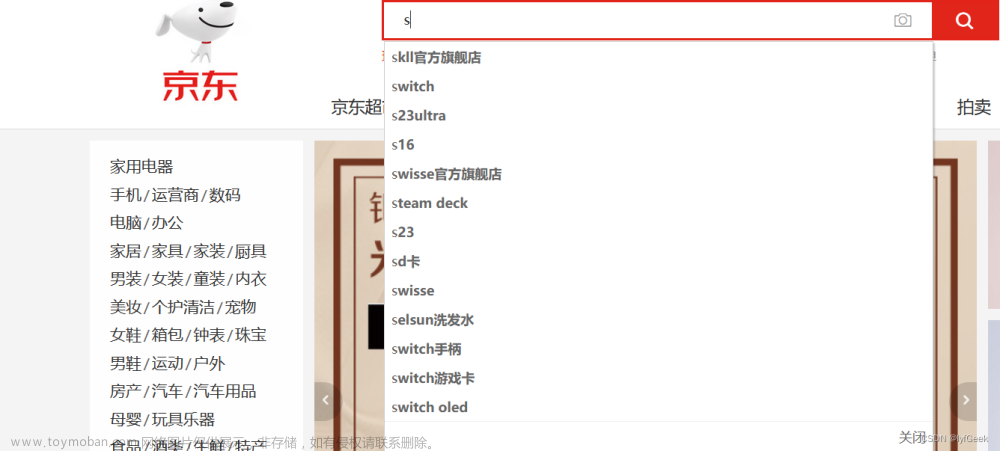
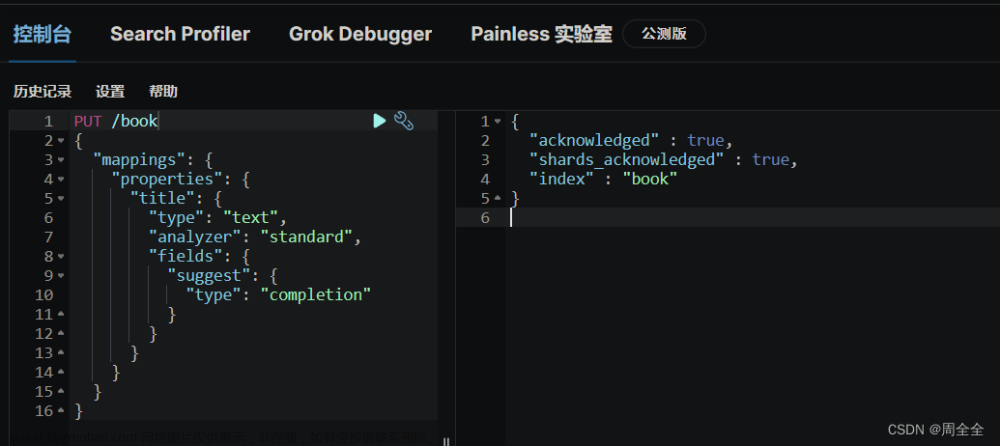
需求:
- 中文搜索、英文搜索、中英混搜
- 全拼搜索、首字母搜索、中文+全拼、中文+首字母混搜
- 简繁搜索
- 二级搜索(对第一次搜索结果,再进行搜索)
一、ES相关插件
IK分词:
GitHub - medcl/elasticsearch-analysis-ik: The IK Analysis plugin integrates Lucene IK analyzer into elasticsearch, support customized dictionary.
拼音:
https://github.com/medcl/elasticsearch-analysis-pinyin
简繁体:
ehttps://github.com/medcl/elasticsearch-analysis-stconvert
二、什么是 analysis
analysis分析是 Elasticsearch 在文档发送之前对文档正文执行的过程,以添加到反向索引中(inverted index)。 在将文档添加到索引之前,Elasticsearch 会为每个分析的字段执行许多步骤:
- Character filtering (字符过滤器): 使用字符过滤器转换字符
- Breaking text into tokens (把文字转化为标记): 将文本分成一组一个或多个标记
- Token filtering:使用标记过滤器转换每个标记
- Token indexing:把这些标记存于索引中
详细介绍:Elasticsearch: analyzer_Elastic 中国社区官方博客的博客-CSDN博客_elasticsearch analyzer如果大家之前看过我写的文章“开始使用Elasticsearch (3)”,在文章的最后部分写了有关于analyzer的有关介绍。在今天的文章中,我们来进一步了解analyzer。 analyzer执行将输入字符流分解为token的过程,它一般发生在两个场合:在indexing的时候,也即在建立索引的时候在searching的时候,也即在搜索时,分析需要搜索的词语什么是analysis...https://blog.csdn.net/UbuntuTouch/article/details/100392478
三、索引模板
PUT /_template/test_template
{
"index_patterns": [
"test-*"
],
"aliases": {
"test_read": {}
},
"settings": {
"index": {
"max_result_window": "100000",
"refresh_interval": "5s",
"number_of_shards": "5",
"translog": {
"flush_threshold_size": "1024mb",
"sync_interval": "30s",
"durability": "async"
},
"number_of_replicas": "1"
},
"analysis": {
"char_filter": {
"tsconvert": {
"type": "stconvert",
"convert_type": "t2s"
}
},
"analyzer": {
"ik_t2s_pinyin_analyzer": {
"type": "custom",
"char_filter": [
"tsconvert"
],
"tokenizer": "ik_max_word",
"filter": [
"pinyin_filter",
"lowercase"
]
},
"stand_t2s_pinyin_analyzer": {
"type": "custom",
"char_filter": [
"tsconvert"
],
"tokenizer": "standard",
"filter": [
"pinyin_filter",
"lowercase"
]
},
"ik_t2s_analyzer": {
"type": "custom",
"char_filter": [
"tsconvert"
],
"tokenizer": "ik_max_word",
"filter": [
"lowercase"
]
},
"stand_t2s_analyzer": {
"type": "custom",
"char_filter": [
"tsconvert"
],
"tokenizer": "standard",
"filter": [
"lowercase"
]
},
"ik_pinyin_analyzer": {
"type": "custom",
"tokenizer": "ik_max_word",
"filter": [
"pinyin_filter",
"lowercase"
]
},
"stand_pinyin_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"pinyin_filter",
"lowercase"
]
},
"keyword_t2s_pinyin_analyzer": {
"filter": [
"pinyin_filter",
"lowercase"
],
"char_filter": [
"tsconvert"
],
"type": "custom",
"tokenizer": "keyword"
},
"keyword_pinyin_analyzer": {
"filter": [
"pinyin_filter",
"lowercase"
],
"type": "custom",
"tokenizer": "keyword"
}
},
"filter": {
"pinyin_first_letter_and_full_pinyin_filter": {
"type": "pinyin",
"keep_first_letter": true,
"keep_separate_first_letter": false,
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_none_chinese": true,
"none_chinese_pinyin_tokenize": false,
"keep_none_chinese_in_joined_full_pinyin": true,
"keep_original": false,
"limit_first_letter_length": 1000,
"lowercase": true,
"trim_whitespace": true,
"remove_duplicated_term": true
}
}
}
},
"mappings": {
"properties": {
"name": {
"index_phrases": true,
"analyzer": "ik_max_word",
"index": true,
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
},
"stand": {
"analyzer": "standard",
"type": "text"
},
"STPA": {
"type": "text",
"analyzer": "stand_t2s_pinyin_analyzer"
},
"ITPA": {
"type": "text",
"analyzer": "ik_t2s_pinyin_analyzer"
}
}
},
"desc": {
"index_phrases": true,
"analyzer": "ik_max_word",
"index": true,
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
},
"stand": {
"analyzer": "standard",
"type": "text"
},
"STPA": {
"type": "text",
"analyzer": "stand_t2s_pinyin_analyzer"
},
"ITPA": {
"type": "text",
"analyzer": "ik_t2s_pinyin_analyzer"
}
}
},
"abstr": {
"index_phrases": true,
"analyzer": "ik_max_word",
"index": true,
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
},
"stand": {
"analyzer": "standard",
"type": "text"
},
"STPA": {
"type": "text",
"analyzer": "stand_t2s_pinyin_analyzer"
},
"ITPA": {
"type": "text",
"analyzer": "ik_t2s_pinyin_analyzer"
}
}
}
}
}
}四、DSL语句
GET /test_read/_search
{
"from": 0,
"size": 10,
"terminate_after": 100000,
"query": {
"bool": {
"must": [
{
"query_string": {
"query": "bj天安门 OR 测试",
"fields": [
"name.ITPA"
],
"type": "phrase",
"default_operator": "and"
}
}
],
"adjust_pure_negative": true,
"boost": 1
}
},
"post_filter": {
"bool": {
"must": [
{
"match": {
"name": "天安门"
}
}
]
}
},
"highlight": {
"fragment_size": 1000,
"pre_tags": [
"<span style=\"color:red;background:yellow;\">"
],
"post_tags": [
"</span>"
],
"fields": {
"name.stand": {},
"desc.stand": {},
"abstr.stand": {},
"name.IPA": {},
"desc.IPA": {},
"abstr.IPA": {},
"name.ITPA": {},
"desc.ITPA": {},
"abstr.ITPA": {}
}
}
}post_filter:后过滤器 | Elasticsearch: 权威指南 | Elastic
PS:post_filter实现二次搜索功能,post_filter无法使用es高亮功能,需要自己通过代码进行手动标记高亮;根据上面的DSL语句,可写出对应的代码啦~文章来源:https://www.toymoban.com/news/detail-728105.html
拼音插件配置:文章来源地址https://www.toymoban.com/news/detail-728105.html
- keep_first_letter:这个参数会将词的第一个字母全部拼起来.例如:刘德华->ldh.默认为:true
- keep_separate_first_letter:这个会将第一个字母一个个分开.例如:刘德华->l,d,h.默认为:flase.如果开启,可能导致查询结果太过于模糊,准确率太低.
- limit_first_letter_length:设置最大keep_first_letter结果的长度,默认为:16
- keep_full_pinyin:如果打开,它将保存词的全拼,并按字分开保存.例如:刘德华> [liu,de,hua],默认为:true
- keep_joined_full_pinyin:如果打开将保存词的全拼.例如:刘德华> [liudehua],默认为:false
- keep_none_chinese:将非中文字母或数字保留在结果中.默认为:true
- keep_none_chinese_together:保证非中文在一起.默认为: true, 例如: DJ音乐家 -> DJ,yin,yue,jia, 如果设置为:false, 例如: DJ音乐家 -> D,J,yin,yue,jia, 注意: keep_none_chinese应该先开启.
- keep_none_chinese_in_first_letter:将非中文字母保留在首字母中.例如: 刘德华AT2016->ldhat2016, 默认为:true
- keep_none_chinese_in_joined_full_pinyin:将非中文字母保留为完整拼音. 例如: 刘德华2016->liudehua2016, 默认为: false
- none_chinese_pinyin_tokenize:如果他们是拼音,切分非中文成单独的拼音项. 默认为:true,例如: liudehuaalibaba13zhuanghan -> liu,de,hua,a,li,ba,ba,13,zhuang,han, 注意: keep_none_chinese和keep_none_chinese_together需要先开启.
- keep_original:是否保持原词.默认为:false
- lowercase:小写非中文字母.默认为:true
- trim_whitespace:去掉空格.默认为:true
- remove_duplicated_term:保存索引时删除重复的词语.例如: de的>de, 默认为: false, 注意:开启可能会影响位置相关的查询.
- ignore_pinyin_offset:在6.0之后,严格限制偏移量,不允许使用重叠的标记.使用此参数时,忽略偏移量将允许使用重叠的标记.请注意,所有与位置相关的查询或突出显示都将变为错误,您应使用多个字段并为不同的字段指定不同的设置查询目的.如果需要偏移量,请将其设置为false。默认值:true
到了这里,关于Elasticsearch-高级搜索(拼音|首字母|简繁|二级搜索)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!