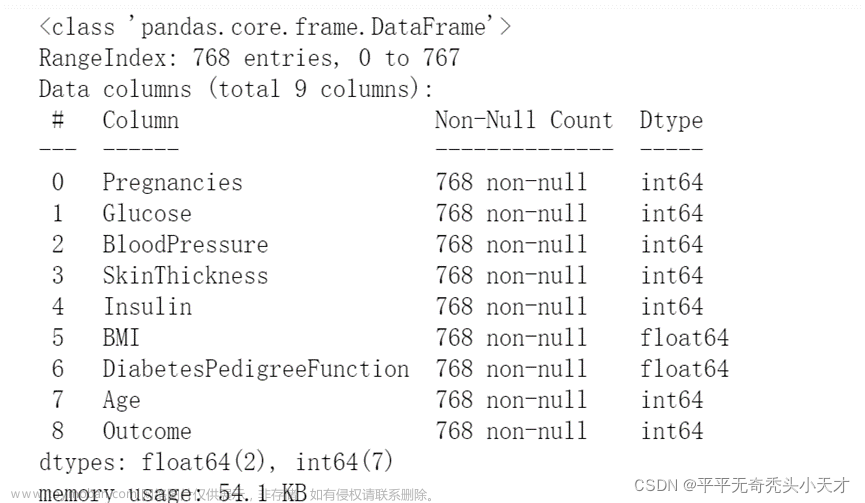
Quiz 1
Answer Problems 1-2 based on the following training set, where A , B , C A, B, C A,B,C are describing attributes, and D D D is the class attribute:
| A A A | B B B | C C C | D D D |
|---|---|---|---|
| 1 | 1 | 1 | y \mathrm{y} y |
| 1 | 0 | 1 | y \mathrm{y} y |
| 0 | 1 | 1 | y \mathrm{y} y |
| 1 | 1 | 0 | y \mathrm{y} y |
| 0 | 1 | 1 | n \mathrm{n} n |
| 1 | 1 | 1 | n \mathrm{n} n |
| 0 | 0 | 0 | n \mathrm{n} n |
| 0 | 1 | 0 | n \mathrm{n} n |
Problem 1 (20%). Describe an (arbitrary) decision tree that correctly classifies 6 of the 8 records in the training set. Furthermore, based on your decision tree, what is the predicted class for a record with A = 1 , B = 0 , C = 0 A=1, B=0, C=0 A=1,B=0,C=0 ?

Problem 2 (40%). Suppose that we apply Bayesian classification with the following conditional independence assumption: conditioned on a value of
C
C
C and a value of
D
D
D, attributes
A
A
A and
B
B
B are independent. What is the predicted class for a record with
A
=
1
,
B
=
1
,
C
=
1
A=1, B=1, C=1
A=1,B=1,C=1 ? You must show the details of your reasoning.
Pr
[
D
∣
A
,
B
,
C
]
=
Pr
[
A
,
B
,
C
∣
D
]
⋅
Pr
[
D
]
Pr
[
A
,
B
,
C
]
=
Pr
[
a
,
b
∣
c
,
d
]
⋅
Pr
[
c
∣
d
]
⋅
Pr
[
D
]
Pr
[
A
,
B
,
C
]
=
Pr
[
A
∣
C
,
D
]
⋅
Pr
[
B
∣
C
,
D
]
⋅
Pr
[
C
∣
D
]
⋅
Pr
[
D
]
Pr
[
A
,
B
,
C
]
Pr
[
A
=
1
,
B
=
1
,
C
=
1
]
⋅
Pr
[
D
=
y
∣
A
=
1
,
B
=
1
,
C
=
1
]
=
Pr
[
A
=
1
∣
C
=
1
,
D
=
y
]
⋅
Pr
[
B
=
1
∣
C
=
1
,
D
=
y
]
⋅
Pr
[
C
=
1
∣
D
=
y
]
⋅
Pr
[
D
=
y
]
=
2
3
⋅
2
3
⋅
3
4
⋅
1
2
=
1
6
Pr
[
A
=
1
,
B
=
1
,
C
=
1
]
⋅
Pr
[
D
=
n
∣
A
=
1
,
B
=
1
,
C
=
1
]
=
Pr
[
A
=
1
∣
C
=
1
,
D
=
n
]
⋅
Pr
[
B
=
1
∣
C
=
1
,
D
=
n
]
⋅
Pr
[
C
=
1
∣
D
=
n
]
⋅
Pr
[
D
=
n
]
=
1
2
⋅
1
⋅
1
2
⋅
1
2
=
1
8
The predicted class for a record with
A
=
1
,
B
=
1
,
C
=
1
is
D
=
y
\begin{aligned} & \operatorname{Pr}[D \mid A, B, C]=\frac{\operatorname{Pr}[A, B, C \mid D] \cdot \operatorname{Pr}[D]}{\operatorname{Pr}[A, B, C]} \\ & =\frac{\operatorname{Pr}[a, b \mid c, d] \cdot \operatorname{Pr}[c \mid d] \cdot \operatorname{Pr}[D]}{\operatorname{Pr}[A, B, C]} \\ & =\frac{\operatorname{Pr}[A \mid C, D] \cdot \operatorname{Pr}[B \mid C, D] \cdot \operatorname{Pr}[C \mid D] \cdot \operatorname{Pr}[D]}{\operatorname{Pr}[A, B, C]} \\ & \operatorname{Pr}[A=1, B=1, C=1] \cdot \operatorname{Pr}[D=y \mid A=1, B=1, C=1] \\ &=\operatorname{Pr}[A=1 \mid C=1, D=y] \cdot \operatorname{Pr}[B=1 \mid C=1, D=y] \cdot \operatorname{Pr}[C=1 \mid D=y] \cdot \operatorname{Pr}[D=y] \\ &=\frac{2}{3} \cdot \frac{2}{3} \cdot \frac{3}{4} \cdot \frac{1}{2}=\frac{1}{6} \\ & \operatorname{Pr}[A=1, B=1, C=1] \cdot \operatorname{Pr}[D=n \mid A=1, B=1, C=1]\\ & = \operatorname{Pr}[A=1 \mid C=1, D=n] \cdot \operatorname{Pr}[B=1 \mid C=1, D=n] \cdot \operatorname{Pr}[C=1 \mid D=n] \cdot \operatorname{Pr}[D=n] \\ & =\frac{1}{2} \cdot 1 \cdot \frac{1}{2} \cdot \frac{1}{2}=\frac{1}{8} \\ & \text { The predicted class for a record with } A=1, B=1, C=1 \text { is } D=y \end{aligned}
Pr[D∣A,B,C]=Pr[A,B,C]Pr[A,B,C∣D]⋅Pr[D]=Pr[A,B,C]Pr[a,b∣c,d]⋅Pr[c∣d]⋅Pr[D]=Pr[A,B,C]Pr[A∣C,D]⋅Pr[B∣C,D]⋅Pr[C∣D]⋅Pr[D]Pr[A=1,B=1,C=1]⋅Pr[D=y∣A=1,B=1,C=1]=Pr[A=1∣C=1,D=y]⋅Pr[B=1∣C=1,D=y]⋅Pr[C=1∣D=y]⋅Pr[D=y]=32⋅32⋅43⋅21=61Pr[A=1,B=1,C=1]⋅Pr[D=n∣A=1,B=1,C=1]=Pr[A=1∣C=1,D=n]⋅Pr[B=1∣C=1,D=n]⋅Pr[C=1∣D=n]⋅Pr[D=n]=21⋅1⋅21⋅21=81 The predicted class for a record with A=1,B=1,C=1 is D=y
Problem 3 (40%). The following figure shows a training set of 5 points. Use the Perceptron algorithm to find a plane that (i) crosses the origin, and (ii) separates the black points from the white ones. Recall that this algorithm starts with a vector c ⃗ = 0 → \vec{c}=\overrightarrow{0} c=0 and iteratively adjusts it using a point from the training set. You need to show the value of c ⃗ \vec{c} c after every adjustment.

round c ⃗ p ⃗ 1 ( 0 , 0 ) A ( 0.2 ) 2 ( 0 , 2 ) C ( 2 , 0 ) 3 ( 2 , 2 ) \begin{array}{ccc}\text { round } & \vec{c} & \vec{p} \\ 1 & (0,0) & A(0.2) \\ 2 & (0,2) & C(2,0) \\ 3 & (2,2) & \end{array} round 123c(0,0)(0,2)(2,2)pA(0.2)C(2,0)
Quiz 2
Problem 1 (30%). The figure below shows the boundary lines of 5 half-planes. Find the point with the smallest y \boldsymbol{y} y-coordinate in the intersection of these half-planes with the linear programming algorithm that we discussed in the class. Assume the algorithm (randomly) permutes the boundary lines into ℓ 1 , ℓ 2 , … , ℓ 5 \ell_{1}, \ell_{2}, \ldots, \ell_{5} ℓ1,ℓ2,…,ℓ5 and processes them in the same order. Starting from the second round, give the point maintained by the algorithm at the end of each round.

Answer: Let H 1 , … , H 5 H_{1}, \ldots, H_{5} H1,…,H5 be the half-planes whose boundary lines are ℓ 1 , … , ℓ 5 \ell_{1}, \ldots, \ell_{5} ℓ1,…,ℓ5, respectively. Let p p p be the point maintained by the algorithm. At the end of the second round, p p p is the intersection A A A of ℓ 1 \ell_{1} ℓ1 and ℓ 2 \ell_{2} ℓ2. At Round 3 , because p = A p=A p=A does not fall in H 3 H_{3} H3, the algorithm computes a new p p p as the lowest point on ℓ 3 \ell_{3} ℓ3 that satisfies all of H 1 , … , H 3 H_{1}, \ldots, H_{3} H1,…,H3. As a result, p p p is set to B B B. At Round 4 , because p = B p=B p=B does not fall in H 4 H_{4} H4, the algorithm computes a new p p p as the lowest point on ℓ 4 \ell_{4} ℓ4 that satisfies all of H 1 , … , H 4 H_{1}, \ldots, H_{4} H1,…,H4. As a result, p p p is set to C C C. Finally, the last round processes H 5 H_{5} H5. As p = B p=B p=B falls in H 5 H_{5} H5, the algorithm finishes with C C C as the final answer.

Problem 2 (30%). Consider a set P P P of red points A ( 2 , 1 ) , B ( 2 , − 2 ) A(2,1), B(2,-2) A(2,1),B(2,−2) and blue points C ( − 2 , 1 ) C(-2,1) C(−2,1), D ( − 2 , − 3 ) D(-2,-3) D(−2,−3). Give an instance of quadratic programming for finding a separation line with the maximum margin.
Answer: Minimize w 1 2 + w 2 2 w_{1}^{2}+w_{2}^{2} w12+w22 subject to the following constraints:
2 w 1 + w 2 ≥ 1 2 w 1 − 2 w 2 ≥ 1 − 2 w 1 + w 2 ≤ − 1 − 2 w 1 − 3 w 2 ≤ − 1 \begin{aligned} 2 w_{1}+w_{2} & \geq 1 \\ 2 w 1-2 w_{2} & \geq 1 \\ -2 w_{1}+w_{2} & \leq-1 \\ -2 w 1-3 w_{2} & \leq-1 \end{aligned} 2w1+w22w1−2w2−2w1+w2−2w1−3w2≥1≥1≤−1≤−1
Problem 3 (40%). Let P P P be a set of points as shown in the figure below. Assume k = 3 k=3 k=3, and that the distance metric is Euclidian distance.

Run the k k k-center algorithm we discussed in the class on P P P. If the first center is (randomly) chosen as point a a a, what are the second and third centers?
Answer: The second center is h h h, and the third is d d d.
Quiz 3
Problem 1 (30%). Consider the dataset as shown in the figure below. What is the covariance matrix of the dataset?

Answer: Let
A
=
[
σ
x
x
σ
x
y
σ
y
x
σ
y
y
]
A=\left[\begin{array}{ll}\sigma_{x x} & \sigma_{x y} \\ \sigma_{y x} & \sigma_{y y}\end{array}\right]
A=[σxxσyxσxyσyy] be the covariance matrix, where
σ
x
x
(
σ
y
y
)
\sigma_{x x}\left(\sigma_{y y}\right)
σxx(σyy) is the variance along the
x
−
(
y
−
)
\mathrm{x}-(\mathrm{y}-)
x−(y−) dimension, and
σ
x
y
(
=
σ
y
x
)
\sigma_{x y}\left(=\sigma_{y x}\right)
σxy(=σyx) is the covariance of the
x
\mathrm{x}
x - and y-dimensions. Since the means along both the
x
\mathrm{x}
x - and
y
\mathrm{y}
y-dimensions are 0 , we have that:
σ
x
x
=
1
4
(
(
−
3
)
2
+
(
−
2
)
2
+
1
2
+
4
2
)
=
30
/
4
=
7.5
σ
y
y
=
1
4
(
4
2
+
1
2
+
(
−
2
)
2
+
(
−
3
)
2
)
=
30
/
4
=
7.5
σ
x
y
=
1
4
(
(
−
3
)
×
4
+
(
−
2
)
×
1
+
1
×
(
−
2
)
+
4
×
(
−
3
)
)
=
−
28
/
4
=
−
7
\begin{aligned} \sigma_{x x} & =\frac{1}{4}\left((-3)^{2}+(-2)^{2}+1^{2}+4^{2}\right)=30 / 4=7.5 \\ \sigma_{y y} & =\frac{1}{4}\left(4^{2}+1^{2}+(-2)^{2}+(-3)^{2}\right)=30 / 4=7.5 \\ \sigma_{x y} & =\frac{1}{4}((-3) \times 4+(-2) \times 1+1 \times(-2)+4 \times(-3))=-28 / 4=-7 \end{aligned}
σxxσyyσxy=41((−3)2+(−2)2+12+42)=30/4=7.5=41(42+12+(−2)2+(−3)2)=30/4=7.5=41((−3)×4+(−2)×1+1×(−2)+4×(−3))=−28/4=−7
Therefore, A = [ 7.5 − 7 − 7 7.5 ] A=\left[\begin{array}{rr}7.5 & -7 \\ -7 & 7.5\end{array}\right] A=[7.5−7−77.5].
Problem 2 (30%). Use PCA to find the line passing the origin on which the projections of the points in Problem 1 have the greatest variance.
Answer: Let
λ
\lambda
λ be an eigenvalue of
A
A
A, which implies that the determinant of
[
7.5
−
λ
−
7
−
7
7.5
−
λ
]
\left[\begin{array}{cc}7.5-\lambda & -7 \\ -7 & 7.5-\lambda\end{array}\right]
[7.5−λ−7−77.5−λ] is 0 . By expanding the determinant, we get the following equation:
(
7.5
−
λ
)
2
−
49
=
0.
(7.5-\lambda)^{2}-49=0 .
(7.5−λ)2−49=0.
It follows that λ 1 = 14.5 \lambda_{1}=14.5 λ1=14.5 and λ 2 = 0.5 \lambda_{2}=0.5 λ2=0.5 are the eigenvalues of A A A, where λ 1 \lambda_{1} λ1 is the larger one.
Let v ⃗ = [ x y ] \vec{v}=\left[\begin{array}{l}x \\ y\end{array}\right] v=[xy] be an eigenvector corresponding to λ 1 \lambda_{1} λ1, which satisfies that
[ 7.5 − 7 − 7 7.5 ] [ x y ] = [ 14.5 x 14.5 y ] \left[\begin{array}{ll} 7.5 & -7 \\ -7 & 7.5 \end{array}\right]\left[\begin{array}{l} x \\ y \end{array}\right]=\left[\begin{array}{l} 14.5 x \\ 14.5 y \end{array}\right] [7.5−7−77.5][xy]=[14.5x14.5y]
Note that the above equation is satisfied by any pair of x x x and y y y satisfying x + y = 0 x+y=0 x+y=0. As the line chosen by PCA has the same direction as v ⃗ \vec{v} v, the line is x + y = 0 x+y=0 x+y=0.
Problem 3 (40%). Run DBSCAN on the set of points shown in the figure below with ϵ = 1 \epsilon=1 ϵ=1 and minpts = 4 =4 =4. What are the core points and the clusters?
 文章来源:https://www.toymoban.com/news/detail-728337.html
文章来源:https://www.toymoban.com/news/detail-728337.html
Answer: The core points are b , e , g , j , k b, e, g, j, k b,e,g,j,k and o o o. There are three clusters:文章来源地址https://www.toymoban.com/news/detail-728337.html
- Cluster 1: a , b , c , d , e , f a, b, c, d, e, f a,b,c,d,e,f
- Cluster 2: f , g , h , i , j , k , l f, g, h, i, j, k, l f,g,h,i,j,k,l
- Cluster 3: m , n , o , p , q m, n, o, p, q m,n,o,p,q
到了这里,关于【数据挖掘】2017年 Quiz 1-3 整理 带答案的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!