作者:禅与计算机程序设计艺术
《基于残差网络的人工智能文本分类方法》
- 引言
1.1. 背景介绍
随着互联网和电子商务的快速发展,文本分类技术在自然语言处理领域取得了重要地位。在实际应用中,人们需要处理大量的文本数据,例如新闻报道、社交媒体内容、公司业务邮件等。自动化文本分类方法可以帮助人们快速识别文本主题、提取关键信息,从而提高文本分析的效率。
1.2. 文章目的
本文旨在介绍一种基于残差网络的人工智能文本分类方法。残差网络是一种先进的神经网络结构,它在图像识别任务中表现优异。通过将残差网络应用于文本分类问题,可以实现高效、准确的文本分类。
1.3. 目标受众
本文主要面向对自然语言处理领域有一定了解的技术人员、研究人员和爱好者。需要了解基本的机器学习概念、熟悉常用的人工智能框架(如 TensorFlow、PyTorch)的读者,可以更容易地理解本文内容。
- 技术原理及概念
2.1. 基本概念解释
文本分类是指根据给定的文本内容,将其归类到预定义的类别中。其中,类别是一种预定义的标签,例如新闻分类、情感分析等。文本分类问题可以分为无监督、监督和半监督三种类型。无监督文本分类关注的是文本数据本身,不涉及预定义类别的标签;监督文本分类则需要给定类别的标签,帮助模型学习分类规则;半监督文本分类则是将无监督和监督文本分类的优点结合起来。
2.2. 技术原理介绍:算法原理,操作步骤,数学公式等文章来源:https://www.toymoban.com/news/detail-725983.html
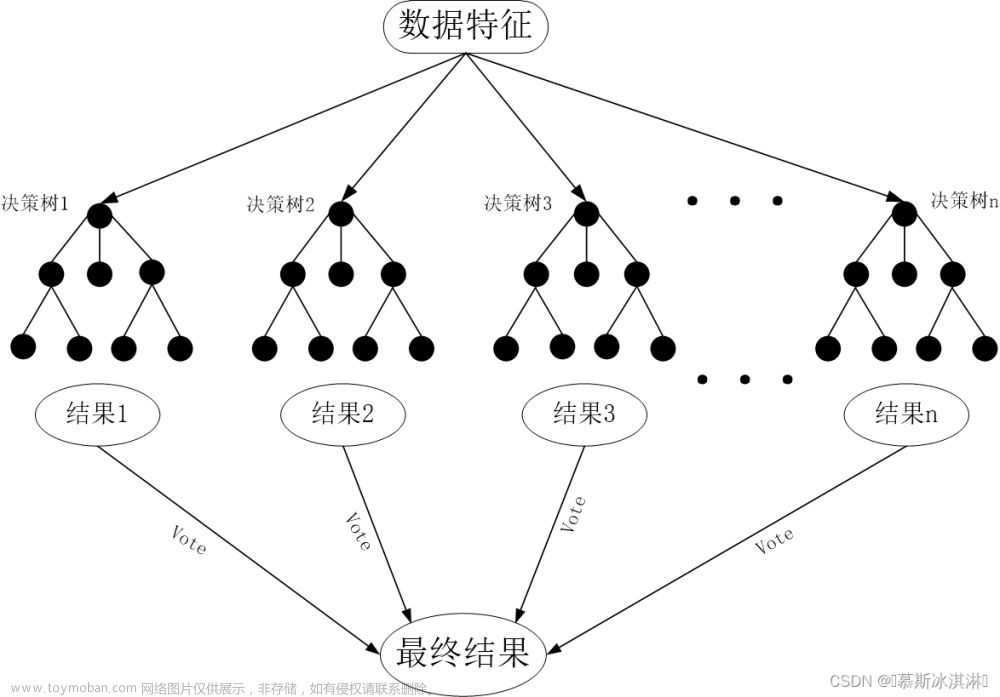
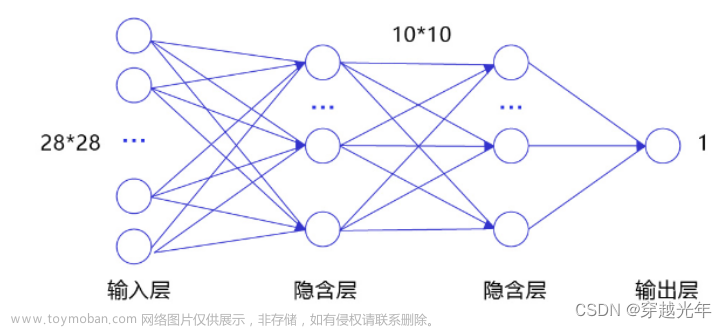
本文将介绍一种基于残差网络的文本分类方法。残差网络是一种用于图像识别任务的神经网络结构,其核心思想是通过引入残差来提高模型的泛化能力。在本篇文章中&#x文章来源地址https://www.toymoban.com/news/detail-725983.html
到了这里,关于基于残差网络的人工智能文本分类方法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!



![[当人工智能遇上安全] 8.基于API序列和机器学习的恶意家族分类实例详解](https://imgs.yssmx.com/Uploads/2024/02/703877-1.jpeg)
![[当人工智能遇上安全] 9.基于API序列和深度学习的恶意家族分类实例详解](https://imgs.yssmx.com/Uploads/2024/02/763745-1.jpeg)



