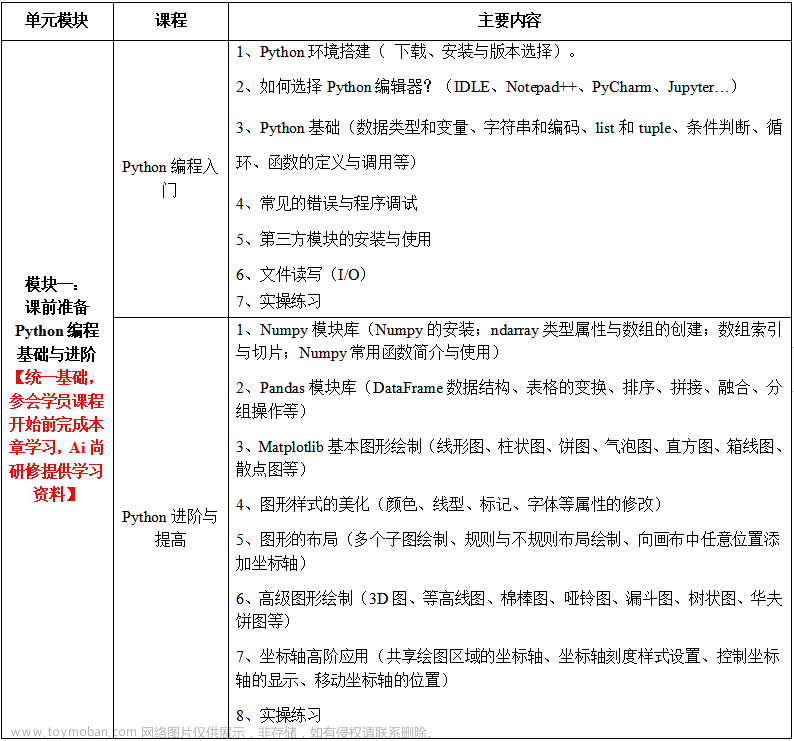
1 信息熵
信息论的创始人,香农是密歇根大学学士,麻省理工学院博士。
1948年,香农发表了划时代的论文——通信的数学原理,奠定了现代信息论的基础。
信息的单位:比特
1.1 比特化(Bits)
- 假设存在一组随机变量X,各个值出现的概率关系如图;
- 现在有一组由X变量组成的序列:BACADDCBAC…;如果现在希望将这个序列转换为二进制来进行网络传输,那么我们得到一个得到一个这样的序列:01001000111110010010…
- 结论:在这种情况下,我们可以使用两个比特位来表示一个随机变量。

- 而当X变量出现的概率值不一样的时候,对于一组序列信息来讲,每个变量平均需要多少个比特位来描述呢??

1.2 一般化的比特化(Bits)
- 假设现在随机变量X具有m个值,分别为:V1,V2,…V;并于且各个值出现的概率如下表所示;那么对于一组序列信息来讲,每个变量平均需要多少个比特位来描述呢??

- 可以使用这些变量的期望来表示每个变量需要多少个比特位来描述信息:

1.3 信息熵(Entropy)
H(X)叫做随机X的信息熵,单位为比特:m为类别

- 信息量:指的是一个样本/事件所蕴含的信息,如果一个事件的概率越大,那么就可以认为该事件所蕴含的信息越少。极端情况下,比如:“太阳从东方升起”,因为是确定事件,所以不携带任何信息量。
- 信息熵:1948年,香农引入信息熵;一个系统越是有序,信息熵就越低,一个系统越是混乱,信息熵就越高,所以信息熵被认为是一个系统有序程度的度量。
1.3.1 熵越大混乱程度越大
概率越大,可能性越大,但是信息量越小,不确定性越小,熵越小,自信息越小
例子:这个很容易理解,举一个极端的例子,如果相空间所有态中只有一个态的概率是1,其它态概率都是0,那这个系统的熵是0,完全没有混乱度,系统只能取这个态。反之,什么时候熵最大呢?当所有态概率相等的时候最大,这个时候系统对取什么态没有偏向性,所以混乱度最大。
- 信息熵就是用来描述系统信息量的不确定度。
- High Entropy(高信息熵):表示随机变量X是均匀分布的,各种取值情况是等概率出现的。
- Low Entropy(低信息熵):表示随机变量X各种取值不是等概率出现。可能出现有的事件概率很大,有的事件概率很小。

1.4 条件熵H(YIX)

- 给定条件X的情况下,所有不同x值情况下Y的信息熵的平均值叫做条件熵。另外一个公式如下所示:

- 事件(X,Y)发生所包含的熵,减去事件X单独发生的熵,即为在事件X发生的前提下,Y发生"新"带来的熵,这个也就是条件熵本身的概念。

2 决策树
2.1 什么是决策树
- 决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构建决策树来进行分析的一种方式,是一种直观应用概率分析的一种图解法;决策树是一种预测模型,代表的是对象属性与对象值之间的映射关系;决策树是一种树形结构,其中每个内部节点表示一个属性的测试,每个分支表示一个测试输出,每个叶节点代表一种类别;决策树是一种非常常用的有监督的分类算法。
- 决策树的决策过程就是从根节点开始,测试待分类项中对应的特征属性,并按照其值选择输出分支,直到叶子节点,将叶子节点的存放的类别作为决策结果。
- 决策树分为两大类:分类树和回归树,前者用于分类标签值,后者用于预测连续值,常用算法有ID3,C4.5,CART等
2.2 决策树构建过程(重点)
-
决策树算法的重点就是决策树的构造;决策树的构造就是进行属性选择度量,确定各个特征属性之间的拓扑结构(树结构);构建决策树的关键步骤就是分裂属性,分裂属性是指在某个节点按照某一类特征属性的不同划分构建不同的分支,其目标就是让各个分裂子集尽可能的 “纯” (让一个分裂子类中待分类的项尽可能的属于同一个类别)。
-
构建步骤如下:
1,将所有的特征看成一个一个的节点;
2,遍历当前特征的每一种分割方式,找到最好的分割点;将数据划分为不同的子节点,eg:N1、N2 ···Nm ;计算划分之后所有子节点的 “纯度” 信息;
3,使用第二步遍历所有特征,选择出最优的特征以及该特征的最优的划分方式;得出最终的子节点:N1、N2 ···Nm
4,对子节点N1、N2 ···Nm分别继续执行2-3步,直到每个最终的子节点都足够 ”纯“ 。
2.3 决策树特征属性类型(离散、连续)
根据特征属性的类型不同,在构建决策树的时候,采用不同的方式,具体如下:
- 属性是离散值,而且不要求生成的是二叉决策树,此时一个属性就是一个分支
- 属性是离散值,而且要求生成的是二叉决策树,此时使用属性划分的子集进行测试,按照"属于此子集”和"不属于此子集"分成两个分支
- 属性是连续值,可以确定一个值作为分裂点split_point,按照 >split_point 和 <=split_point 生成两个分支
2.4 决策树分割属性选择
- 决策树算法是一种"贪心"算法策略,只考虑在当前数据特征情况下的最好分割方式,不能进行回溯操作。
- 对于整体的数据集而言,按照所有的特征属性进行划分操作,对所有划分操作的结果集的“纯度"进行比较,选择“纯度"越高的特征属性作为当前需要分割的数据集进行分割操作,持续迭代,直到得到最终结果。决策树是通过"纯度"来选择分割特征属性点的。
2.5 决策树量化纯度
- 决策树的构建是基于样本概率和纯度进行构建操作的,那么进行判断数据集是否"纯"可以通过三个公式进行判断,分别是Gini系数、熵(Entropy)、错误率,这三个公式值越大,表示数据越"不纯";越小表示越"纯";实践证明这三种公式效果差不多,一般情况使用熵公式

2.5.1 决策树的划分依据之一-信息增益(越大越好)
- 当计算出各个特征属性的量化纯度值后使用信息增益度来选择出当前数据集的分割特征属性;如果信息增益度的值越大,表示在该特征属性上会损失的纯度越大,那么该属性就越应该在决策树的上层,计算公式为:

- Gain:A为特征对训练数据集D的信息增益,定义为集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(DIA)之差
注:信息增益表示得知特征X的信息而使得类Y的信息的不确定性减少的程度;即信息增益越大越好
2.6 决策树算法的停止条件
-
决策树构建的过程是一个递归的过程,所以必须给定停止条件,否则过程将不会进行停止,一般情况有两种停止条件:
- 当每个子节点只有一种类型的时候停止构建
- 当前节点中记录数小于某个阈值,同时迭代次数达到给定值时,停止构建过程,此时使用 max(p(i)) 作为节点的对应类型
-
方式一可能会使树的节点过多,导致过拟合(Overfiting)等问题;比较常用的方式是使用方式二作为停止条件
2.7 决策树算法效果评估
- 决策树的效果评估和一般的分类算法一样,采用混淆矩阵来进行计算准确率、召回率、精确率等指标
- 也可以采用叶子节点的纯度值总和来评估算法的效果,值越小,效果越好


2.8 决策树直观理解结果计算

2.9 决策树的优缺点以及改进
优点:
- 简单的理解和解释,树木可视化。
- 需要很少的数据准备,其他技术通常需要数据归一化
缺点:
- 决策树学习者可以创建不能很好地推广数据的过于复杂的树,这被称为过拟合。
- 决策树可能不稳定,因为数据的小变化可能会导致完全不同的树被生成
改进:
- 减枝cart算法
- 随机森林
3 决策树生成算法
建立决策树的主要是以下三种算法
- ID3
- C4.5
- CART(Classification And Regression Tree)
3.1 ID3算法(信息增益 最大的准则)
- ID3算法是决策树的一个经典的构造算法,内部使用信息熵以及信息增益来进行构建;
- 每次迭代选择信息增益最大的特征属性作为分割属性
- 传统ID3算法不支持连续变量;
- 传统ID3算法对于缺省值不行;

3.2 ID3算法优缺点
优点:
- 决策树构建速度快;
- 实现简单;
缺点:
- 计算依赖于特征数目较多的特征,而属性值最多的属性并不一定最优
- ID3算法不是递增算法
- ID3算法是单变量决策树,对于特征属性之间的关系不会考虑
- 抗噪性差
- 只适合小规模数据集,需要将数据放到内存中
3.3 C4.5算法(信息增益比 最大的准则)
- 在ID3算法的基础上,进行算法优化提出的一种算法(C4.5);
- 现在C4.5已经是特别经典的一种决策树构造算法;
- 使用信息增益率来取代ID3算法中的信息增益,在树的构造过程中会进行剪枝操作进行优化;
- 能够自动完成对连续属性的离散化处理;
- C4.5算法在选中分割属性的时候选择信息增益率最大的属性,涉及到的公式为:

3.4 C4.5算法优缺点
优点:
- 产生的规则易于理解
- 准确率较高
- 实现简单
缺点:
- 对数据集需要进行多次顺序扫描和排序,所以效率较低
- 只适合小规模数据集,需要将数据放到内存中
3.5 CART算法(分类回归树算法)
使用基尼系数作为数据纯度的量化指标来构建的决策树算法就叫做CART(Classification And Regression Tree,分类回归树)算法。CART算法使用GINI增益作为分割属性选择的标准,选择GINI增益最大的作为当前数据集的分割属性;可用于分类和回归两类问题。强调备注:CART构建是二叉树。
- 回归树: 平方误差 最小
- 分类树: 基尼系数 最小的准则 在sklearn中可以选择划分的原则

3.6 ID3,C4.5,CART分类树算法总结(重点)
- ID3和C4.5算法均只适合在小规模数据集上使用
- ID3和C4.5算法都是单变量决策树
- 当属性值取值比较多的时候,最好考虑C4.5算法,ID3得出的效果会比较差
- 决策树分类一般情况只适合小数据量的情况(数据可以放内存)
- CART算法是三种算法中最常用的一种决策树构建算法。
- 三种算法的区别仅仅只是对于当前树的评价标准不同而已,ID3使用信息增益、C4.5使用信息增益率、CART使用基尼系数。
- CART算法构建的一定是二叉树,ID3和C4.5构建的不一定是二叉树。

4 决策树优化策略
剪枝优化
- 决策树过渡拟合一般情况是由于节点太多导致的,剪枝优化对决策树的正确率影响是比较大的,也是最常用的一种优化方式。
随机森林(Random Forest)
- 利用训练数据随机产生多个决策树,形成一个森林。然后使用这个森林对数据进行预测选取最多结果作为预测结果。
5 决策树的剪枝
决策树的剪枝是决策树算法中最基本、最有用的一种优化方案,主要分为两大类:
- 前置剪枝:在构建决策树的过程中,提前停止。结果是决策树一般比较小,实践证明这种策略无法得到比较好的结果。
- 后置剪枝:在决策树构建好后,然后再开始裁剪,一般使用两种方式:
- 1)用单一叶子节点代替整个子树,叶节点的分类采用子树中最主要的分类;
- 2)将一个子树完全替代另外一棵子树;后置剪枝的主要问题是计算效率问题,存在一定的浪费情况。
后置剪枝总体思路(交叉验证):
- 由完全树T0开始,剪枝部分节点得到T1,在此剪枝得到T2 … 直到仅剩树根的树Tk;
- 在验证数据集上对这k+1个树进行评价,选择最优树Ta(损失函数最小的树)
5.1 决策树剪枝过程
对于给定的决策树T0
- 计算所有内部非叶子节点的剪枝系数
- 查找最小剪枝系数的节点,将其子节点进行删除操作,进行剪枝得到决策树Tk;如果存在多个最小剪枝系数节点,选择包含数据项最多的节点进行剪枝操作
- 重复上述操作,直到产生的剪枝决策树Tk只有1个节点
- 得到决策树T0T1T2…Tk
- 使用验证样本集选择最优子树Ta
使用验证集选择最优子树的标准,可以使用原始损失函数来考虑:

5.2 决策树剪枝损失函数及剪枝系数

5.3 分类树和回归树的区别
- 分类树采用信息增益、信息增益率、基尼系数来评价树的效果,都是基于概率值进行判断的;而分类树的叶子节点的预测值一般为叶子节点中概率最大的类别作为当前叶子的预测值。
- 在回归树种,叶子节点的预测值一般为叶子节点中所有值的均值来作为当前叶子节点的预测值。所以在回归树中一般采用MSE作为树的评价指标,即均方差。

- 一般情况下,只会使用CART算法构建回归树。

6 决策树可视化
6.1 插件安装
决策树可视化可以方便我们直观的观察所构建的树模型;决策树可视化依赖graphviz服务,所以我们在进行可视化之前,安装对应的服务;操作如下:
- 安装graphviz服务
- 安装python的graphviz插件:pip install graphviz
- 安装python的pydotplus插件:pip install pydotplus
6.2 graphviz服务安装
- 下载安装包(msi安装包):http://www.graphviz.org/;
- 执行下载好的安装包(双击msi安装包);
- 将graphviz的根目录下的bin文件夹路径添加到PATH环境变量中;
6.3 决策树可视化案例
- 方式一:将模型输出dot文件,然后使用graphviz的命令将dot文件转换为pdf格式的文件
- 方式二:直接使用pydotplus插件直接生成pdf文件进行保存
- 方式三:使用lmage对象直接显示pydotplus生成的图片
# 方式一:输出形成dot文件,然后使用graphviz的dot命令将dot文件转换为pdf
from sklearn import tree
with open('iris.dot', 'w') as f:
# 将模型model输出到给定的文件中
f = tree.export_graphviz(model, out_file=f)
# 命令行执行dot命令: dot -Tpdf iris.dot -o iris.pdf
# 方式二:直接使用pydotplus插件生成pdf文件
from sklearn import tree
import pydotplus
dot_data = tree.export_graphviz(model, out_file=None)
graph = pydotplus.graph_from_dot_data(dot_data)
# graph.write_pdf("iris2.pdf")
graph.write_png("0.png")
# 方式三:直接生成图片
from sklearn import tree
from IPython.display import Image
import pydotplus
dot_data = tree.export_graphviz(model, out_file=None,
feature_names=['sepal length', 'sepal width', 'petal length', 'petal width'],
class_names=['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'],
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png())
7 案例
决策树案例一:莺尾花数据分类
- 使用决策树算法API对鸢尾花数据进行分类操作,并理解及进行决策树API的相关参数优化
- 数据来源:鸢尾花数据
决策树案例二:波土顿房屋租赁价格预测
- 使用决策树算法API对波士顿房屋租赁数据进行回归操作,预测房屋的价格信息,并理解及进行决策树API的相关参数优化
- 数据来源:波士顿房屋租赁数据
使用决策树实现特征选择:文章来源:https://www.toymoban.com/news/detail-726772.html
- 因为决策树构建过程中,每次选择的划分特征的目的/方向是让数据具有更加明显的区分能力;也就是说我们每次选择的特征其实是具有比较明显的区分能力的特征;可以认为这些被选择的特征其实对于y的取值具有更大的影响;所以我们可以使用决策树来实现特征选择的操作
- 即选择
clf.feature_importances_返回列表中,权重比较大的特征
8 决策树知识回顾
 文章来源地址https://www.toymoban.com/news/detail-726772.html
文章来源地址https://www.toymoban.com/news/detail-726772.html
到了这里,关于9_分类算法—决策树的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!