目录
前言
一、链表是什么?
二、使用步骤
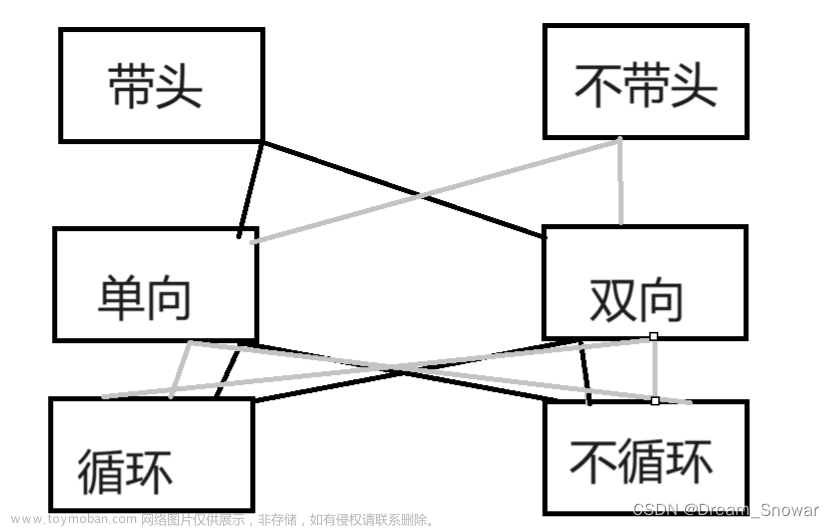
1.单链表与双链表之间的关系
2.代码如下:
三、总结
链表进阶之路的开头题记:
在计算机科学的旅程中,链表是一个重要的里程碑。它不仅是数据结构中的经典之作,也是我们探索更复杂数据结构的起点。链表进阶之路,将引领我们进入数据结构的深邃世界,探索更高级的链表技巧和应用。在这个旅途中,我们将穿越单链表和双链表的迷宫,学习如何插入、删除和搜索节点,解决实际问题。
前言
链表在C语言中的应用广泛。通过使用链表,我们可以实现动态的分配、高效的插入和删除操作,以及灵活和动态的数据结构。通过权衡不同的需求和场景,选择合适的数据结构可以使程序更加高效和灵活
一、链表是什么?
单链表是一种数据结构,由节点组成,每个节点包含两部分信息:数据和指向下一个节点的指针。节点按顺序链接在一起,形成一个链表。我们只能从链表的头部开始遍历,并通过节点之间的指针找到下一个节点,依次访问链表的每个节点。
双链表也是一种数据结构,与单链表类似,它的节点也包含数据和指向下一个节点的指针。但双链表的节点还额外包含一个指向前一个节点的指针,使得节点之间既可以通过后继指针找到下一个节点,也可以通过前驱指针找到前一个节点。这样的设计使得在双链表中可以双向遍历,即可以从头部或尾部开始遍历链表。
通俗一点来说,当谈到单链表和双链表时,可以将它们比作火车。火车中的每辆车厢都代表链表中的一个节点,每个节点包含一些数据以及一个指向下一个节点的链接。单链表就像是每个车厢只有单向连接的火车。每个车厢只能看到自己前面的车厢,不能向后看。最后一个车厢的终点是一个空链接,表示链表的结束。我们只能从第一个车厢开始往后遍历整个火车。双链表则是每个车厢既有向前的链接,也有向后的链接的火车。这样,每个车厢都可以看到前面和后面的车厢。第一个车厢向前的链接为空,表示链表的开始,最后一个车厢向后的链接为空,表示链表的结束。这样的双向链接使得我们可以从任意一个节点开始,向前或向后遍历整个火车。
二、使用步骤
1.单链表与双链表之间的关系
当我们来看一个例子,可以更好地理解单链表和双链表之间的关系。假设我们有一个学生信息管理系统,需要存储每个学生的姓名和年龄。我们可以使用链表来组织和管理这些学生信息。
单链表的应用:
我们可以使用单链表来存储学生信息。每个节点表示一个学生,节点包含两个部分:一个是学生的姓名,另一个是学生的年龄。节点之间通过指针链接在一起,形成一个链表。每个节点只能访问下一个节点,类似于一条单向通道。例如,链表中的第一个节点存储学生A的信息,第二个节点存储学生B的信息,依此类推。我们可以从链表的头节点开始遍历,不断向下访问下一个节点,直到找到我们想要的学生信息。
双链表的应用:
现在,假设我们的学生信息管理系统需要支持对学生信息的逆向遍历和修改。我们可以通过使用双链表来满足这个需求。每个双链表节点与单链表节点类似,但有一个额外的指针,即指向前一个节点的指针。这样,每个节点既可以访问下一个节点,也可以访问前一个节点,类似于我们在链表中有了一条反向通道。现在,我们可以从链表的头节点开始正向遍历,也可以从尾节点开始反向遍历。这使得在某些情况下更方便地访问和修改学生信息。例如,我们可以从链表的尾节点开始,通过前一个节点指针向前遍历,找到我们想要修改的学生的节点,然后进行相应的操作。
综上所述,单链表和双链表在存储和处理学生信息这样的实际情况中有不同的应用。单链表适用于顺序访问和操作节点的情况,而双链表在需要逆向遍历和修改节点时更加方便。选择哪种链表取决于具体的需求和操作的灵活性。
2.代码如下:
当你构建学生信息管理系统时,你可以使用以下的示例代码来实现单链表和双链表:
1.单链表实现:
// 定义节点结构
typedef struct Node {
char name[50];
int age;
struct Node* next;
} Node;
// 创建一个新节点
Node* createNode(char name[], int age) {
Node* newNode = (Node*)malloc(sizeof(Node));
strcpy(newNode->name, name);
newNode->age = age;
newNode->next = NULL;
return newNode;
}
// 在链表尾部插入节点
void insertNode(Node** head, Node* newNode) {
if (*head == NULL) {
*head = newNode;
} else {
Node* current = *head;
while (current->next != NULL) {
current = current->next;
}
current->next = newNode;
}
}
// 遍历并打印链表
void printList(Node* head) {
Node* current = head;
while (current != NULL) {
printf("Name: %s, Age: %d\n", current->name, current->age);
current = current->next;
}
}
// 示例调用
int main() {
Node* head = NULL;
// 插入节点
insertNode(&head, createNode("Alice", 20));
insertNode(&head, createNode("Bob", 22));
insertNode(&head, createNode("Carol", 21));
// 打印链表
printList(head);
return 0;
}2.双链表实现:
// 定义节点结构
typedef struct Node {
char name[50];
int age;
struct Node* prev;
struct Node* next;
} Node;
// 创建一个新节点
Node* createNode(char name[], int age) {
Node* newNode = (Node*)malloc(sizeof(Node));
strcpy(newNode->name, name);
newNode->age = age;
newNode->prev = NULL;
newNode->next = NULL;
return newNode;
}
// 在链表尾部插入节点
void insertNode(Node** head, Node* newNode) {
if (*head == NULL) {
*head = newNode;
} else {
Node* current = *head;
while (current->next != NULL) {
current = current->next;
}
newNode->prev = current;
current->next = newNode;
}
}
// 遍历并打印链表
void printList(Node* head) {
Node* current = head;
while (current != NULL) {
printf("Name: %s, Age: %d\n", current->name, current->age);
current = current->next;
}
}
// 逆向遍历并打印链表
void reversePrintList(Node* head) {
Node* current = head;
while (current->next != NULL) {
current = current->next;
}
while (current != NULL) {
printf("Name: %s, Age: %d\n", current->name, current->age);
current = current->prev;
}
}
// 示例调用
int main() {
Node* head = NULL;
// 插入节点
insertNode(&head, createNode("Alice", 20));
insertNode(&head, createNode("Bob", 22));
insertNode(&head, createNode("Carol", 21));
// 正向打印链表
printf("Forward traversal:\n");
printList(head);
// 逆向打印链表
printf("\nReverse traversal:\n");
reversePrintList(head);
return 0;
}注意一点:
以上只是简单示例代码,实际应用中还需要进行错误处理、内存释放等相关操作,以确保程序的正确性和健壮性。
三、总结
当谈到C语言中的链表时,有两种主要的类型,即单链表和双链表。它们都是用于在内存中存储和组织数据的基本数据结构。
单链表
单链表是由一系列节点组成的数据结构,每个节点都包含一个数据元素和一个指向下一个节点的指针。单链表的节点只能以单向方式进行遍历,即从前往后。这对于某些场景来说是足够的,而且单链表的实现和操作都相对简单。由于单链表节点只有一个指针,所以在内存使用方面相对更节省。
单链表的好处之一是在插入和删除元素时的高效性。当需要在链表的任意位置插入或删除节点时,只需要修改相应节点的指针即可,而不需要像数组一样移动大量的数据。因此,单链表在动态数据存储和频繁插入/删除操作的场景中表现出色。
然而,由于单链表只能从前往后遍历,如果需要通过访问节点的前一个节点来执行某些操作,就会变得相对困难和低效。例如,在需要逆序遍历链表或删除前一个节点时,需要重新遍历整个链表以找到前一个节点的位置。在这种情况下,双链表可能更适合。
双链表
双链表中的每个节点都包含一个指向前一个节点和后一个节点的指针。这使得在双链表中可以进行双向遍历,可以从前往后或从后往前遍历链表。这样的双向遍历能力使得在某些场景下更加灵活和高效。
双链表相对于单链表的另一个好处是在删除和插入节点时的方便性。通过修改前一个节点和后一个节点的指针,就可以在双链表中轻松地删除或插入节点,而不需要像数组或单链表那样移动大量的数据。这对于需要在某个特定位置前后插入或删除节点的情况非常有用。
然而,双链表相对于单链表占用更多的内存空间。每个节点都需要额外的内存来存储指向前一个节点的指针。因此,在内存受限的环境中,双链表可能不是最佳选择。
两种链表类型之间的关系
单链表和双链表之间具有一定的关系和差异。双链表可以看作是单链表的扩展版本,因为它保留了单链表的功能,并在某些方面进行了增强。如果只需进行单向遍历并且内存使用是一个要考虑的因素,那么使用单链表可能更适合。单链表的实现较简单且内存占用较低,适用于简单的数据结构。
双链表在需要双向遍历或频繁进行插入/删除操作的场景下更有优势。双链表的双向遍历能力使得在某些情况下可以更高效地操作数据。它可以方便地在任意位置前后插入或删除节点,而无需重新遍历整个链表。但需要注意的是,双链表的实现和内存消耗相对更高,因此在资源有限的环境下使用时需要权衡考虑。文章来源:https://www.toymoban.com/news/detail-727081.html
综上所述,单链表和双链表是C语言中常用的数据结构,每种链表类型都有其自身的优势和劣势。选择适当的链表类型应该根据特定的应用需求和场景来决定。希望这篇文章能够帮助你更深入地理解链表,并在编写C语言代码时作出明智的选择。无论是单链表还是双链表,它们都是非常有用且重要的数据结构,可以帮助解决各种问题。文章来源地址https://www.toymoban.com/news/detail-727081.html
到了这里,关于探索链表的进阶之路的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!