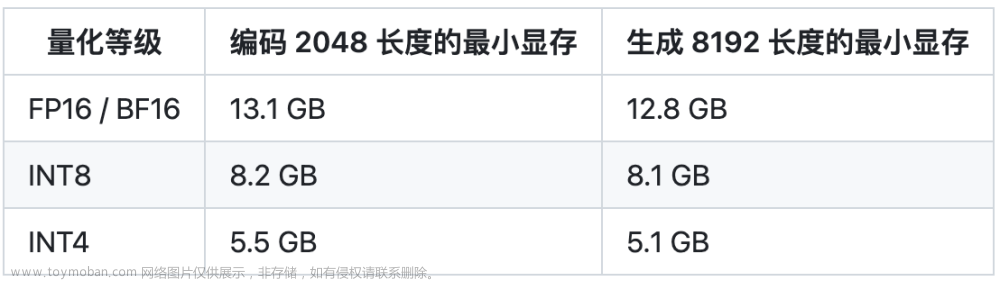
环境部署
申请阿里云GPU服务器:
- CentOS 7.6 64
- Anaconda3-2023.07-1-Linux-x86_64
- Python 3.11.5
- GPU NVIDIA A10(显存24 G/1 core)
- CPU 8 vCore/30G
安装Anaconda、CUDA、PyTorch
参考:ChatGLM2-6B微调实践-P-Tuning方案
Lora微调
项目部署
git clone https://github.com/shuxueslpi/chatGLM-6B-QLoRA.git
cd chatGLM-6B-QLoRA
pip install -r requirements.txt
准备数据集
准备我们自己的数据集,分别生成训练文件和测试文件这两个文件,放在项目data文件夹,数据格式为:
{
"instruction": "类型#裤*版型#宽松*风格#性感*图案#线条*裤型#阔腿裤",
"output": "宽松的阔腿裤这两年真的吸粉不少,明星时尚达人的心头爱。毕竟好穿时尚,谁都能穿出腿长2米的效果宽松的裤腿,当然是遮肉小能手啊。上身随性自然不拘束,面料亲肤舒适贴身体验感棒棒哒。系带部分增加设计看点,还让单品的设计感更强。腿部线条若隐若现的,性感撩人。颜色敲温柔的,与裤子本身所呈现的风格有点反差萌。"
}

训练集文件: train.json
测试集文件: dev.json
修改训练脚本
创建train_qlora.sh,添加以下命令:
python3 train_qlora.py \
--train_args_json chatGLM_6B_QLoRA.json \
--model_name_or_path THUDM/chatglm-6b \
--train_data_path data/train.json \
--eval_data_path data/dev.json \
--lora_rank 4 \
--lora_dropout 0.05 \
--compute_dtype fp32
lora_rank: qlora矩阵的秩。一般设置为8、16、32、64等,在qlora论文中作者设为64。越大则参与训练的参数量越大,一般来说效果会更好,但需要更多显存。
lora_dropout: lora权重的dropout rate。
compute_dtype:量化精度。
修改model_name_or_path参数为本地真实的模型路径。
chatGLM_6B_QLoRA.json文件为所有transformers框架支持的TrainingArguments,参考:https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments
chatGLM_6B_QLoRA.json默认配置如下,可根据实际情况自行修改:
{
"output_dir": "saved_files/chatGLM_6B_QLoRA_t32",
"per_device_train_batch_size": 4,
"gradient_accumulation_steps": 8,
"per_device_eval_batch_size": 4,
"learning_rate": 1e-3,
"num_train_epochs": 1.0,
"lr_scheduler_type": "linear",
"warmup_ratio": 0.1,
"logging_steps": 100,
"save_strategy": "steps",
"save_steps": 500,
"evaluation_strategy": "steps",
"eval_steps": 500,
"optim": "adamw_torch",
"fp16": false,
"remove_unused_columns": false,
"ddp_find_unused_parameters": false,
"seed": 42
}
各参数说明:
per_device_train_batch_size:每个训练设备上的批量大小。
per_device_eval_batch_size:每个评估设备上的批量大小。
gradient_accumulation_steps:梯度累积步骤,用于更大的批次训练。
learning_rate:初始学习率,一般为1e-4、2e-4。
num_train_epochs:训练的轮数(epochs),如果数据量足够大,一般建议只训一个epoch。
lr_scheduler_type: 选择什么类型的学习率调度器来更新模型的学习率
warmup_ratio: 线性预热从0达到learning_rate时,每步学习率的增长率
logging_steps:定义多少个更新步骤打印一次训练日志。
save_strategy:训练过程中,checkpoint的保存策略,可选值有"steps"(每隔一定步骤保存)和"epoch"(每个epoch保存一次)。
save_steps:定义多少个更新步骤保存一次模型。
evaluation_strategy:评估策略,可选值有"steps"(每隔一定步骤评估)和"epoch"(每个epoch评估一次)。
save_steps:定义多少个更新步骤评估一次模型。
optim: 可以使用的优化器
fp16: 是否使用bf16 16位精度训练替代32位训练
remove_unused_columns: 是否自动删除模型forward方法不使用的列
seed:训练开始时设置的随机种子文章来源:https://www.toymoban.com/news/detail-727297.html
执行脚本训练,训练过程如下:文章来源地址https://www.toymoban.com/news/detail-727297.html
(base) [root@iZbp178u8rw9n9ko94ubbyZ chatGLM-6B-QLoRA-main]# sh train_qlora.sh
===================================BUG REPORT===================================
Welcome to bitsandbytes. For bug reports, please run
python -m bitsandbytes
and submit this information together with your error trace to: https://github.com/TimDettmers/bitsandbytes/issues
================================================================================
bin /root/anaconda3/lib/python3.11/site-packages/bitsandbytes/libbitsandbytes_cuda118.so
CUDA SETUP: CUDA runtime path found: /root/anaconda3/lib/libcudart.so.11.0
CUDA SETUP: Highest compute capability among GPUs detected: 8.6
CUDA SETUP: Detected CUDA version 118
CUDA SETUP: Loading binary /root/anaconda3/lib/python3.11/site-packages/bitsandbytes/libbitsandbytes_cuda118.so...
The model weights are not tied. Please use the `tie_weights` method before using the `infer_auto_device` function.
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:07<00:00, 1.13s/it]
trainable params: 974,848 || all params: 3,389,286,400 || trainable%: 0.0287626327477076
Found cached dataset json (/root/.cache/huggingface/datasets/json/default-a26442a3257bd6e5/0.0.0/e347ab1c932092252e717ff3f949105a4dd28b27e842dd53157d2f72e276c2e4)
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 920.81it/s]
Loading cached processed dataset at /root/.cache/huggingface/datasets/json/default-a26442a3257bd6e5/0.0.0/e347ab1c932092252e717ff3f949105a4dd28b27e842dd53157d2f72e276c2e4/cache-a6ee5e96ac795161.arrow
Loading cached shuffled indices for dataset at /root/.cache/huggingface/datasets/json/default-a26442a3257bd6e5/0.0.0/e347ab1c932092252e717ff3f949105a4dd28b27e842dd53157d2f72e276c2e4/cache-20df68b061e7d292.arrow
Loading cached processed dataset at /root/.cache/huggingface/datasets/json/default-a26442a3257bd6e5/0.0.0/e347ab1c932092252e717ff3f949105a4dd28b27e842dd53157d2f72e276c2e4/cache-e9ff6a88c507a91d.arrow
Found cached dataset json (/root/.cache/huggingface/datasets/json/default-f82d1afe86c1e9ec/0.0.0/e347ab1c932092252e717ff3f949105a4dd28b27e842dd53157d2f72e276c2e4)
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 1191.56it/s]
Loading cached processed dataset at /root/.cache/huggingface/datasets/json/default-f82d1afe86c1e9ec/0.0.0/e347ab1c932092252e717ff3f949105a4dd28b27e842dd53157d2f72e276c2e4/cache-baa6cdf34a027bbb.arrow
Loading cached shuffled indices for dataset at /root/.cache/huggingface/datasets/json/default-f82d1afe86c1e9ec/0.0.0/e347ab1c932092252e717ff3f949105a4dd28b27e842dd53157d2f72e276c2e4/cache-8aa40269a670f4fd.arrow
Loading cached processed dataset at /root/.cache/huggingface/datasets/json/default-f82d1afe86c1e9ec/0.0.0/e347ab1c932092252e717ff3f949105a4dd28b27e842dd53157d2f72e276c2e4/cache-dd26c6462b17896e.arrow
wandb: Tracking run with wandb version 0.15.3
wandb: W&B syncing is set to `offline` in this directory.
wandb: Run `wandb online` or set WANDB_MODE=online to enable cloud syncing.
0%| | 0/160 [00:00<?, ?it/s]`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...
/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{
'loss': 1.9799, 'learning_rate': 6.25e-05, 'epoch': 0.12}
{
'loss': 2.8439, 'learning_rate': 0.000125, 'epoch': 0.24}
{
'loss': 2.6293, 'learning_rate': 0.0001875, 'epoch': 0.35}
{
'loss': 2.6095, 'learning_rate': 0.00025, 'epoch': 0.47}
{
'loss': 2.2325, 'learning_rate': 0.0003125, 'epoch': 0.59}
{
'eval_loss': 2.7306337356567383, 'eval_runtime': 0.1659, 'eval_samples_per_second': 12.057, 'eval_steps_per_second': 12.057, 'epoch': 0.59}
3%|█████▉ | 5/160 [00:04<01:36, 1.60it/s/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{
'loss': 2.4916, 'learning_rate': 0.000375, 'epoch': 0.71}
{
'loss': 2.4591, 'learning_rate': 0.0004375, 'epoch': 0.82}
{
'loss': 2.0441, 'learning_rate': 0.0005, 'epoch': 0.94}
{
'loss': 1.8674, 'learning_rate': 0.0005625000000000001, 'epoch': 1.06}
{
'loss': 1.5093, 'learning_rate': 0.000625, 'epoch': 1.18}
{
'eval_loss': 1.626299262046814, 'eval_runtime': 0.1665, 'eval_samples_per_second': 12.013, 'eval_steps_per_second': 12.013, 'epoch': 1.18}
6%|███████████▉ | 10/160 [00:06<01:23, 1.80it/s/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{
'loss': 1.7075, 'learning_rate': 0.0006875, 'epoch': 1.29}
{
'loss': 1.6792, 'learning_rate': 0.00075, 'epoch': 1.41}
{
'loss': 1.4942, 'learning_rate': 0.0008125000000000001, 'epoch': 1.53}
{
'loss': 1.8202, 'learning_rate': 0.000875, 'epoch': 1.65}
{
'loss': 0.9729, 'learning_rate': 0.0009375, 'epoch': 1.76}
{
'eval_loss': 0.7719208002090454, 'eval_runtime': 0.1673, 'eval_samples_per_second': 11.953, 'eval_steps_per_second': 11.953, 'epoch': 1.76}
9%|█████████████████▊ | 15/160 [00:09<01:20, 1.81it/s/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{
'loss': 1.3478, 'learning_rate': 0.001, 'epoch': 1.88}
{
'loss': 1.3449, 'learning_rate': 0.0009930555555555556, 'epoch': 2.0}
{
'loss': 0.6173, 'learning_rate': 0.0009861111111111112, 'epoch': 2.12}
{
'loss': 0.5325, 'learning_rate': 0.0009791666666666666, 'epoch': 2.24}
{
'loss': 1.1995, 'learning_rate': 0.0009722222222222222, 'epoch': 2.35}
{
'eval_loss': 0.06268511712551117, 'eval_runtime': 0.1694, 'eval_samples_per_second': 11.804, 'eval_steps_per_second': 11.804, 'epoch': 2.35}
12%|███████████████████████▊ | 20/160 [00:12<01:17, 1.81it/s/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{
'loss': 1.0089, 'learning_rate': 0.0009652777777777778, 'epoch': 2.47}
{
'loss': 0.9793, 'learning_rate': 0.0009583333333333334, 'epoch': 2.59}
{
'loss': 0.814, 'learning_rate': 0.0009513888888888889, 'epoch': 2.71}
{
'loss': 1.1905, 'learning_rate': 0.0009444444444444445, 'epoch'到了这里,关于ChatGLM2-6B微调实践-QLora方案的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!