一、WEB自动化简介
1.1 什么是自动化?
1、概念
由机器设备代替人工自动完成指定目标的过程
2、优点
- 减少人工劳动力
- 提高工作效率
- 产品规格统一标准
- 规格化(批量生产)
1.2 什么是自动化测试?
概念:让程序代替人工去验证系统功能的过程
1.3 自动化测试能解决什么问题?
- 解决-回归测试(重点)
- 解决-压力测试
- 解决-兼容性测试(浏览器、分辨率、操作系统)
- 提高测试效率,保证产品质量
回归测试:项目在发新版本之后对项目之前的功能进行验证
压力测试:可以理解多用户同时去操作软件,统计软件服务器处理多用户请求的能力
兼容性测试:不同浏览器(IE、Firefox、Chrome)等
1.4 自动化测试相关知识
1、优点
- 较少的时间内运行更多的测试用例
- 自动化脚本可重复运行
- 减少人为的错误
- 克服手工测试的局限性(图片大小)
自动化测试覆盖率50%~60%
2、误区
- 自动化测试可以完全代替手工测试
- 自动化测试一定比手工测试厉害
- 自动化测试可以发掘更多的bug
- 自动化测试用于所有功能
3、自动化测试分类
- Web-自动化测试
- 移动-自动化测试
- 接口-自动化测试
- 单元测试-自动化测试
1.5 什么是Web自动化测试?
1、概念
程序代替人工自动验证Web项目功能的过程
2、什么Web项目适合做自动化测试
- 需求变动不频繁
- 项目周期长
- 项目需要回归测试
3、Web自动化测试在什么阶段开始?
功能测试完毕(手工测试)(1、时间问题;2、功能不完善)
4、Web自动化测试所属分类
按照代码可见度划分:
- 黑盒测试(功能测试)
- 白盒测试(单元测试)
- 灰盒测试(接口测试)
Web自动化测试属于黑盒测试(功能测试)
二、Web自动化测试工具选择
1.1 主流的Web自动化测试工具
- QTP:收费,支持Web,桌面自动化测试
- Selenium(本阶段学习):开源的Web自动化测试工具,免费,主要做功能测试
- Robot framework:基于Python可扩展地关键字驱动的测试自动化框架,2014停止更新
Web自动化测试的三板斧:
● 定位元素
● 交互元素
● 进行断言
2.1、 什么是Selenium?
Selenium是一个用于Web应用程序的自动化测试工具
1、 Selenium特点
- 开源软件:源代码开放可以根据需要来增加工具的某些功能
- 跨平台:Linux、Windows、Mac
- 支持多种浏览器:Firefox、Chrome、IE
- 支持多种语言:Python、Java、C#、JavaScript、Ruby、PHP等
- 成熟稳定:目前已经被谷歌、百度、腾讯等公司广泛使用
- 功能强大:支持商业化大部分功能,由于开源,可定制化功能
2、Python+Selenium环境搭建
python+Pychram+selenium+chrome+谷歌浏览器驱动
谷歌版本和浏览器驱动一定要一致
- Terminal中安装selenium:pip install selenium
查看:pip show selenium
卸载:pip unistall selenium
扩展:
○ 安装指定版本:pip install selenium==版本号
○ pip是python中包管理工具(可以安装,卸载,查看python工具)
○ pip list:查看通过pip包管理工具安装的插件或工具
提示:
使用pip必须联网;默认安装python3.5版本以上工具,自带pip包管理工具,默认会自动安装并且添加path环境变量
-
查看Chorme的版本

-
打开中国镜像站,下载驱动。中国镜像网址
-
点击Chrome Driver镜像。Chrome驱动

-
选择和Chrome版本最近的驱动进行下载

-
将驱动下载到指定文件夹,并将所在目录添加到系统path环境变量中


-
导包,测试是否安装成功

3、科普path
说明:指定系统搜索的目录
dos命令默认搜索顺序:
- 检测是否为内部命令
- 检测是否为当下目录可执行文件
- 检测path环境指定的目录
- 如果以上搜索目录都检测不到输入的命令或可执行文件,系统会抛出不是内部或外部命令
在web环境中,如果不将浏览器驱动添加到path中,会提示selenium驱动有误
4、第一个案例
1、导包
import time
from selenium import webdriver
2、获取谷歌浏览器对象
driver = webdriver.Chrome()
3、打开网页
driver.get("https://www.baidu.com/")
#暂停三秒
time.sleep(3)
#退出浏览器
driver.quit()
5、pycharm安装软件
推荐原因:安装到当前工程环境内
提示:如果使用pip install插件名安装过后,打开pycharm导包操作时,提示找不到此包,说明使用pip install默认安装的路径和当前工程的环境路径不是同一个环境,进行以上处理可以解决问题。
三、八大元素定位
3.1 为什么要学习元素定位?
----让程序操作执行元素,就必须先找到此元素。
3.2 定位元素时依赖于什么?
● 标签名
● 属性
● 层级
● 路径
3.3 面试题
如果元素定位不到,你是怎么去分析的?
- 元素没有加载完成
- Frame中
- 元素不可用,不可读,不可见
- 动态属性/动态的DIV层
3.4 使用定位策略
- driver.find_element_by_id() # 被弃用了
- driver.find_element(By.ID,“”) # 推荐,定位一个元素
- driver.find_elements(By.ID,“”) # 定位一组元素
元素定位的前提:需要定位的元素或它的属性必须要唯一。
3.5 八大元素
- id
- name
- class_name(使用元素的class属性)
- xpath(基于文件路径)
- css(元素选择器定位)
- tag_name(元素的标签名称<input …/>)
- link_text(定位超链接,a标签)
- partail_link_text(定位超链接,a标签 模糊)
汇总:
1.基于元素属性特有定有定位:id/name/class_name
2. 基于元素标签名称定位:tag_name
3. 定位超链接文本:link_text/partail_link_text
4. 基于元素路径定位:xpath
5. 基于选择器:css
"""底层代码"""
from selenium.webdriver.common.by import By
ID = "id"
XPATH = "xpath"
LINK_TEXT = "link text"
PARTIAL_LINK_TEXT = "partial link text"
NAME = "name"
TAG_NAME = "tag name"
CLASS_NAME = "class name"
CSS_SELECTOR = "css selector"
1、id
HTML规定id属性在HTML文档中必须是唯一的
driver.find_element(By.ID, “id名”).send_keys(“输入内容”)
#打开浏览器
driver = webdriver.Chrome()
加载网页
driver.get("https://www.baidu.com/")
定位元素(利于封装)
driver.find_element(By.ID, "kw").send_keys("输入的内容")
2、name
driver.find_element(By.NAME, "wd").send_keys("输入的内容")
3、class_name
driver.find_element(By.CLASS_NAME,"login-top")
4、tag_name
通过标签名来定位,一般很少使用
如果页面中存在多个相同的标签名,默认返回第一个
driver.find_element(By.TAG_NAME,"input").send_keys("admin")
5、link_text
精确匹配超链接
driver.find_element(By.LINK_TEXT,"新闻").click()
6、partail_link_text
模糊匹配超链接
driver.find_element(By.PARTIAL_LINK_TEXT,"新").click()
7、xpath
如果要定位的元素没有id、name、class属性,该如何进行定位?
----使用xpath。
xPath是XML Path的简称,是一门在XML文档中查找元素信息的语言
XML是一种标记语言。
● 本质是一种查询语言
●支持逻辑运算、函数
● 实现非常强大的功能
● 可以用于APP自动化测试
依赖于元素的路径:
● 绝对路径:/开头是绝对路径
● 相对路径://开头是相对路径
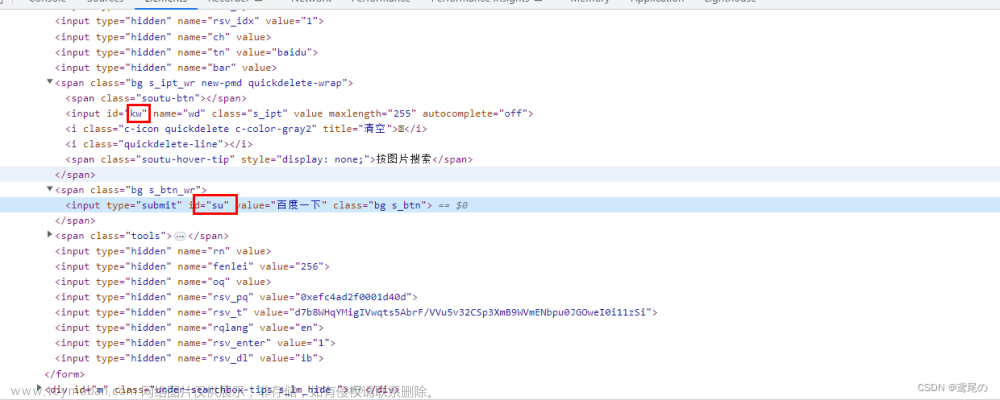
#1、相对路径+索引定位 //form/span/input
driver.find_element(By.XPATH,"//form/span/input").send_keys("输入的内容")
#2、相对路径+属性定位 //input[@autocomplete='off']
driver.find_element(By.XPATH,"//input[@autocomplete='off']").send_keys("输入的内容")
#3、相对路径+通配符定位 *复制xpath不是万能的,经常会报错
driver.find_element(By.XPATH,"//*[@autocomplete='off']").send_keys("输入的内容")
driver.find_element(By.XPATH,"//*[@*='off']").send_keys("输入的内容")
#4、相对路径+部分属性值定位 input[starts-with(@autocomplete,'of')]
driver.find_element( # auto属性以of开头:starts-with
By.XPATH,"//input[starts-with(@autocomplete,'of')]"
).send_keys("输入的内容")
driver.find_element( # auto属性从第二个字符开始截取,为ff的:substring
By.XPATH,"//input[substring(@autocomplete,2)='ff']"
).send_keys("输入的内容")
driver.find_element( # auto属性包含字符of:contains
By.XPATH,"//input[contains(@autocomplete,'of')]"
).send_keys("输入的内容")
#5、相对路径+文本定位
value = driver.find_element(
By.XPATH,"//span[text()='按图片搜索']"
).get_attribute('class')
1、XPATH的语法
语法:表示层级+属性
- /(开头)表示根路径
/html/body/div- //(任意层级)(包括下级、下级的下级…)
//div- @属性
‘//a[@target=“_top”]’- /(中间)表示下一级
‘//p//input’- .表示本级
- …表示上一级
2、 XPATH的函数
函数是XPATH另一个魅力,常用的函数:
● text:获取元素内的文本
● contains:任意位置包含匹配
● starts-with:开头
● substring:截取
$x(“//a[text=(vivoX5MAX L 移动4G 八核超薄大屏5.5双卡)]”)
$x(“//a[contains( text=(),‘vivo’) ]”)
$x(“//a[start-with( text=(),‘vivo’) ]”)
$x(“//a[substring(@name,2)=‘vi’ ]”)
3.8 css
1. id选择器
- 前提:元素必须有id属性
- 语法:#id 如:#password
2. class选择器
- 前提:元素必须是有class属性
- 语法:.class 如:.telA
3. 元素选择器
- 语法:element 如:input
4. 属性选择器
- 语法:[属性名=属性值]
5. 层级选择器
- 语法:
p>input
p input - 提示:
大于号和空格的区别,大于号必须为子元素,空格则不用
6. 【css延伸】
input[type^=‘p’] type属性以p字母开头的元素
input[type$=‘d’] type属性以d字母结束的元素
input[type*=‘w’] type属性包含w字母的元素
#1.使用css id选择器 定位用户名 输入admin
driver.find_element(By.CSS_SELECTOR, "#userA").send_keys("admin")
#2.使用css 属性选择器 定位密码框 输入123456
driver.find_element(By.CSS_SELECTOR, "[name='passwordA']").send_keys("123456")
#3.使用css class选择器 定位电话号码 输入18611112222
driver.find_element(By.CSS_SELECTOR, ".telA").send_keys("18611112222")
#4.使用css 元素选择器 定位span标签获取文本值
span = driver.find_element(By.CSS_SELECTOR, "span").text
print("获取的span标签文本值为:",span)
#5.使用层级选择器 定位email 输入123@qq.com
driver.find_element(
By.CSS_SELECTOR,"p>input[placeholder='电子邮箱A']"
).send_keys("123@qq.com")
3.9 XPATH和CSS类似功能对比
| 定位方式 | XPath | CSS |
|---|---|---|
| 元素名 | //input | input |
| id | //input[@id=‘userA’] | @userA |
| class | //*[@class=‘telA’] | .telA |
| 属性 | 1.//*[text()==“xxx”] 2.//input[starts-with(@attribute,‘xxx’)] 3.//input[contains(@attribute,‘xxx’)] |
1.input[type^=‘p’] 2.input[type$=‘d’ 3.input[type*=‘w’] |
3.10 定位一组元素
- 方法:find_elements(By.元素,xxx)
- 返回结果:类型为列表,要对列表进行访问和操作必须指定下标或进行遍历,下标从0开始
四、UnitTest
4.1 unittest使用方式
- 导包:import unittest、from selenium import webdriver
- 创建测试类继承unittest.TestCase
- 写一个以test_开头的测试方法
import unittest
from selenium import webdriver
class TestCase(unittest.TestCase):
def test_01_login(self):
import unittest
from selenium import webdriver
from selenium.webdriver.common.by import By
class TestCase(unittest.TestCase):
def test_01_login(self):
global driver
# 1、打开浏览器
driver = webdriver.Chrome()
# 2、加载网页
driver.get("https://www.baidu.com/")
# 3、定位元素
driver.find_element(By.XPATH, "//form/span/input").send_keys("输入的内容")
unittest运行测试用例的一个很大的坑:文章来源:https://www.toymoban.com/news/detail-726799.html
4.2 两种运行方式
- 命令行方式:(不需要考虑环境)
- python -m unittest 模块名.py —>执行整个模块
- python -m unittest 模块名.类名.方法名 —>执行单个方法
- main方式 -->必须要配置环境

 文章来源地址https://www.toymoban.com/news/detail-726799.html
文章来源地址https://www.toymoban.com/news/detail-726799.html
到了这里,关于第一章 Web自动化入门的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!