输入图片的大小为640 × 640,训练时采用尺寸是在0.5 × 640 ∼ 1.5 × 640之间随机取值,注意取值时取得都是32的整数倍(因为网络会最大下采样32倍)。
- AutoAnchor(For training custom data),训练自己数据集时可以根据自己数据集里的目标进行重新聚类生成Anchors模板。
- Warmup and Cosine LR scheduler,训练前先进行Warmup热身,然后在采用Cosine学习率下降策略。
- EMA(Exponential Moving Average),可以理解为给训练的参数加了一个动量,让它更新过程更加平滑。
- Mixed precision,混合精度训练,能够减少显存的占用并且加快训练速度,前提是GPU硬件支持。
- Evolve hyper-parameters,超参数优化,没有炼丹经验的人勿碰,保持默认就好。
4 损失计算
YOLOv5的损失主要由三个部分组成:文章来源:https://www.toymoban.com/news/detail-725600.html
- Classes loss,分类损失,采用的是BCE loss,注意只计算正样本的分类损失。
- Objectness loss,obj损失,采用的依然是BCE loss,注意这里的obj指的是网络预测的目标边界框与GT Box的CIoU。这里计算的是所有样本的obj损失。
- Location loss,定位损失,采用的是CIoU loss,注意只计算正样本的定位损失
文章来源地址https://www.toymoban.com/news/detail-725600.html







到了这里,关于SLAM面试笔记(8) — 计算机视觉面试题的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!