0、类C语言代码说明
// 函数结果状态代码
#define OK 1
#define ERROR 0
#define OVERFLOW -2
// 函数返回值类型(返回函数结果状态代码)
typedef int Status;
// 用户自定义数据元素类型 ElemType
typedef xxx ElemType;
// C++ 引用(示例)
void swap(int &x, int &y); // 把引用作为参数(传入地址)
// C++ 动态内存(示例)
double* pvalue = NULL; // 初始化为空指针
pvalue = new double; // 为指针变量请求内存
delete pvalue; // 释放之前分配的内存
1、线性表
1.1 线性表的顺序表示和实现
1.1.1 线性表的顺序存储表示
/* 顺序表的存储结构 */
#define MAXSIZE 100 // 顺序表可能达到的最大长度
typedef struct {
ElemType *elem; // 存储空间的基地址
int length; // 当前长度
} SqList; // 顺序表的结构类型
1.1.2 顺序表中基本操作的实现
1.1.2.1 初始化
/* 返回值为Status(状态码) */
Status InitList(SqList &L) { // 构造一个空的顺序表
L.elem = new ElemType[MAXSIZE]; //分配一个MAXSIZE大小的数组空间
if(!L.elem) { // 检查自由存储区是否有可用空间分配内存
exit(OVERFLOW); // 若存储分配失败则退出
}
L.length = 0; // 设空表长度为0
return OK;
}
// 当不需要动态分配的内存时,可以销毁或释放
1.1.2.2 取值
/* 返回值为Status(状态码) */
Status GetElem(SqList L, int i, ElemType &e) {
if(i < 1 || i > L.length) { // 判断i值是否合理(1 ≤ i ≤ n)
return ERROR; // 若不合理则返回ERROR
}
e = L.elem[i-1]; // 将第i个数据元素赋值给参数e
return OK;
}
// 顺序表取值算法的时间复杂度为 O(1)
1.1.2.3 查找
/* 返回值为int(整数) */
int LocateElem(SqList L, ElemType e) {
for(i=0; i<L.length; i++) {
if(L.elem[i] == e) {
return i+1; // 查找成功,返回序号i+1
}
}
return 0; // 查找失败,返回0
}
// 顺序表按值查找算法的平均时间复杂度为 O(n)
1.1.2.4 插入
/* 返回值为Status(状态码) */
Status ListInsert(SqList &L, int i, ElemType e) {
if(i<1 || i>L.length+1) { // 判断i值是否合法(1 ≤ i ≤ n+1)
return ERROR; // 若不合法则返回ERROR
}
if(L.length == MAXSIZE) { // 判断内存是否已满(达到最大长度)
return ERROR; // 若已满则返回ERROR
}
for(j=L.length-1; j>=i-1; j--) { // 从最后一个到第i个元素
L.elem[j+1] = L.elem[j]; // 依次后移一个位置
}
L.elem[i-1] = e; // 将e放入第i个元素位置
++L.length; // 表长加1
return OK;
}
// 顺序表插入算法的平均时间复杂度为 O(n)
1.1.2.5 删除
/* 返回值为Status(状态码) */
Status ListDelete(SqList &L, int i) {
if(i<1 || i>L.length) { // 判断i值是否合法(1 ≤ i ≤ n)
return ERROR; // 若不合法则返回ERROR
}
for(j=i; j<=L.length-1; j++) { // 从第i+1个元素到最后一个
L.elem[j-1] = L.elem[j]; // 依次前移一个位置
}
--L.length; // 表长减1
return OK;
}
// 顺序表删除算法的平均时间复杂度为 O(n)
1.1.2.6 计数
/* 返回值为int(整数) */
int ListLength(SqList L) {
return L.length; // 直接返回L的length属性值
}
// 顺序表计数算法的平均时间复杂度为 O(1)
1.2 线性表的链式表示和实现
1.2.1 单链表的定义和表示
// 单链表可由头指针唯一确定,可用结构指针来描述单链表的存储结构
typedef struct LNode {
ElemType data; // 数据域data
struct LNode *next; // 指针域next(指向结点LNode的指针)
} LNode, *LinkList;
LinkList L; // L表示头指针
LNode *p; // p表示结点指针,*p表示结点
★ 关于结点
/* 等价的定义形式(变量含义不同) */
LinkList p; // p为指示结点的指针变量(结点地址)
LNode *p; // *p为结点变量(结点名称)
/* 通过指针变量访问结点分量 */
p->data; // 指针p指示的结点*p的数据域
p->next; // 指针p指示的结点*p的指针域(后继结点的地址)
/* 通过结点变量访问结点分量 */
(*p).data; // 结点*p的数据域
(*p).next; // 结点*p的指针域(后继结点的地址)
*((*p).next); // 结点*p的后继结点
1.2.2 单链表基本操作的实现
1.2.2.1 初始化
/* 返回值为Status(状态码) */
Status InitList(LinkList &L) { // 构造一个空的单链表
L = new LNode; // 生成新结点作为头结点
L->next = NULL; // 用头指针L指向头结点,并将头结点指针域置空
return OK;
}
1.2.2.2 取值
/* 返回值为Status(状态码) */
Status GetElem(LinkList L, int i, ElemType &e) {
p = L->next; // 初始化p为头指针指向的首元结点
j = 1; // 计数器j赋值1
while(p && j<i) { // 当p不为空且j<i时循环操作
p = p->next; // p依次顺链向下访问(p更新为当前结点)
++j; // 计数器依次加1
}
if(!p || j>i) { // 若p为空或i>n或i≤0,则i不合法
return ERROR;
}
e = p->data; // 参数e保存第i个元素(当前p)的数据域
return OK;
}
// 单链表取值算法的平均时间复杂度为 O(n)
1.2.2.3 查找
/* 返回值为LNode(结点) */
LNode *LocateElem(LinkList L, ElemType e) {
p = L->next; // 初始化p为头指针指向的首元结点
while(p && p->data != e) { // 当p不为空且p数据域不为e时循环操作
p = p->next; // p依次顺链向下访问(p更新为当前结点)
}
return p; // 返回p结点值
}
// 单链表查找算法的平均时间复杂度为 O(n)
1.2.2.4 插入
/* 返回值为Status(状态码) */
Status ListInsert(LinkList &L, int i, ElemType e) {
p = L;
j = 0;
/* 合法插入位置有 n+1 个 */
while(p && j<i-1) { // 查找第i-1个结点
p = p->next; // p更新为当前结点(第i-1个)
++j;
}
if(!p || j>i-1) { // 若p为空或i>n+1或i<1,则i不合法
return ERROR;
}
s = new LNode; // 生产新结点*s
s->data = e; // *s的数据域赋为e
s->next = p->next; // *s的指针域赋为p的指针域(指向第i个)
p->next = s; // 结点*P的指针域指向*s
return OK;
}
// 单链表插入算法的平均时间复杂度为 O(n)
1.2.2.5 删除
/* 返回值为Status(状态码) */
Status ListDelete(LinkList &L, int i) {
p = L;
j = 0;
/* 合法删除位置有 n 个 */
while(p->next && j<i-1) { // 查找第i-1个结点
p = p->next; // p更新为当前结点(第i-1个)
++j;
}
if(!(p->next) || j>i-1) { // 若p指针域为空或i>n或i<1,则i不合法
return ERROR;
}
LNode *q; // 引入一个新指针q
q = p->next; // q临时保存被删结点的地址(第i个)
p->next = q->next; // 修改p指针域(指向第i+1个)
delete q; // 释放被删结点的空间
return OK;
}
// 单链表删除算法的时间复杂度为 O(n)
1.2.2.6 前插法创建单链表
/* 无返回值void */
void CreateList_H(LinkList &L, int n) {
L = new LNode; // 生成头结点*L(头指针L)
L->next = NULL; // 建立带头结点的空链表
for(i=0; i<n; ++i) {
p = new LNode; // 生成新结点*p(指针p)
cin >> p->data; // 提取用户输入的值并存储在*p的数据域中
p->next = L->next; // *p的指针域赋为*L的指针域(指向后置结点)
L->next = p; // *L指针域(头指针)指向*p
}
}
// 前插法创建单链表算法的时间复杂度为 O(n)
1.2.2.7 后插法创建单链表
/* 无返回值void */
void CreateList_R(LinkList &L, int n) {
L = new LNode; // 生成头结点*L(头指针L)
L->next = NULL; // 建立带头结点的空链表
LNode *r = L; // 引入尾指针r指向头结点*L
for(i=0; i<n; ++i) {
p = new LNode; // 生成新结点*p
cin >> p->data; // 提取用户输入的值并存储在p的数据域中
p->next = NULL; // *p的指针域赋为NULL(作为尾结点)
r->next = p; // 尾指针r(*r的指针域)指向*p
r = p; // 尾指针r更新到尾结点*p
}
}
// 后插法创建单链表算法的时间复杂度为 O(n)
1.2.3 循环链表
// 合并两个单向循环链表
// 合并两个单向循环链表算法的时间复杂度为 O(1)
1.2.4 双向链表
1.2.4.1 双向链表的存储结构
typedef struct DuLNode {
ElemType data; // 数据域
struct DuLNode *prior; // 指向直接前驱
struct DuLNode *next; // 指向直接后继
} DuLNode, *DuLinkList;
1.2.4.2 双向链表的查找
/* 返回值为DuLNode(结点) */
DuLNode *GetElem_DuL(DuLinkList L, int i) {
if(i < 1) {
return ERROR;
}
p = new DuLNode;
p = L->next;
for (j=1; j<i; j++) {
p = p->next;
}
return p;
}
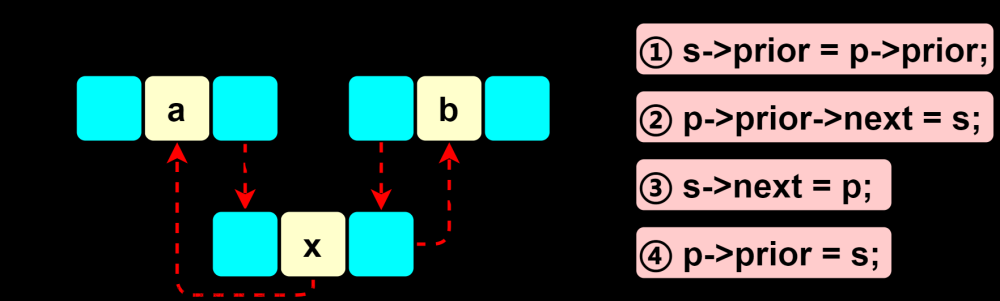
1.2.4.3 双向链表的插入
/* 返回值为Status(状态码) */
Status ListInsert_DuL(DuLinkList &L, int i, ElemType e) {
if(!(p = GetElem_DuL(L, i))) { // 查找第i个元素指针,赋值给p
return ERROR; // 判断p是否为空
}
s = new DuLNode; // 生成新结点*s(指针s)
s->data = e; // s的数据域赋为e
s->prior = p->prior; // s的前驱赋为p的前驱(指向第i-1个)
p->prior->next = s; // s的前驱的后继指向s
s->next = p; // s的后继指向p(第i个)
p->prior = s; // p的前驱指向s
return OK;
}
// 双向链表插入算法的时间复杂度为 O(n)
1.2.4.4 双向链表的删除
/* 返回值为Status(状态码) */
Status ListDelete_DuL(LinkList &L, int i) {
if(!(p = GetElem_DuL(L, i))) { // 查找第i个元素指针,赋值给p
return ERROR; // 判断p是否为空
}
p->prior->next = p->next; // p的前驱的后继赋为p的后继(指向i+1)
p->next->prior = p->prior; // p的后继的前驱赋为p的前驱(指向i-1)
delete p; // 释放被删结点*p的空间
return OK;
}
// 双向链表删除算法的时间复杂度为 O(n)
1.3 线性表的应用
1.3.1 线性表的合并
问题:已知两个集合A和B,求一个新的集合A=A∪B。文章来源:https://www.toymoban.com/news/detail-727259.html
/* 无返回值void */
void MergeList(List &LA, List LB) {
m = ListLength(LA); // 获取LA表长赋给m
n = ListLength(LB); // 获取LB表长赋给n
for(i=1; i<=n; i++) { // 遍历LB
GetElem(LB, i, e); // 依次取LB中第i个元素的值(保存在e中)
if(!LocateElem(LA, e)) { // 判断能否在LA中查找到与e相等的元素
ListInsert(LA, ++m, e); // 若找不到则将e插入LA的++m位置
}
}
}
// 线性表的合并算法的时间复杂度 O(m·n)
1.3.2 有序表的合并
问题:已知两个有序集合A和B,数据元素按值非递减有序排列,求一个新的集合C=A∪B,使集合C中的数据元素仍按值非递减有序排列。文章来源地址https://www.toymoban.com/news/detail-727259.html
1.3.2.1 顺序有序表的合并
/* 无返回值void */
void MergeList_Sq(SqList LA, SqList LB, SqList &LC) {
LC.length = LA.length + LB.length; // 新表长为两表长之和
LC.elem = new ElemType[LC.length]; // 为LC请求数组空间
SqList *pc, *pa, *pb, *pa_last, *pb_last; // 引入辅助指针
pc = LC.elem; // *pc指向LC第一个元素
pa = LA.elem; // *pa指向LA第一个元素(初值)
pb = LB.elem; // *pb指向LB第一个元素(初值)
pa_last = LA.elem + LA.length - 1; // *pa_last指向LA最后元素
pb_last = LB.elem + LB.length - 1; // *pb_last指向LB最后元素
/* 要求非递减排列,故依次取较小值从头到尾插入LC */
while(pa<=pa_last && pb<=pb_last) { // 若*pa、*pb均未到达表尾
if(*pa <= *pb) { // 依次比较取更小元素插入LC,指针同时向后移动
*pc++ = *pa++;
} else {
*pc++ = *pb++;
}
}
while(pa <= pa_last) { // 若*pa已到达表尾
*pc++ = *pa++; // 依次将LA剩余元素插入,指针同时向后移动
}
while(pb <= pb_last) { // 若*pb已到达表尾
*pc++ = *pb++; // 依次将LB剩余元素插入,指针同时向后移动
}
}
// 合并顺序有序表算法的时间复杂度 O(m+n),空间复杂度 O(m+n)
1.3.2.2 链式有序表的合并
/* 无返回值void */
void MergeList_L(LinkList &LA, LinkList &LB, LinkList &LC) {
LNode *pa, *pb, *pc; // 引入辅助指针pa、pb、pc
pa = LA->next; // pa指向LA首元结点(初值)
pb = LB->next; // pb指向LB首元结点(初值)
LC = LA; // LC头指针赋为LA头指针
pc = LC; // pc赋为LC头指针
while(pa && pb) { // 当pa、pb都不为空
if(pa->data <= pb->data) { // 若*pa数据值 ≤ *pb数据值(取pa)
pc->next = pa; // *pc指针域链接到*pa
pc = pa; // pc移动到pa
pa = pa->next; // pa移动到下一个位置
} else { // 若 *pa数据值 > *pb数据值(取pb)
pc->next = pb; // *pc指针域链接到*pb
pc = pb; // pc移动到pb
pb = pb->next; // pb移动到下一个位置
}
}
pc->next = pa?pa:pb; // 非空表的剩余结点一快链接到pc之后
delete LB; // 释放*LB头结点
}
// 合并链式有序表算法的时间复杂度 O(m+n),空间复杂度 O(1)
1.4 案例分析与实现
1.4.1 一元多项式的运算
/* 多项式的顺序存储结构 */
#define MAXSIZE 100 // 多项式可能到达的最大长度
typedef struct { // 多项式非零项的定义
float coef; // 系数
int expn; // 指数
} Polynomial;
typedef struct {
Polynomial *elem; // 存储空间的基地址
int length; // 多项式中当前项的个数
} SqList; // 多项式的顺序存储结构类型为SqList
1.4.2 稀疏多项式的运算
1.4.2.1 多项式的链式存储结构
typedef struct PNode {
float coef; // 系数(数据域)
int expn; // 指数(数据域)
struct PNode *next; // 指针域
} PNode, *Polynomial;
1.4.2.2 多项式的创建
/* 无返回值void */
void CreatePolyn(Polynomial &P, int n) {
P = new PNode; // 生成头指针P(头结点*P)
P->next = NULL; // 建立带头结点的空链表
PNode *s, *pre, *q; // 引入辅助指针s、pre、q
for(i=1; i<=n; ++i) { // 依次输入n个非零项,每次操作如下:
s = new PNode; // 生成新结点
cin >> s->coef >> s->expn; // 用户输入系数和指数
pre = P; // pre赋为头指针(保存q的前驱)
q = P->next; // q初始化,指向首元结点
while(q && (q->expn < s->expn)) { // 若q不为空,比较q、s指数
pre = q; // pre移动到q
q = q->next; // q移动到下一个位置
}
s->next = q; // s指针域链接到q
pre->next = s; // pre指针域链接到s
}
}
// 合并链式有序表算法的时间复杂度为 O(n²)
1.4.2.3 多项式的相加
/* 无返回值void */
void CreatePolyn(Polynomial &P, int n) {
P = new PNode; // 生成头指针P(头结点*P)
P->next = NULL; // 建立带头结点的空链表
PNode *s, *pre, *q; // 引入辅助指针s、pre、q
for(i=1; i<=n; ++i) { // 依次输入n个非零项,每次操作如下:
s = new PNode; // 生成新结点
cin >> s->coef >> s->expn; // 用户输入系数和指数
pre = P; // pre赋为头指针(保存q的前驱)
q = P->next; // q初始化,指向首元结点
while(q && (q->expn < s->expn)) { // 若q不为空,比较q、s指数
pre = q; // pre移动到q
q = q->next; // q移动到下一个位置
}
s->next = q; // s指针域链接到q
pre->next = s; // pre指针域链接到s
}
}
// 合并链式有序表算法的时间复杂度为 O(n²)
1.4.3 图书信息管理系统
/* 图书表的顺序存储结构 */
#define MAXSIZE 10000 // 图书表可能到达的最大长度
typedef struct { // 图书信息的定义
char no[20]; // 图书ISBN
char name[50]; // 图书名称
float price; // 图书价格
} Book;
typedef struct {
Book *elem; // 存储空间的基地址
int length; // 图书表中当前图书的个数
} SqList; // 图书表的顺序存储结构类型为SqList
SqList L; // 定义SqList类型的变量L
2、栈和队列
2.1 栈的表示和操作的实现
2.1.1 顺序栈的表示和实现
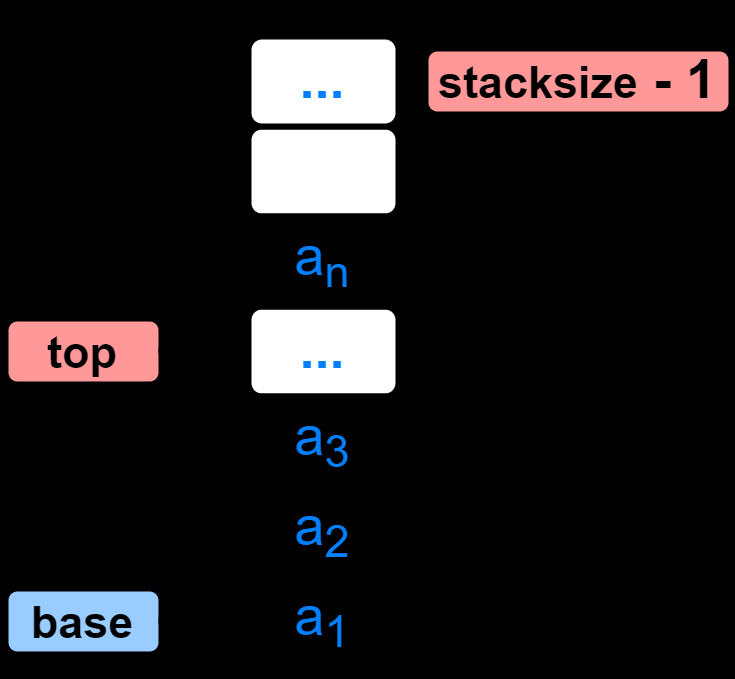
2.1.1.1 顺序栈的存储结构
#define MAXSIZE 100 // 顺序栈存储空间的初始分配量
typedef struct {
SElemType *base; // 栈底指针(始终指向栈底,为NULL则栈不存在)
SElemType *top; // 栈顶指针(初值指向栈底,插入增1,删除减1)
int stacksize; // 栈可用的最大容量
} SqStack;
2.1.1.2 初始化
/* 返回值为Status(状态码) */
Status InitStack(SqStack &S) { // 构造一个空栈S
S.base = new SElemType[MAXSIZE]; // 为顺序栈动态分配数组空间
if(!S.base) { // 若存储分配失败
exit(OVERFLOW);
}
S.top = S.base; // top初值为base(空栈)
S.stacksize = MAXSIZE; // 栈可用的最大容量为MAXSIZE
return OK;
}
2.1.1.3 入栈
/* 返回值为Status(状态码) */
Status Push(SqStack &S, SElemType e) { // 插入元素e为新的栈顶元素
if(S.top - S.base == S.stacksize) { // 若栈空间已满
return ERROR;
}
*S.top++ = e; // 元素e压入栈顶,栈顶指针加1
return OK;
}
2.1.1.4 出栈
/* 返回值为Status(状态码) */
Status Pop(SqStack &S, SElemType &e) { // 删除S栈顶元素,用e返回
if(S.top == S.base) { // 若栈为空
return ERROR;
}
*S.top++ = e; // 栈顶指针减1,将栈顶元素赋值给e
return OK;
}
2.1.1.5 取栈顶元素
/* 返回值为SElemType(栈元素) */
SElemType GetTop(SqStack S) { // 返回S的栈顶元素
if(S.top != S.base) { // 若栈不为空
return *(S.top - 1); // 返回栈顶元素的值
}
}
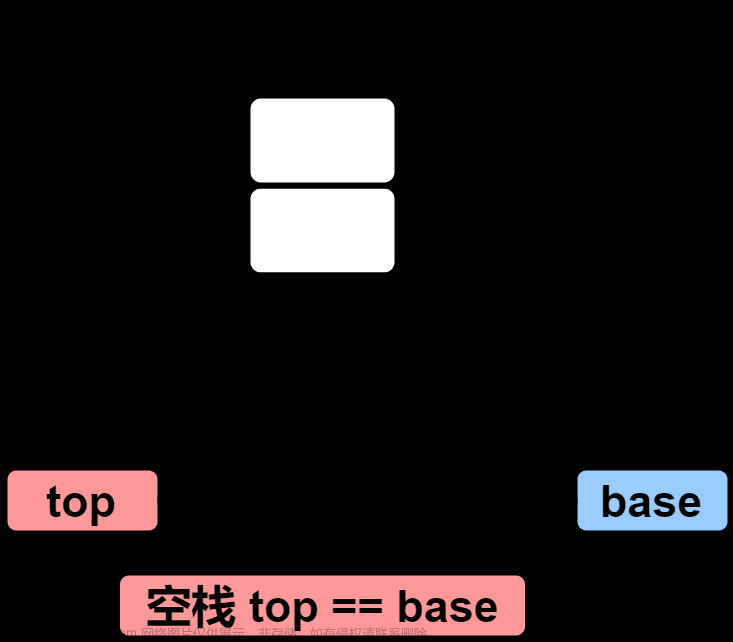
2.1.1.6 判断栈空
/* 返回值为bool(是否为空栈) */
bool StackEmpty(S) {
if(S.top == S.base) {
return true; // 若栈空,返回true
} else {
return false; // 若栈非空,返回false
}
}
2.1.2 链栈的表示和实现
2.1.2.1 链栈的存储结构
typedef struct StackNode {
SElemType data;
struct StackNode *next;
} StackNode, *LinkStack;
2.1.2.2 初始化
/* 返回值为Status(状态码) */
Status InitStack(LinkStack &S) { // 构造一个空栈S
S = NULL; // 将栈顶指针S置空
return OK;
}
2.1.2.3 入栈
/* 返回值为Status(状态码) */
Status Push(LinkStack &S, SElemType e) { // 在栈顶插入元素e
p = new StackNode; // 生成新结点
p->data = e; // 将新结点数据域置为e
p->next = S; // 将新结点指针域链接到原栈顶元素
S = p; // 将栈顶指针移动到p
return OK;
}
2.1.2.4 出栈
/* 返回值为Status(状态码) */
Status Pop(LinkStack &S, SElemType &e) { // 删除S栈顶元素,用e返回
if(S == NULL) { // 若栈为空
return ERROR;
}
e = S->data; // 将栈顶元素(结点*S)的值赋给e
StackNode *p; // 引入辅助指针p
p = S; // 将栈顶元素(结点*S)赋给*p
S = S->next; // 将栈顶指针S移动到后继结点(新的栈顶元素)
delete p; // 释放该出栈元素的空间
return OK;
}
2.1.2.5 取栈顶元素
/* 返回值为SElemType(栈元素) */
SElemType GetTop(LinkStack S) { // 返回S的栈顶元素
if(S != NULL) { // 若栈不为空
return S->data; // 返回栈顶元素(结点*S)的值
}
}
2.2 栈与递归
2.2.1 采用递归算法解决的问题
2.2.1.1 定义是递归的
/* 阶乘函数 */
long Fact(long n) {
if(n == 0) { // 最后一次调用终止递归
return 1;
} else { // 以参数执行递归调用,依次返回值
return n*Fact(n-1);
}
}
/* 二阶斐波那契数列 */
long Fib(long n) {
if(n==1 || n==2) {
return 1;
} else {
return Fib(n-1)+Fib(n-2);
}
}
2.2.1.2 数据结构是递归的
/* 遍历输出链表中各个结点的递归算法 */
void TraverseList(LinkList p) {
if(p==NULL) { // 递归终止
return;
} else {
cout << p->data << endl; // 输出当前结点的数据域
TraverseList(p->next); // 指针p移动到后继结点继续递归
}
}
/* 若递归终止只执行return,可简化为 */
void TraverseList(LinkList p) {
if(p) {
cout << p->data << endl; // 输出当前结点的数据域
TraverseList(p->next); // 指针p移动到后继结点继续递归
}
}
2.2.1.3 问题的解法是递归的
/* 汉诺塔问题的递归算法 */
int m = 0;
void move(char A, int n, char C) { // 对搬动进行计数
cout << ++m << "," << n << "," << A << "," << C << endl;
}
// 将塔A上的n个圆盘按规则移动到C上,B做辅助塔
void Hanoi(int n, char A, char B, char C) {
if(n==1) {
move(A, 1, C); // 将1号圆盘从A移动到C
} else {
Hanoi(n-1, A, B, C); // 将A上1到n-1号圆盘移动到B,C做辅助塔
move(A, n, C); // 将1号圆盘从A移到C
Hanoi(n-1, B, A, C); // 将B上1到n-1号圆盘移动到C,A做辅助塔
}
}
2.2.2 递归过程与递归工作栈
/* 阶乘函数Fact(4)递归过程中递归工作栈和活动记录的使用 */
void main() {
long n; // 调用Fact(4)时记录进栈
n = Fact(4); // 返回地址RetLoc1在赋值语句
}
long Fact(long n) {
long temp;
if(n == 0) { // 最后一次调用终止递归
return 1; // 活动记录退栈
} else { // 以参数执行递归调用,依次返回值
temp = n*Fact(n-1); // 活动记录进栈
} // 返回地址RetLoc2在计算语句
return temp; // 活动记录退栈
}
2.3 队列的表示和操作的实现
2.3.1 循环队列——队列的顺序表示和实现
2.3.1.1 队列的顺序存储结构
#define MAXQSIZE 100 // 队列可能达到的最大长度
typedef struct {
QElemType *base; // 存储空间的基地址
int front; // 头指针
int rear; // 尾指针
} SqQueue;
2.3.1.2 初始化
/* 返回值为Status(状态码) */
Status InitQueue(SqQueue &Q) { // 构造一个空队列Q
Q.base = new QElemType[MAXQSIZE]; // 为队列分配一个数组空间
if(!Q.base) { // 若存储分配失败
exit(OVERFLOW);
}
Q.front = Q.rear = 0; // 头指针和尾指针设为0,队列为空
return OK;
}
2.3.1.3 求队列长度
/* 返回值为int(队列长度) */
int QueueLength(SqQueue Q) { // 返回Q的元素个数
return (Q.rear - Q.front + MAXQSIZE) % MAXQSIZE;
}
2.3.1.4 入队
/* 返回值为Status(状态码) */
Status EnQueue(SqQueue &Q, QElemType e) { // 插入e为新的队尾元素
if((Q.rear+1)%MAXQSIZE == Q.front) { // 若尾指针加1等于头指针
return ERROR; // 队满
}
Q.base[Q.rear] = e; // 新元素插入队尾
Q.rear = (Q.rear + 1) % MAXQSIZE; // 尾指针移动到下一个位置
return OK;
}
2.3.1.5 出队
/* 返回值为Status(状态码) */
Status DeQueue(SqQueue &Q, QElemType &e) { // 删除队头元素并返回
if(Q.rear == Q.front) { // 若队空
return ERROR;
}
e = Q.base[Q.front]; // 保存队头元素到e
Q.front = (Q.front + 1) % MAXQSIZE; // 头指针移动到下一个位置
return OK;
}
2.3.1.6 取队头元素
/* 返回值为QElemType(队列元素) */
QElemType GetHead(SqQueue Q) { // 返回Q的队头元素,不修改头指针
if(Q.front != Q.rear) { // 若队列非空
return Q.base[Q.front]; // 返回队头元素的值,头指针不变
}
}
2.3.1.7 判断队空
/* 返回值为bool(是否为空队列) */
bool QueueEmpty(Q) {
if(Q.front == Q.rear) {
return true; // 若队空,返回true
} else {
return false; // 若队非空,返回false
}
}
2.3.2 链队——队列的链式表示和实现
2.3.2.1 队列的链式存储结构
typedef struct QNode {
QElemType data;
struct QNode *next;
} QNode, *QueuePtr;
typedef struct {
QueuePtr front; // 队头指针
QueuePtr rear; // 队尾指针
} LinkQueue;
2.3.2.2 初始化
/* 返回值为Status(状态码) */
Status InitQueue(LinkQueue &Q) { // 构造一个空队列Q
Q.front = Q.rear = new QNode; // 生成头结点,头尾指针指向头结点
Q.front->next = NULL; // 头结点的指针域置空
return OK;
}
2.3.2.3 入队
/* 返回值为Status(状态码) */
Status EnQueue(LinkQueue &Q, QElemType e) { // 插入e为新的队尾元素
p = new QNode; // 动态分配结点空间给新结点*p
p->data = e; // p的数据域赋值e
p->next = NULL; // p的指针域置空
Q.rear->next = p; // 尾指针链接到p
Q.rear = p; // 尾指针移动到p
return OK;
}
2.3.2.4 出队
/* 返回值为Status(状态码) */
Status DeQueue(LinkQueue &Q, QElemType &e) { // 删除队头元素并返回
if(Q.front == Q.rear) { // 若队列为空
return ERROR;
}
p = Q.front->next; // p置为头结点指针域(队头元素)
e = p->data; // e保存队头元素的值
Q.front->next = p->next; //头结点指针域置为p指针域(队头的下一个)
if(Q.rear == p) { // 若p到达队尾(最后一个元素被删)
Q.rear = Q.front; // 尾指针移动到头结点
}
delete p; // 释放原队头元素的空间
return OK;
}
2.3.2.5 取队头元素
/* 返回值为QElemType(队列元素) */
QElemType GetHead(LinkQueue Q) { // 返回Q的队头元素,不修改头指针
if(Q.front != Q.rear) { // 若队列非空
return Q.front->next->data; // 返回队头元素的值,头指针不变
}
}
2.4 案例分析与实现
2.4.1 数制的转换
/* 无返回值void */
void conversion(int N) { // 非负十进制数转为八进制数,打印输出
InitStack(S); // 初始化空栈S
while(N) { // 当N非零时,循环以下操作(短除法)
Push(S, N%8); // 将N与8取模运算的余数入栈
N = N/8; // N更新为N除以8的商
}
while(!StackEmpty(S)) { // 当栈非空时,循环以下操作(先进后出)
Pop(S, e); // 将栈顶元素e出栈
cout << e; // 输出e
}
}
2.4.2 括号匹配的检验
/* 返回值为Status(状态码) */
Status matching() { //检验以#结尾的表达式中括号是否匹配,返回布尔值
InitStack(S); // 初始化空栈S
flag = 1; // 设置一个flag标记匹配结果(初值为真)
cin >> ch; // 开始读取字符
while(ch!='#' && flag) { // 当字符不是#且标记为真时,循环操作:
switch(ch) { // 匹配字符值
case '[':
case '(':
Push(S, ch); // 若是左括号[或(,则将其入栈
break;
case ')': // 若是右括号)
if(!StackEmpty(S) && GetTop(S)=='(') {
Pop(S, x); // 若栈非空且栈顶元素为(,将(出栈(匹配正确)
} else {
flag = 0; // 否则标记为假(匹配错误)
}
break;
case ']': // 若是右括号]
if(!StackEmpty(S) && GetTop(S)=='[') {
Pop(S, x); // 若栈非空且栈顶元素为[,将[出栈(匹配正确)
} else {
flag = 0; // 否则标记为假(匹配错误)
}
break;
}
cin >> ch; // 读取下一个字符
}
if(StackEmpty(S) && flag) {
return true; // 若栈空且标记为真,则匹配成功,返回true
} else {
return false; // 否则匹配失败,返回false
}
}
2.4.3 表达式求值
/* 返回值为char(字符) */
char EvalExpr() { // 算术表达式求值的算符优先法,设置两个工作栈
InitStack(OPTR); // 初始化空栈OPTR(寄存运算符)
InitStack(OPND); // 初始化空栈OPND(寄存操作数或运算结果)
Push(OPTR, '#'); // 先将表达式的起始符#入栈
cin >> ch; // 开始读取字符
while(ch!='#' || GetTop(OPTR)!='#') { // 未到结束符时循环操作:
if(!In(ch)) { // 若ch不是运算符
Push(OPND, ch); // 将ch入栈OPND
cin >> ch; // 读取下一个字符
} else { // 若ch是运算符
switch(Precede(GetTop(OPTR), ch)) { // 匹配优先级
case '<': // 若OPTR栈顶元素(运算符)优先级小于ch(运算符)
Push(OPTR, ch); // 将ch入栈OPTR
cin >> ch; // 读取下一个字符
break;
case '>': // 若OPTR栈顶元素(运算符)优先级大于ch(运算符)
Pop(OPTR, theta); // 将OPTR栈顶元素(运算符)出栈
Pop(OPND, b); // 将OPND栈顶元素(操作数)出栈
Pop(OPND, a); // 将OPND栈顶元素(操作数)出栈
Push(OPND, Operate(a, theta, b)); //将运算结果入栈OPND
break;
case '=': // 若OPTR栈顶元素与ch匹配括号()
Pop(OPTR, x); // 将OPTR栈顶元素(出栈
cin >> ch; // 读取下一个字符
break;
}
}
}
return GetTop(OPND); // 最终,OPND栈顶元素即为表达式求值结果
}
/* 判断字符是否为运算符,返回布尔值 */
bool In(char ch) {
if(ch == '+' || ch == '-' || ch == '*' || ch == '/' || ch == '(' || ch == ')' || ch == '#') {
return true;
} else {
return false;
}
}
/* 比较栈顶元素与ch的运算优先级,返回><= */
char Precede(char top, char ch) {
char operators[6] = {'(', '*', '/', '+', '-', ')', '#'};
int ti, ci;
for(i=0; i<6; i++) {
if(top == operators[i]) {
ti = i;
}
if(ch == operators[i]) {
ci = i;
}
}
if(top == '(') {
if(ch == ')') {
return '=';
} else {
return '<';
}
} else {
if(ti < ci) {
return '>';
} else {
return '<';
}
}
}
/* 根据运算符+操作数返回运算结果(一位数) */
int Operate(char opr, int a, int b) {
switch(opr) {
case '+':
return a+b;
case '-':
return a-b;
case '*':
return a*b;
case '/':
return a/b;
}
}
// 上述算法中操作数只能为一位数,因为使用的OPND为字符栈;若要进行多位数运算,需将OPND改为数栈(读取的数字字符拼成数后再入栈)
2.4.4 舞伴问题
/* 某个舞者的信息 */
typedef struct {
char name[20]; // 姓名
char sex; // 性别(男性'M' 女性'F')
}Person; // 定义队列元素的类型
/* 队列的顺序存储结构 */
#define MAXQSIZE 100 // 队列可能达到的最大长度
typedef struct {
Person *base; // 存储空间的基地址
int front; // 头指针
int rear; // 尾指针
}SqQueue;
SqQueue Mdancers, Fdancers; // 声明男队和女队
/* 舞伴问题:数组dancer存放所有舞者信息,num为人数 */
void DancerPartner(Person dancer[], int num) {
InitQueue(Mdancers); // 初始化队列Mdancers
InitQueue(Fdancers); // 初始化队列Fdancers
for(i=0; i<num; i++) { // 遍历数组dancer
p = dancer[i]; // 获取某个舞者信息
if(p.sex == 'F') {
EnQueue(Fdancers, p); // 若舞者性别为女,则进入女队
} else {
EnQueue(Mdancers, p); // 否则进入男队
}
}
cout << "Partners are:\n";
while(!QueueEmpty(Fdancers) && !QueueEmpty(Mdancers)) {
DeQueue(Fdancers, p); // 两队都非空时,依次将女队头元素出队
cout << p.name << " "; // 依次输出女伴姓名
DeQueue(Mdancers, p); // 两队都非空时,依次将男队头元素出队
cout << p.name << endl; // 依次输出男伴姓名
}
if(!QueueEmpty(Fdancers)) { // 结伴完成后,若女队还剩人
p = GetHead(Fdancers); // 获取女队头元素
cout << "Next round Female leader is: " << p.name << endl;
} else if(!QueueEmpty(Mdancers)) { // 若男队还剩人
p = GetHead(Mdancers); // 获取男队头元素
cout << "Next round Male leader is: " << p.name << endl;
}
}
3、串、数组和广义表
3.1 串
3.1.1 串的存储结构
3.1.1.1 串的定长顺序存储结构
#define MAXLEN 255 // 串的最大长度(静态定义)
typedef struct {
char ch[MAXLEN+1]; // 存储串的一维数组(每个分量存储一个字符)
int length; // 串的长度(下标0的分量闲置不用)
} SString;
3.1.1.2 串的堆式顺序存储结构
typedef struct {
char *ch; // 若非空串,则按串长分配存储区,否则ch为NULL
int length; // 串的长度(下标0的分量闲置不用)
} HString;
3.1.1.3 串的链式存储结构
#define CHUNKSIZE 80 // 自定义的块大小
typedef struct Chunk{
char ch[CHUNKSIZE];
struct Chunk *next;
} Chunk;
typedef struct {
Chunk *head, *tail; // 头指针和尾指针
int length; // 串的长度
} LString;
3.1.2 串的模式匹配算法
3.1.2.1 BF算法
/* 返回值为int(子串位置) */
int Index_BF(SString S, SString T, int pos) { // 从pos位开始查找
i = pos; // 主串当前待匹配的字符位置(初值为pos)
j = 1; // 子串当前待匹配的字符位置(初值为1)
while(i<=S.length && j<=T.length) { // 当S,T未完成比较,循环:
if(S.ch[i] == T.ch[j]) { // 若 S中第i个字符==T中第j个字符
++i; // 指针i+1(继续比较下一位)
++j; // 指针j+1(继续比较下一位)
} else { // 否则
i = i-j+2; // 将i退回本次起始位置的下一个位置(重新开始匹配)
j = 1; // 将j退回第1个位置(重新开始匹配)
}
}
if(j > T.length) {
return i-T.length; // 匹配成功,返回匹配到的子串位置
} else {
return 0; // 匹配失败,返回0
}
}
3.1.2.2 KMP算法
/* 返回值为int(子串位置) */
int Index_KMP(SString S, SString T, int pos) { //从pos位开始查找
i = pos; // 主串当前待匹配的字符位置(初值为pos)
j = 1; // 子串当前待匹配的字符位置(初值为1)
while(i<=S.length && j<=T.length) { // 当S,T未完成比较,循环:
if(j==0 || S.ch[i]==T.ch[j]) { // 若子串归零或比较相等
++i; // 指针i+1(继续比较下一位)
++j; // 指针j+1(继续比较下一位)
} else {
j = next[j]; // 否则子串向右移动,将next[j]位置与i进行比较
}
}
if(j > T.length) {
return i-T.length; // 匹配成功,返回匹配到的子串位置
} else {
return 0; // 匹配失败,返回0
}
}
// 计算next函数值(求模式串中每个字符的退回位置,存入数组next[])
void get_next(SString T, int next[]) {
i = 1; // 以模式T为主串(i初值为1)
next[1] = 0; // 令next[1] = 0(函数定义)
j = 0; // 以模式T为子串(j初值为0)
while(i < T.length) { // 当比较未完成时,循环以下操作:
if(j==0 || T.ch[i]==T.ch[j]) { // 若子串归零或比较相等
++i; // 指针i+1(继续比较下一位)
++j; // 指针j+1(继续比较下一位)
next[i] = j; // 第i位的退回位置为j
} else {
j = next[j]; // 否则j退回到next[j]
}
}
}
// 计算next函数的修正值
void get_nextval(SString T, int nextval[]) {
i = 1; // 以模式T为主串(i初值为1)
nextval[1] = 0; // 令nextval[1] = 0(函数定义)
j = 0; // 以模式T为子串(j初值为0)
while(i < T.length) { // 当比较未完成时,循环以下操作:
if(j==0 || T.ch[i]==T.ch[j]) { // 若子串归零或比较相等
++i; // 指针i+1(继续比较下一位)
++j; // 指针j+1(继续比较下一位)
if(T.ch[i] != T.ch[j]) { // 若下一位比较不等
nextval[i] = j; // 第i位的退回位置为j
} else {
nextval[i] = nextval[j]; // 否则第i位退回到第j位的nextval
}
} else {
j = nextval[j]; // 否则j退回到nextval[j]
}
}
}
3.2 广义表
3.2.1 广义表的存储结构
/* 广义表的头尾链式存储表示 */
typedef enum {ATOM, LIST} ElemTag; //ATOM==0即原子 LIST==1即子表
typedef struct GLNode {
ElemTag tag; // 标志域tag,用于区分原子结点和表结点
union {
AtomType atom; // 原子结点,值域atom
struct {
struct GLNode *hp, *tp;
} ptr; // 表结点的指针域:ptr.hp指向表头,ptr.tp指向表尾
};
} *GList; // 广义表类型为GList
3.3 案例分析与实现
3.3.1 病毒感染检测
/* 无返回值void */
void Virus_detection() { // 利用BF算法实现病毒检测
ifstream inFile("病毒感染检测输入数据.txt"); // 打开并读取文件
ofstream outFile("病毒感染检测输出结果.txt"); // 创建并写入文件
inFile >> num; // 从文件读取待检测的任务数num
while(num--) { // 依次从num行向前进行以下操作:
inFile >> Virus.ch+1; // 读取病毒DNA(后移1位,下标1开始存放)
inFile >> Patient.ch+1; //读取患者DNA(后移1位,下标1开始存放)
Vir = Virus.ch; // 病毒DNA保存到Vir
flag = 0; // 标记是否匹配,初值为0(未匹配)
m = Virus.length; // 病毒DNA长度m
for(i=m+1,j=1; j<=m; j++) {
Virus.ch[i++] = Virus.ch[j]; // 病毒字符串长度扩大到2m
}
Virus.ch[2*m+1] = '\0'; // 添加结束符\0
for(i=0; i<m; i++) { // 依次获取每个长度为m的模式串
for(j=1; j<=m; j++) {
temp.ch[j] = Virus.ch[i+j]; // 存入数组temp
}
temp.ch[m+1] = '\0'; // 添加结束符\0
flag = Index_BF(Patient, temp, 1); // 模式匹配并标记结果
if(flag) {
break; // 匹配成功则退出循环
}
}
if(flag) { // 匹配成功
outFile << Vir+1 << " " << Patient.ch+1 << " " << "YES" << endl;
} else { // 匹配失败
outFile << Vir+1 << " " << Patient.ch+1 << " " << "No" << endl;
}
}
}
4、树和二叉树
4.1 二叉树
4.1.1 二叉树的存储结构
4.1.1.1 顺序存储结构
#define MAXTSIZE 100 // 二叉树的最大结点数
typedef TElemType SqBiTree[MAXTSIZE]; // 0号单元存储根结点
SqBiTree bt;
4.1.1.2 链式存储结构
/* 二叉树的二叉链表存储表示 */
typedef struct BiTNode {
TElemType data; // 结点数据域
struct BiTNode *lchild, *rchild; // 左右孩子指针
} BiTNode, *BiTree;
4.1.2 遍历二叉树
4.1.2.1 中序遍历的递归算法
/* 无返回值void */
void InOrderTraverse(BiTree T) { // 中序遍历二叉树T的递归算法
if(T) { // 若T非空
InOrderTraverse(T->lchild); // 中序遍历左子树
cout << T->data; // 访问根结点
InOrderTraverse(T->rchild); // 中序遍历右子树
}
}
// 改变输出语句的顺序,便可实现先序遍历和后序遍历
4.1.2.2 中序遍历的非递归算法
/* 无返回值void */
void InOrderTraverse(BiTree T) { // 中序遍历二叉树T的非递归算法
InitStack(S); // 初始化栈S
p = T; // 头指针p(指向根结点)
q = new BiTNode; // 指针q(指向当前结点)
while(p || !StackEmpty(S)) { // 当p非空或栈非空时,循环操作:
if(p) { // 若头指针p非空
Push(S, p); // 将p入栈
p = p->lchild; // p移动到左孩子结点(遍历左子树)
} else { // 若头指针p为空
Pop(S, q); // 将栈顶元素q出栈(退回上一层)
cout << q->data; // 输出q的数据域
p = q->rchild; // p移动到q的右孩子结点(遍历右子树)
}
}
}
// 改变输出语句的顺序,便可实现先序遍历和后序遍历
4.1.2.3 创建二叉树的存储结构——二叉链表
/* 无返回值void */
void CreateBiTree(BiTree &T) { // 按先序输入结点值,创建二叉链表
cin >> ch; // 读取一个输入字符
if(ch == '#') { // 若字符为#
T = NULL; // T置空(递归结束)
} else { // 若字符不为#
T = new BiTNode; // 生成根结点(指针T)
T->data = ch; // 根结点数据域赋为ch
CreateBiTree(T->lchild); // 递归创建左子树
CreateBiTree(T->rchild); // 递归创建右子树
}
}
4.1.2.4 复制二叉树
/* 无返回值void */
void Copy(BiTree T, BiTree &newT) { //复刻一棵与T完全相同的二叉树
if(T == NULL) { // 若T为空
newT = NULL; // newT置空
return; // 递归结束
} else { // 若T非空
newT = new BiTNode; // 生成newT根结点
newT->data = T->data; // 将T数据域复制到newT数据域
Copy(T->lchild, newT->lchild); // 递归复制左子树
Copy(T->rchild, newT->rchild); // 递归复制右子树
}
}
4.1.2.5 计算二叉树的深度
/* 返回值为int(深度) */
int Depth(BiTree T) { // 计算二叉树T的深度
if(T == NULL) { // 若T为空
return 0; // 深度为0(递归结束)
} else { // 若T非空
m = Depth(T->lchild); // 递归计算左子树深度
n = Depth(T->rchild); // 递归计算右子树深度
if(l > r) { // 返回数值更大的深度
return m+1;
} else {
return n+1;
}
}
}
4.1.2.6 统计二叉树中结点的个数
/* 返回值为int(个数) */
int NodeCount(BiTree T) { // 统计二叉树T中结点的个数
if(T == NULL) { // 若T为空
return 0; // 结点数为0(递归结束)
} else { // 若T非空,递归获取左子树+右子树+1(结点总数)并返回
return NodeCount(T->lchild) + NodeCount(T->rchild) + 1;
}
}
4.1.3 线索二叉树
4.1.3.1 线索二叉树的基本概念
/* 二叉树的二叉线索存储表示 */
typedef struct BiThrNode {
TElemType data;
struct BiThrNode *lchild, *rchild; // 左右孩子指针
int LTag, RTag; // 左右标志
} BiThrNode, *BiThrTree;
4.1.3.2 构造线索二叉树
BiThrNode *pre; // 指针pre始终指向刚访问过的结点(记录访问顺序)
pre->rchild = NULL; // 初始化时其右孩子为空(从左开始建立线索)
/* 带头结点的二叉树中序线索化 */
void InOrderThreading(BiThrTree &Thrt, BiThrTree T) {
Thrt = new BiThrNode; // 生成头结点Thrt
Thrt->lTag = 0; // 头结点的左标志改为0(左孩子)
Thrt->rTag = 1; // 头结点的右标志改为1(后继)
Thrt->rchild = Thrt; // 头结点的右指针指向自己(初值)
if(!T) { // 若T为空
Thrt->lchild = Thrt; // 头结点的左指针也指向自己
} else { // 若T非空
Thrt->lchild = T; // 头结点的左指针指向根结点
pre = Thrt; // pre指向头结点(初值)
InThreading(T); // 调用InThreading对以T为根的二叉树进行线索化
pre->rchild = Thrt; // pre已移动到最后,令其右指针指向头结点
pre->rTag = 1; // pre右标志改为1(后继)
Thrt->rchild = pre; // 头结点右指针指向pre
}
}
/* 以结点p为根的子树中序线索化 */
void InThreading(BiThrTree p) {
if(p) {
InThreading(p->lchild); // p的左子树递归线索化
if(!(p->lchild)) { // 若p的左孩子为空
p->lTag = 1; // 左标志改为1
p->lchild = pre; // 左指针指向pre(p的前驱)
} else { // 若p的左孩子非空
p->lTag = 0; // 左标志改为0(左指针指向左孩子)
}
if(!(pre->rchild)) { // 若pre的右孩子为空
pre->rTag = 1; // 右标志改为1
pre->rchild = p; // 右指针指向p(pre的后继)
} else { // 若pre的右孩子非空
pre->rTag = 0; // 右标志改为0(右指针指向右孩子)
}
pre = p; // 将pre移动到p(访问记录)
InThreading(p->rchild); // p的右子树递归线索化
}
}
4.1.3.3 遍历线索二叉树
/* 无返回值void */
void InOrderTraverse_Thr(BiThrTree H) { // 遍历中序线索二叉树
p = H->lchild; // p指示头结点H的左孩子(根结点)
while(p != H) { // 当p不指示H时,循环操作:
while(p->lTag == 0) { //当p的左标志为0(左孩子)时,循环操作:
p = p->lchild; // p移动到左孩子
}
cout << p->data; // 输出p的数据域
while(p->rTag == 1 // 当p的右标志为1且右指针不指向H时
&&
p->rchild != H) {
p = p->rchild; // p移动到后继
cout << p->data; // 输出p的数据域
}
p = p->rchild; // p移动到右子树
}
}
4.2 树和森林
4.2.1 树的存储结构
/* 树的二叉链表(孩子-兄弟)存储表示 */
typedef struct CSNode {
ElemType data;
struct CSNode *firstchild, *nextsibling;
} CSNode, *CSTree;
4.3 哈夫曼树及其应用
4.3.1 哈夫曼树的存储表示
typedef struct {
int weight; // 结点的权值
int parent, lchild, rchild; // 结点的双亲、左孩子、右孩子的下标
} HTNode, *HuffmanTree; // 动态分配数组存储哈夫曼树
4.3.2 构造哈夫曼树
/* 无返回值void */
void CreateHaffmanTree(HuffmanTree &HT, int n) { //构造哈夫曼树HT
if(n <= 1) { // 若根结点少于两个
return; // 退出
}
/* 初始化 */
m = 2*n - 1; // 哈夫曼树的结点总数m=2n-1
HT = new HTNode[m+1]; // 0号弃用,故分配m+1个单元(下标1 ~ m)
for(i=1; i<=m; ++i) { // 初始化每个结点的双亲、左右孩子的下标为0
HT[i].parent = 0;
HT[i].lchild = 0;
HT[i].rchild = 0;
}
for(i=1; i<=n; ++i) { // 前n个单元存储叶子结点(下标1 ~ n)
cin >> HT[i].weight; // 输入每个叶子结点的权值
}
/* 创建树 */
for(i=n+1; i<=m; ++i) { // 后n-1个单元存储根结点(下标n-1 ~ m)
Select(HT, i-1, s1, s2); // 选取权值最小的两个叶子/根结点
HT[s1].parent = i; // 令HT[s1]双亲为HT[i]
HT[s2].parent = i; // 令HT[s2]双亲为HT[i]
HT[i].lchild = s1; // 令HT[i]左孩子为HT[s1]
HT[i].rchild = s2; // 令HT[i]右孩子为HT[s2]
HT[i].weight = HT[s1].weight + HT[s2].weight; // 令HT[i]的权值为HT[s1]和HT[s2]的权值之和
}
}
/* 在叶子/根结点中选取两个双亲为0且权值最小的结点,返回其下标 */
int count;
struct Root {
int index;
int weight;
};
void Select(HTNode arr[], int len, int s1, int s2) {
/* 提取双亲为0的结点(下标+权值) */
count = 0;
struct Root Roots[len+1];
for(i=1; i<=len; i++) {
if(arr[i].parent == 0) {
count++;
roots[count-1].index = i;
roots[count-1].weight = arr[i].weight;
}
}
/* 插入排序算法 */
int i,j,temp;
for(i=1; i<len; i++) {
temp = roots[i].weight;
for(j=i; j>0 && roots[j-1].weight>temp; j--) {
roots[j] = roots[j-1];
}
roots[j].weight = temp;
}
/* 返回结点下标 */
s1 = roots[0].index;
s2 = roots[1].index;
return;
}
4.3.3 哈夫曼编码
4.3.3.1 哈夫曼编码表的存储表示
/* 动态分配数组存储哈夫曼编码表 */
typedef char **HuffmanCode; // 0号单元弃用,从1号单元开始存储
4.3.3.2 根据哈夫曼树求哈夫曼编码
/* 无返回值void */
void CreateHaffmanCode(HuffmanTree HT, HuffmanCode &HC, int n) {
HC = new char*[n+1]; // 给指针数组HC分配n+1个单元(存储n个字符)
cd = new char[n]; // 临时存放编码的动态数组空间cd(字符串)
cd[n-1] = '\0'; // cd最后一位存放结束符
for(i=1; i<=n; ++i) { // 从树HT的1号单元开始逐个字符求编码:
start = n-1; // 记录当前编码临时存放在cd的下标(初值为末位)
c = i; // 记录树HT当前结点的下标
f = HT[i].parent; // 记录树HT当前结点双亲的下标
while(f != 0) { // 当f不为0(当前结点有双亲),循环操作:
--start; // start向前移动一位
if(HT[f].lchild == c) { // 若当前结点为双亲的左孩子
cd[start] = '0'; // 临时存放0
} else {
cd[start] = '1'; // 临时存放1
}
c = f; // c移动到双亲结点(当前结点)
f = HT[f].parent; // f移动到c的双亲结点(当前结点的双亲)
}
HC[i] = new char[n-start]; // 为当前字符编码表(指针)分配空间
strcpy(HC[i], &cd[start]); // 令HC当前下标的指针链到cd的首地址
}
delete cd; // 释放临时空间
}
4.4 案例分析与实现
4.4.1 利用二叉树求解表达式的值
4.4.1.1 表达式树的创建
/* 无返回值void */
void InitExpTree() { // 表达式树的创建算法
InitStack(OPTR); // 初始化空栈OPTR(暂存运算符)
InitStack(EXPT); // 初始化空栈EXPT(暂存已建好的树的根结点)
Push(OPTR, '#'); // 先将表达式的起始符#入栈
cin >> ch; // 开始读取字符
while(ch!='#' || GetTop(OPTR)!='#') { //当未到结束符,循环操作:
if(!In(ch)) { // 若ch不是运算符
CreateExpTree(T, NULL, NULL, ch); //创建只有根结点ch的二叉树
Push(EXPT, T); // 将根结点T入栈EXPT
cin >> ch; // 读取下一个字符
} else { // 若ch是运算符
switch(Precede(GetTop(OPTR), ch)) { // 匹配运算符优先级
case '<': // 若OPTR栈顶元素(运算符)优先级小于ch(运算符)
Push(OPTR, ch); // 将ch入栈OPTR
cin >> ch; // 读取下一个字符
break;
case '>': // 若OPTR栈顶元素(运算符)优先级大于ch(运算符)
Pop(OPTR, theta); // 将OPTR栈顶元素(运算符)出栈
Pop(EXPT, b); // 将EXPT栈顶元素(操作数)出栈
Pop(EXPT, a); // 将EXPT栈顶元素(操作数)出栈
CreateExpTree(T, a, b, theta); // 以theta为根、a为左子树、b为右子树创建二叉树
Push(EXPT, T); // 将根结点T入栈EXPT
break;
case '=': // 若OPTR栈顶元素与ch匹配括号()
Pop(OPTR, x); // 将OPTR栈顶元素(出栈
cin >> ch; // 读取下一个字符
break;
}
}
}
}
/* 判断字符是否为运算符,返回布尔值 */
bool In(char ch) {
if(ch == '+' || ch == '-' || ch == '*' || ch == '/' || ch == '(' || ch == ')' || ch == '#') {
return true;
} else {
return false;
}
}
/* 由两个操作数(左右子树)+一个运算符(根)创建二叉树 */
void CreateExpTree(BiTree &T, BiTree a, BiTree b, char theta) {
T = new BiTNode;
T->data = theta;
T->lchild = a;
T->rchild = b;
}
/* 比较栈顶元素与ch的运算优先级,返回><= */
char Precede(char top, char ch) {
char operators[6] = {'(', '*', '/', '+', '-', ')', '#'};
int ti, ci;
for(i=0; i<6; i++) {
if(top == operators[i]) {
ti = i;
}
if(ch == operators[i]) {
ci = i;
}
}
if(top == '(') {
if(ch == ')') {
return '=';
} else {
return '<';
}
} else {
if(ti < ci) {
return '>';
} else {
return '<';
}
}
}
4.4.1.2 表达式树的求值
/* 返回值为int(表达式的值) */
int EvaluateExpTree(BiTree T) { // 遍历表达式树进行表达式求值
lvalue = rvalue = 0; // 标记左右操作数(初值为0)
if(T->lchild == NULL && T->rchild == NULL) {
return T->data - '0'; // 若结点为叶子(操作数),返回数值
} else { // 若结点非叶子(运算符)
lvalue = EvaluateExpTree(T->lchild); // 递归计算左子树
rvalue = EvaluateExpTree(T->rchild); // 递归计算右子树
return GetValue(T->data, lvalue, rvalue); //返回当前计算结果
}
}
/* 根据运算符+操作数返回运算结果(一位数) */
int GetValue(char opr, int a, int b) {
switch(opr) {
case '+':
return a+b;
case '-':
return a-b;
case '*':
return a*b;
case '/':
return a/b;
}
}
5、图
5.1 图的存储结构
5.1.1 邻接矩阵
5.1.1.1 邻接矩阵表示法
/* 图的邻接矩阵存储表示 */
#define MaxInt 32767 // 定义极大值∞
#define MVNum 100 // 定义最大顶点数
typedef char VerTexType; // 设顶点的数据类型为字符型char
typedef int ArcType; // 设边的权值的数据类型为整型int
typedef struct {
VerTexType vexs[MVNum]; // 顶点的列表(一维数组)
ArcType arcs[MVNum][MVNum]; // 邻接矩阵(二维数组)
int vexnum, arcnum; // 图的当前顶点数和边数
} AMGraph; // 构造图AMGraph
5.1.1.2 采用邻接矩阵表示法创建无向网
/* 返回值为Status(状态码) */
Status CreateUDN(AMGraph &G) { // 采用邻接矩阵表示法创建无向网G
cin >> G.vexnum >> G.arcnum; // 输入总顶点数、总边数
for(i=0; i<G.vexnum; i++) { // 按总顶点数循环(顶点列表):
cin >> G.vexs[i]; // 输入每个顶点的信息,初始化顶点列表
}
for(i=0; i<G.vexnum; i++) { // 按总顶点数循环(邻接矩阵-行):
for(j=0; j<G.vexnum; j++) { // 按总顶点数二级循环(邻接矩阵-列):
G.arcs[i][j] = MaxInt; // 将每个权值置为∞,初始化邻接矩阵
}
}
for(k=0; k<G.arcnum; k++) { // 按总边数循环,构造邻接矩阵:
cin >> v1 >> v2 >> w; // 依次输入一条边的两个顶点、边的权值
i = LocateVex(G, v1); // 获取v1在G中的位置i(顶点列表中v1的下标)
j = LocateVex(G, v2); // 获取v2在G中的位置j(顶点列表中v2的下标)
G.arcs[i][j] = w; // 将第i行第j列的权值置为w
G.arcs[j][i] = G.arcs[i][j]; // 第j行第i列的权值也为w(无向网为对称矩阵)
}
return OK;
}
/* 返回值为int(数组下标) */
int LocateVex(AMGraph G, char v) { // 获取顶点v在图G中的位置(顶点列表已知)
for(i=0; i<G.vexnum; i++) {
if(v == G.vexs[i]) {
return i;
}
}
}
5.1.2 邻接表
5.1.2.1 邻接表表示法
/* 图的邻接表存储表示 */
#define MVNum 100 // 定义最大顶点数
typedef struct ArcNode {
int adjvex; // 邻接点域(邻接点的下标)
struct ArcNode *nextarc; // 链域(指向下一个边结点)
ArcType info; // 数据域(边的权值)
} ArcNode; // 构造边结点ArcNode
typedef struct VNode {
VerTexType data; // 数据域(顶点信息)
ArcNode *firstarc; // 链域(指向链表中第一个边结点)
} VNode, AdjList[MVNum]; // 构造表头结点VNode、表头结点表AdjList
typedef struct {
AdjList vertices; // 声明表头结点表变量vertices
int vexnum, arcnum; // 图的当前顶点数和边数
} ALGraph; // 构造图ALGraph
5.1.2.2 采用邻接表表示法创建无向图
/* 返回值为Status(状态码) */
Status CreateUDG(ALGraph &G) { // 采用邻接表表示法创建无向网G
cin >> G.nevnum >> G.arcnum; // 输入总顶点数、总边数
for(i=0; i<G.vexnum; i++) { // 按总顶点数循环(表头结点表):
cin >> G.vertices[i].data; // 输入每个顶点的信息
G.vertices[i].firstarc = NULL; // 初始化所有链域为空
}
for(k=0; k<G.arcnum; k++) { // 按总边数循环,构造邻接表:
cin >> v1 >> v2; // 依次输入一条边的两个顶点
i = LocateVex(G, v1); // 获取v1在G中的位置i(顶点列表中v1的下标)
j = LocateVex(G, v2); // 获取v2在G中的位置j(顶点列表中v2的下标)
p1 = new ArcNode; // 生成边结点*p1
p1->adjvex = j; // *p1的邻接点域存放v2下标j(v1的邻接点)
p1->nextarc = G.vertices[i].firstarc; // *p1的链域同步为v1的链域(插入第一个边结点之前)
G.vertices[i].firstarc = p1; // v1的链域指向*p1(成为第一个边结点)
p2 = new ArcNode; // 生成边结点*p2
p2->adjvex = i; // *p2的邻接点域存放v1下标i(v2的邻接点)
p2->nextarc = G.vertices[j].firstarc; // *p2的链域同步为v2的链域(插入第一个边结点之前)
G.vertices[j].firstarc = p2; // v2的链域指向*p2(成为第一个边结点)
}
return OK;
}
/* 返回值为int(数组下标) */
int LocateVex(ALGraph G, char v) { // 获取顶点v在图G中的位置(表头结点表已知)
for(i=0; i<G.vexnum; i++) {
if(v == G.vertices[i].data) {
return i;
}
}
}
5.1.3 十字链表
/* 有向图的十字链表存储表示 */
#define MAX_VERTEX_NUM 20 // 定义最大顶点数
typedef struct ArcBox {
int tailvex, headvex; // 尾域(弧尾顶点下标)、头域(弧头顶点下标)
struct ArcBox *hlink, *tlink; // 链域(指向弧头/弧尾相同的下一条弧)
InfoType *info; // 数据域(指向弧的相关信息)
} ArcBox; // 构造弧结点ArcBox
typedef struct VexNode {
VertexType data; // 数据域(顶点信息)
ArcBox *firstin, *firstout; // 链域(指向以该顶点为弧头/弧尾的第一个弧结点)
} VexNode; // 构造顶点结点VexNode
typedef struct {
VexNode xList[MAX_VERTEX_NUM]; // 声明表头结点表xList
int vexnum, arcnum; // 图的当前顶点数和弧数
} OLGraph; // 构造图OLGraph
5.1.4 邻接多重表
/* 无向图的邻接多重表存储表示 */
#define MAX_VERTEX_NUM 20 // 定义最大顶点数
typedef enum {
unvisited, visited // 0, 1
} VisitIf; // 定义枚举VisitIf
typedef struct EBox {
VisitIf mark; // 标志域(是否已被访问过)
int ivex, jvex; // 边依附的两个顶点的下标
struct EBox *ilink, *jlink; // 指向下一条依附于顶点ivex/jvex的边(边结点)
InfoType *info; // 指向边的相关信息
} EBox; // 构造边结点EBox
typedef struct VexBox {
VertexType data; // 顶点信息
EBox *firstedge; // 指向依附于顶点的第一条边(边结点)
} VexBox; // 构造顶点结点VexBox
typedef struct {
VexBox adjmulist[MAX_VERTEX_NUM]; // 声明表头结点表adjmulist
int vexnum, arcnum; // 图的当前顶点数和边数
} AMLGraph; // 构造图AMLGraph
5.2 图的遍历
5.2.1 深度优先搜索
5.2.1.1 深度优先搜索遍历连通图
bool visited[MVNum]; // 定义数组visited,存储访问标记
/* 采用邻接矩阵表示图的深度优先搜索遍历 */
void DFS_AM(AMGraph G, int v) { // 从邻接矩阵G的第v个顶点出发进行遍历(递归)
cout << v; // 输出v(下标)
visited[v] = true; // 标记第v个顶点为已访问
for(w=0; w<G.vexnum; w++) { // 按总顶点数循环,在第v行依次检查:
if((G.arcs[v][w] != 0) && (!visited[w])) { // 若w为v的邻接点且w未被访问过:
DFS_AM(G, w); // 递归调用(从w出发)
}
}
}
/* 采用邻接表表示图的深度优先搜索遍历 */
void DFS_AL(ALGraph G, int v) { // 从邻接表G的第v个顶点出发进行遍历(递归)
cout << v; // 输出v(下标)
visited[v] = true; // 标记第v个顶点为已访问
p = G.vertices[v].firstarc; // 指针p同步为v链域指向的结点(v的第一个邻接点)
while(p != NULL) { // 当p不为空(顺着边表依次检查):
w = p->adjvex; // 获取邻接点下标w(p的邻接点域)
if(!visited[w]) { // 若w未被访问过:
DFS_AL(G, w); // 递归调用(从w出发)
}
p = p->nextarc; // 指针p移动到下一个边结点
}
}
5.2.1.2 深度优先搜索遍历非连通图
bool visited[MVNum]; // 定义数组visited,存储访问标记
void DFSTraverse(Graph G) { // 对非连通图G进行深度优先搜索遍历
for(v=0; v<G.vexnum; v++) { // 按总顶点数循环:
visited[v] = false; // 初始化标记数组为全部未访问
}
for(v=0; v<G.vexnum; v++) { // 按总顶点数循环:
if(!visited[v]) { // 若v未被访问过:
DFS_xx(G, v); // 调用遍历连通图的算法(从v出发)
}
}
}
5.2.2 广度优先搜索
5.2.2.1 广度优先搜索遍历连通图
/* 引入辅助的数据结构 */
typedef struct {
QElemType *base;
int front;
int rear;
} SqQueue; // 构造队列SqQueue
bool visited[MVNum]; // 定义数组visited,存储访问标记
/* 采用邻接矩阵表示图的广度优先搜索遍历 */
void BFS_AM(AMGraph G, int v) { // 从邻接矩阵G的第v个顶点出发进行遍历
cout << v; // 输出v(下标)
visited[v] = true; // 标记第v个顶点为已访问
InitQueue(Q); // 初始化队列Q
EnQueue(Q, v); // 将顶点v入队
while(!QueueEmpty(Q)) { // 当队列非空(未访问完毕):
DeQueue(Q, u); // 将队头元素出队,存为u
for(w=0; w<G.vexnum; w++) { // 按总顶点数循环,在第u行依次检查:
if((G.arcs[u][w] != 0) && (!visited[w])) { // 若w为u的邻接点且w未被访问过:
cout << w; // 输出w(下标)
visited[w] = true; // 标记第w个顶点为已访问
EnQueue(Q, w); // 将顶点w入队
}
}
}
}
/* 采用邻接表表示图的广度优先搜索遍历 */
void BFS_AL(ALGraph G, int v) { // 从邻接表G的第v个顶点出发进行遍历
cout << v; // 输出v(下标)
visited[v] = true; // 标记第v个顶点为已访问
InitQueue(Q); // 初始化队列Q
EnQueue(Q, v); // 将顶点v入队
while(!QueueEmpty(Q)) { // 当队列非空(未访问完毕):
DeQueue(Q, u); // 将队头元素出队,存为u
p = G.vertices[u].firstarc; // 指针p同步为u链域指向的结点(u的第一个邻接点)
while(p != NULL) { // 当p不为空(顺着边表依次检查):
w = p->adjvex; // 获取邻接点下标w(p的邻接点域)
if(!visited[w]) { // 若w未被访问过:
cout << w; // 输出w(下标)
visited[w] = true; // 标记第w个顶点为已访问
EnQueue(Q, w); // 将顶点w入队
}
p = p->nextarc; // 指针p移动到下一个边结点
}
}
}
5.2.2.2 广度优先搜索遍历非连通图
bool visited[MVNum]; // 定义数组visited,存储访问标记
void BFSTraverse(Graph G) { // 对非连通图G进行广度优先搜索遍历
for(v=0; v<G.vexnum; v++) { // 按总顶点数循环:
visited[v] = false; // 初始化标记数组为全部未访问
}
for(v=0; v<G.vexnum; v++) { // 按总顶点数循环:
if(!visited[v]) { // 若v未被访问过:
BFS_xx(G, v); // 调用遍历连通图的算法(从v出发)
}
}
}
5.3 图的应用
5.3.1 最小生成树
5.3.1.1 普里姆算法
/* 定义结构体数组,记录从U到V-U中选取的权值最小的边 */
struct Aux {
VertexType adjvex; // 最小边在U中的顶点
ArcType lowcost; // 最小边上的权值
} closedge[MVNum]; // 构造数组closedge
/* 以邻接矩阵表示无向网G,从顶点u出发构造最小生成树T,输出T的各条边 */
void MiniSpanTree_Prim(AMGraph G, VertexType u) {
k = LocateVex(G, u); // 获取顶点u在G中的下标k
for(j=0; j<G.vexnum; j++) { // 按总顶点数循环,在第k行依次检查:
if(j != k) { // 排除顶点u本身:
closedge[j] = {u, G.arcs[k][j]}; // 将u关联的边以{adjvex, lowcost}格式依次存入数组中
}
}
closedge[k].lowcost = 0; // 在数组中将u-u权值置空,顶点u自动归入U中
for(i=1; i<G.vexnum; i++) { // 按剩余顶点数循环(n-1):
k = Min(closedge, G); // 获取数组中权值最小的边的下标k
u0 = closedge[k].adjvex; // 权值最小的边在U中的顶点u0(u0∈U)
v0 = G.vexs[k]; // 另一个顶点v0(矩阵第k列即顶点列表中第k个顶点,v0∈V-U)
cout << u0 << v0; // 输出当前边(u0, v0)
closedge[k].lowcost = 0; // 数组中将u0-v0权值置空,顶点u0、v0自动归入U中
for(j=0; j<G.vexnum; j++) { // 按总顶点数二级循环,在第k行依次检查(从v0出发):
if(G.arcs[k][j] < closedge[j].lowcost) { // 若边k-j的权值小于数组中u-j的权值:
closedge[j] = {G.vexs[k], G.arcs[k][j]}; // 将数组中边u-j替换为边k-j
}
}
}
}
/* 返回值为int(数组下标) */
int Min(AMGraph G, Aux closedge[]) { // 获取数组中权值最小的边的下标
min = MaxInt;
k = 0;
for(i=1; i<G.vexnum; i++) {
if((closedge[i].lowcost != 0) && (closedge[i].lowcost < min)) {
min = closedge[i].lowcost;
k = i;
}
}
return k;
}
5.3.1.2 克鲁斯卡尔算法
/* 引入辅助数组 */
struct Aux {
VertexType Head; // 边的第一个顶点
VertexType Tail; // 边的第二个顶点
ArcType lowcost; // 边上的权值
} Edge[arcnum]; // 构造数组Edge,存储边的信息
int Vexset[MVNum]; // 定义数组Vexset,记录每个顶点所在的连通分量
/* 以邻接矩阵表示无向网G,构造最小生成树T,输出T的各条边 */
void MiniSpanTree_Kruskal(AMGraph G) {
Sort(Edge); // 初始化数组Edge并按权值从小到大排序
for(i=0; i<G.vexnum; i++) { // 按总顶点数循环:
Vexset[i] = i; // 每个顶点为一个连通分量,用各自下标区分
}
for(i=0; i<G.arcnum; i++) { // 按总边数循环:
v1 = LocateVex(G, Edge[i].Head); // 获取第i条边的第一个顶点下标
v2 = LocateVex(G, Edge[i].Tail); // 获取第i条边的第二个顶点下标
vs1 = Vexset[v1]; // 获取顶点v1所在连通分量vs1
vs2 = Vexset[v2]; // 获取顶点v2所在连通分量vs2
if(vs1 != vs2) { // 若两顶点不在同一连通分量:
cout << Edge[i].Head << Edge[i].Tail; // 输出边(v1, v2)
for(j=0; j<G.vexnum; j++) { // 按总顶点数二级循环:
if(Vexset[j] == vs2) { // 若第j个顶点在连通分量vs2上:
Vexset[j] = vs1; // 合并到连通分量vs1上(边i已将两个分量连成一个)
}
}
}
}
}
5.3.2 最短路径
5.3.2.1 迪杰斯特拉算法
/* 引入辅助数组 */
bool S[MVNum]; // 记录从源点v0到终点vi是否已被确定最短路径长度
int Path[MVNum]; // 记录从源点v0到终点vi的当前最短路径上,vi的直接前驱顶点下标
ArcType D[arcnum]; // 记录从源点v0到终点vi的当前最短路径长度(弧上的权值)
/* 以邻接矩阵表示有向网G,求第v0个顶点(源点)到其余顶点的最短路径 */
void ShortestPath_DIJ(AMGraph G, int v0) {
n = G.vexnum; // 总顶点数n
for(v=0; v<n; v++) { // 循环n次,在第v0行依次检查:
S[v] = false; // 初始化S每项为false(未确定最短路径)
D[v] = G.arcs[v0][v]; // 初始化D每项为v0-v的权值(当前最短路径)
if(D[v] < MaxInt) { // 若v0-v权值小于∞(有弧):
Path[v] = v0; // Path中顶点v的直接前驱顶点为v0
} else {
Path[v] = -1; // 否则,v的直接前驱为-1
}
}
S[v0] = true; // v0-v0已确定最短路径
D[v0] = 0; // v0-v0路径长度为0
for(i=1; i<n; i++) { // 循环n-1次,依次计算其余顶点:
min = MaxInt; // min初值为∞(循环重置)
for(w=0; w<n; w++) { // 二级循环n次,选择v0-?中最短的路径:
if(!S[w] && (D[w] < min)) { // 若w未确定,且v0-w权值比min更小(循环更新):
v = w; // v更新为当前下标
min = D[w]; // min更新为当前权值
}
}
S[v] = true; // v0-v已确定最短路径
for(w=0; w<n; w++) { // 二级循环n次,以v为中转点选择v0-?中最短的路径:
if(!S[w] && (D[v] + G.arcs[v][w] < D[w])) { // 若w未确定,且(v0-v)+(v-w)权值比v0-w更小(循环更新):
D[w] = D[v] + G.arcs[v][w]; // v0-w路径长度更新为(v0-v)+(v-w)权值
Path[w] = v; // Path中w的直接前驱顶点更新为v
}
}
}
}
5.3.2.2 弗洛伊德算法
/* 引入辅助数组 */
int Path[MVNum][MVNum]; // 最短路径上顶点vj的前一个顶点的下标
ArcType D[MVNum][MVNum]; // 记录顶点vi到vj之间的最短路径长度
/* 以邻接矩阵表示有向网G,求各对顶点i和j之间的最短路径 */
void ShortestPath_Floyd(AMGraph G) {
for(i=0; i<G.vexnum; i++) { // 按总顶点数循环(矩阵第i行):
for(j=0; j<G.vexnum; j++) { // 按总顶点数二级循环(矩阵第j列):
D[i][j] = G.arcs[i][j]; // 获取各对顶点之间初始的路径(权值)
if((D[i][j] < MaxInt) && (i != j)) { // 若i-j权值小于∞且非顶点本身(有弧):
Path[i][j] = i; // Path中顶点j的直接前驱顶点为i
} else {
Path[i][j] = -1; // 否则,j的直接前驱为-1
}
}
}
for(k=0; k<G.vexnum; k++) { // 按总顶点数循环(加入中转点k再进行比较):
for(i=0; i<G.vexnum; i++) { // 按总顶点数二级循环(第i行):
for(j=0; j<G.vexnum; j++) { // 按总顶点数三级循环(第j列):
if(D[i][k] + D[k][j] < D[i][j]) { // 若(i-k)+(k-j)权值比i-j更小(循环更新):
D[i][j] = D[i][k] + D[k][j] // i-j路径长度更新为(i-k)+(k-j)权值
Path[i][j] = Path[k][j]; // Path中j的直接前驱更新为k
}
}
}
}
}
5.3.3 拓扑排序
/* 引入辅助的数据结构 */
typedef struct {
SElemType *base;
SElemType *top;
int stacksize;
} SqStack; // 构造栈SqStack
int indegree[MVNum]; // 存放各顶点入度,没有前驱的顶点入度为0,已输出顶点的后继顶点入度-1
int topo[MVNum]; // 记录拓扑序列的顶点序号
/* 以邻接表表示有向图G,若G无环则生成一个拓扑序列topo[]并返回OK,否则返回ERROR */
Status TopologicalSort(ALGraph G, int topo[]) {
FindInDegree(G, indgree); // 获取各顶点的入度
InitStack(S); // 初始化栈S
for(i=0; i<G.vexnum; i++) { // 按总顶点数循环:
if(indgree[i] == 0) { // 若顶点i的入度为0(无前驱):
Push(S, i); // 将i入栈
}
}
m = 0; // 对输出顶点进行计数(初值为0)
while(!StackEmpty(S)) { // 当栈非空(后进先出):
Pop(S, i); // 将栈顶元素出栈,存为i
topo[m] = i; // 记录拓扑序列(第m个为i)
++m; // 输出顶点计数+1
p = G.vertices[i].firstarc; // 指针p同步为第i个顶点链域指向的结点(i的第一个边结点)
while(p != NULL) { // 当p不为空(顺着边表依次检查):
k = p->adjvex; // 获取边结点的邻接点域值k(顶点下标)
--indegree[k]; // indegree对应顶点的入度-1(删除顶点k和以它为尾的弧)
if(indgree[k] == 0) { // 若k入度减为0:
Push(S, k); // 将k入栈
}
p = p->nextarc; // 指针p移动到下一个边结点
}
}
if(m < G.vexnum) { // 若输出顶点数<总顶点数:
return ERROR; // 则图中有环
} else {
return OK;
}
}
/* 以邻接表表示有向图G,求G中各顶点的入度,存入数组indgree */
void FindInDegree(ALGraph G, int indgree[]) {
for(i=0; i<G.vexnum; i++) { // 按总顶点数循环:
indgree[i] = 0; // 初始化indgree中每个顶点入度为0
}
for(i=0; i<G.vexnum; i++) { // 按总顶点数循环(表头结点表):
p = G.vertices[i].firstarc; // 指针p同步为第i个顶点链域指向的结点(i的第一个边结点)
while(p != NULL) { // 当p不为空(顺着边表依次检查):
++indgree[p->adjvex]; // 边结点的邻接点域值作为顶点下标,indgree中对应顶点的入度+1
p = p->nextarc; // 指针p移动到下一个边结点
}
}
}
5.3.4 关键路径
/* 引入辅助数组 */
ArcType ve[MVNum]; // 事件vi的最早发生时间
ArcType vl[MVNum]; // 事件vi的最迟发生时间
int topo[MVNum]; // 记录拓扑序列的顶点序号
/* 以邻接表表示有向网G,输出G的各项关键活动,返回值为Status(状态码) */
Status CriticalPath(ALGraph G) {
if(!TopologicalSort(G, topo)) { // 调用拓扑排序算法,获取拓扑序列topo;若调用失败(网中有环):
return ERROR; // 返回ERROR
}
n = G.vexnum; // 总顶点数n
for(i=0; i<n; i++) { // 循环n次:
ve[i] = 0; // 初始化每个事件的最早发生时间为0
}
for(i=0; i<n; i++) { // 循环n次,按拓扑顺序求每个事件的最早发生时间:
k = topo[i]; // 获取顶点vi的下标k
p = G.vertices[k].firstarc; // 指针p移动到第k个顶点链域指向的结点(vi的第一个边结点)
while(p != NULL) { // 当p不为空(顺着边表依次检查):
j = p->adjvex; // 获取边结点的邻接点域值j(顶点下标)
if(ve[j] < ve[k] + p->info) { // 若j最早发生时间 < (k最早发生时间 + k-j权值):
ve[j] = ve[k] + p->info; // j最早发生时间更新为(k最早发生时间 + k-j权值)
}
p = p->nextarc; // 指针p移动到下一个边结点
}
}
for(i=0; i<n; i++) { // 循环n次:
vl[i] = ve[n-1]; // 根据ve的值初始化每个事件的最迟发生时间
}
for(i=n-1; i>=0; i--) { // 循环n次,按拓扑逆序求每个事件的最迟发生时间:
k = topo[i]; // 获取顶点vi的下标k
p = G.vertices[k].firstarc; // 指针p移动到第k个顶点链域指向的结点(vi的第一个边结点)
while(p != NULL) { // 当p不为空(顺着边表依次检查):
j = p->adjvex; // 获取边结点的邻接点域值j(顶点下标)
if(vl[k] > vl[j] - p->info) { // 若k最迟发生时间 > (j最迟发生时间 - k-j权值):
vl[k] = vl[j] - p->info; // k最迟发生时间更新为(j最迟发生时间 - k-j权值)
}
p = p->nextarc; // 指针p移动到下一个边结点
}
}
for(i=0; i<n; i++) { // 循环n次,依次检查vi为头的弧是否为关键活动:
p = G.vertices[i].firstarc; // 指针p移动到第i个顶点链域指向的结点(vi的第一个边结点)
while(p != NULL) { // 当p不为空(顺着边表依次检查):
j = p->adjvex; // 获取边结点的邻接点域值j(顶点下标)
e = ve[i]; // 获取活动<vi, vj>的最早开始时间e(事件i的最早发生时间)
l = vl[j] - p->info; // 获取活动<vi, vj>的最晚开始时间l(事件j的最迟发生时间 - i-j权值)
if(e == l) { // 若<vi, vj>是关键活动:
cout << G.vertices[i].data << G.vertices[j].data; // 输出<vi, vj>
}
p = p->nextarc; // 指针p移动到下一个边结点
}
}
}
5.4 案例分析与实现
5.4.1 六度空间理论
/* 引入辅助的数据结构 */
typedef struct {
QElemType *base;
int front;
int rear;
} SqQueue; // 构造队列SqQueue
bool visited[MVNum]; // 存储顶点访问标记
/* 邻接表存储无向图G,通过广度优先搜索遍历G来验证六度空间理论 */
void SixDegree_BFS(ALGraph G, int start) { // 指定start为起始点
Visit_Num = 0; // 记录路径长度在7以内的顶点个数(初值为0)
visited[start] = true; // 标记第start个顶点为已访问
InitQueue(Q); // 初始化队列Q
EnQueue(Q, start); // 将顶点start入队
level[0] = 1; // 记录第一步入队的顶点数为1(从start开始走)
for(len=1; len<=6 && !QueueEmpty(Q); len++) { // 队列非空时循环6次(统计七步之内能找到的所有顶点数):
for(i=0; i<level[len-1]; i++) { // 按上一步入队的顶点数循环(继续走一步):
DeQueue(Q, u); // 将队头元素出队,存为u
p = G.vertices[u].firstarc; // 指针p指示u链域指向的结点(u的第一个邻接点)
while(p != NULL) { // 当p不为空(顺着边表依次检查):
w = p->adjvex; // 获取邻接点下标w(p的邻接点域)
if(!visited[w]) { // 若w未被访问过:
visited[w] = true; // 标记第w个顶点为已访问
Visit_Num++; // 七步之内找到的顶点个数+1
level[len]++; // 当前这一步找到的顶点个数+1
EnQueue(Q, w); // 将顶点w入队(作为下一步的起点)
}
p = p->nextarc; // 指针p移动到下一个边结点
}
}
cout << (Visit_Num / G.vexnum) * 100; // 每走一步输出一次百分比
}
}
到了这里,关于【学习笔记】数据结构算法文档(类C语言)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!