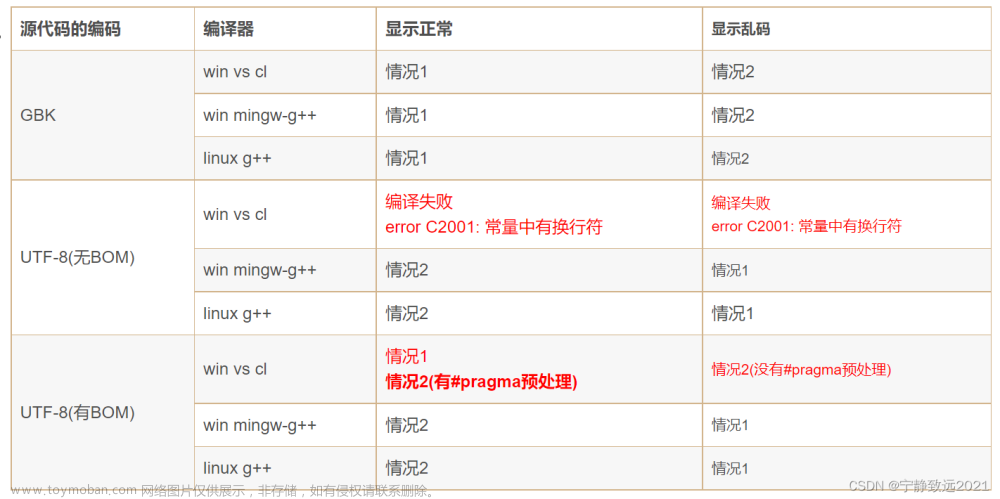
一、问题
当我学习UTF-16编码时,我用notepadd++进行学习,然后用二进制编辑器打开发现
我输入我时,按照编码规则,应该是62 11,但是却变成了4个字节,前面多了FFFE
二、原因
大端序和小端序是CPU处理多字节数的不同方式。
UTF-8以字节为编码单元,没有字节序的问题。UTF-16以两个字节为编码单元,在解释一个UTF-16文本前,首先要弄清楚每个编码单元的字节序。例如收到一个“奎”的Unicode编码是594E,“乙”的Unicode编码是4E59。如果我们收到UTF-16字节流“594E”,那么这是“奎”还是“乙”?
在UCS 编码中有一个叫做”ZERO WIDTH NO-BREAK SPACE”的字符,它的编码是FEFF。而FFFE在UCS中是不存在的字符,所以不应该出现在实际传输中。UCS规范建议我们在传输字节流前,先传输字符”ZERO WIDTH NO-BREAK SPACE”。这样如果接收者收到FEFF,就表明这个字节流是大端序的;如果收到FFFE,就表明这个字节流是 小端序 的。因此字符”ZERO WIDTH NO-BREAK SPACE”又被称作BOM(Byte Order Mark | 字节顺序标记)
所以上面输入我时出现FFFE表明这是小端序, 低字节在前,高字节在后 62 11 存储为 11 62
 文章来源:https://www.toymoban.com/news/detail-726509.html
文章来源:https://www.toymoban.com/news/detail-726509.html
三、总结
notepad++在使用UTF-16编码时,会自动加上 BOM 来标识大端序和小端序
如果是 FF EF 就是小端序
如果是 FE FF 就是大端序文章来源地址https://www.toymoban.com/news/detail-726509.html
四、参考
- https://www.shenyanchao.cn/blog/2012/10/23/bom-in-utf8-text/
到了这里,关于notepad++进行UTF-16编码的时候前面出现FFFE的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!