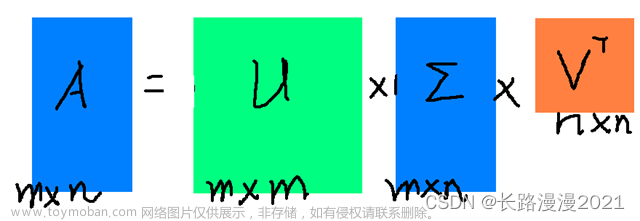
在学习《视觉SLAM十四讲》过程中常遇到SVD奇异值分解,经过一段时间的学习,在此进行记录整理, 本篇主要整理SVD的数学理论基础, 下一篇 进行整理 SVD 实际应用 。
一、线性代数的方阵分解
给定一大小为 m × m m\times m m×m 的矩阵 A A A(方阵),其对角化分解可以写成 A = U Λ U − 1 A=U\Lambda U^{-1} A=UΛU−1
其中, U U U的每一列都是特征向量, Λ \Lambda Λ对角线上的元素是从大到小排列的特征值,若将 U U U记作 U = ( u ⃗ 1 , u ⃗ 2 , . . . , u ⃗ m ) U=(\vec{u}_1,\vec{u}_2,...,\vec{u}_m) U=(u1,u2,...,um),则
A U = A ( u ⃗ 1 , u ⃗ 2 , . . . , u ⃗ m ) = ( λ 1 u ⃗ 1 , λ 2 u ⃗ 2 , . . . , λ m u ⃗ m ) = ( u ⃗ 1 , u ⃗ 2 , . . . , u ⃗ m ) [ λ 1 ⋯ 0 ⋮ ⋱ ⋮ 0 ⋯ λ m ] AU=A(\vec{u}_1,\vec{u}_2,...,\vec{u}_m)=(\lambda_1 \vec{u}_1,\lambda_2 \vec{u}_2,...,\lambda_m \vec{u}_m)=(\vec{u}_1,\vec{u}_2,...,\vec{u}_m)\left[ \begin{array}{ccc} \lambda_1 & \cdots & 0 \\ \vdots & \ddots & \vdots \\ 0 & \cdots & \lambda_m \\ \end{array} \right] AU=A(u1,u2,...,um)=(λ1u1,λ2u2,...,λmum)=(u1,u2,...,um) λ1⋮0⋯⋱⋯0⋮λm
⇒ A U = U Λ ⇒ A = U Λ U − 1 \Rightarrow AU=U\Lambda \Rightarrow A=U\Lambda U^{-1} ⇒AU=UΛ⇒A=UΛU−1
尤其,当矩阵 A A A是一个对称矩阵时,则存在一个对称对角化分解,即 A = Q Λ Q T A=Q\Lambda Q^T A=QΛQT
其中, Q Q Q的每一列都是相互正交的特征向量,且是单位向量, Λ \Lambda Λ对角线上的元素是从大到小排列的特征值。
将矩阵 Q Q Q记作 Q = ( q ⃗ 1 , q ⃗ 2 , . . . , q ⃗ m ) Q=\left(\vec{q}_1,\vec{q}_2,...,\vec{q}_m\right) Q=(q1,q2,...,qm),则矩阵 A A A 可写成如下形式:
A = λ 1 q ⃗ 1 q ⃗ 1 T + λ 2 q ⃗ 2 q ⃗ 2 T + . . . + λ m q ⃗ m q ⃗ m T A=\lambda_1 \vec{q}_1\vec{q}_1^T+\lambda_2 \vec{q}_2\vec{q}_2^T+...+\lambda_m \vec{q}_m\vec{q}_m^T A=λ1q1q1T+λ2q2q2T+...+λmqmqmT
如,给定一大小为
2
×
2
2\times 2
2×2的矩阵
A
=
[
2
1
1
2
]
A=\left[ \begin{array}{cc} 2 & 1 \\ 1 & 2 \\ \end{array} \right]
A=[2112]
根据
∣
λ
I
−
A
∣
=
∣
λ
−
2
−
1
−
1
λ
−
2
∣
=
0
\left|\lambda I-A\right|=\left| \begin{array}{cc} \lambda-2 & -1 \\ -1 & \lambda-2 \\ \end{array} \right|=0
∣λI−A∣=
λ−2−1−1λ−2
=0
求得特征值为 λ 1 = 3 , λ 2 = 1 \lambda_1=3,\lambda_2=1 λ1=3,λ2=1,相应地, q ⃗ 1 = ( 2 2 , 2 2 ) T , q ⃗ 2 = ( − 2 2 , 2 2 ) T \vec{q}_1=\left(\frac{\sqrt{2}}{2}, \frac{\sqrt{2}}{2}\right)^T,\vec{q}_2=\left(-\frac{\sqrt{2}}{2}, \frac{\sqrt{2}}{2}\right)^T q1=(22,22)T,q2=(−22,22)T
则
A
=
λ
1
q
⃗
1
q
⃗
1
T
+
λ
2
q
⃗
2
q
⃗
2
T
=
[
2
1
1
2
]
A=\lambda_1 \vec{q}_1\vec{q}_1^T+\lambda_2 \vec{q}_2\vec{q}_2^T =\left[ \begin{array}{cc} 2 & 1 \\ 1 & 2 \\ \end{array} \right]
A=λ1q1q1T+λ2q2q2T=[2112]
这样,我们就得到了矩阵A的对称对角化分解。
二、奇异值分解定义
对于对称方阵而言,能够进行对称对角化分解,试想:对称对角化分解与奇异值分解有什么本质关系呢?
当给定一个大小为
m
×
n
m\times n
m×n 的矩阵
A
A
A,虽然矩阵
A
A
A不一定是方阵,但大小为
m
×
m
m\times m
m×m的
A
A
T
AA^T
AAT 和
n
×
n
n\times n
n×n的
A
T
A
A^TA
ATA 却是对称矩阵,若
A
A
T
=
P
Λ
1
P
T
AA^T=P\Lambda_1 P^T
AAT=PΛ1PT,
A
T
A
=
Q
Λ
2
Q
T
A^TA=Q\Lambda_2Q^T
ATA=QΛ2QT,则矩阵
A
A
A的奇异值分解为
A
=
P
Σ
Q
T
A=P\Sigma Q^T
A=PΣQT
其中,
- 矩阵 P = ( p ⃗ 1 , p ⃗ 2 , . . . , p ⃗ m ) P=\left(\vec{p}_1,\vec{p}_2,...,\vec{p}_m\right) P=(p1,p2,...,pm) 大小为 m × m m\times m m×m,列向量 p ⃗ 1 , p ⃗ 2 , . . . , p ⃗ m \vec{p}_1,\vec{p}_2,...,\vec{p}_m p1,p2,...,pm 是 A A T AA^T AAT的特征向量,被称为矩阵 A A A的左奇异向量(left singular vector);
- 矩阵 Q = ( q ⃗ 1 , q ⃗ 2 , . . . , q ⃗ n ) Q=\left(\vec{q}_1,\vec{q}_2,...,\vec{q}_n\right) Q=(q1,q2,...,qn) 大小为 n × n n\times n n×n,列向量 q ⃗ 1 , q ⃗ 2 , . . . , q ⃗ n \vec{q}_1,\vec{q}_2,...,\vec{q}_n q1,q2,...,qn 是 A T A A^TA ATA的特征向量,被称为矩阵A的右奇异向量(right singular vector);
- 矩阵 Λ 1 \Lambda_1 Λ1大小为 m × m m\times m m×m,矩阵 Λ 2 \Lambda_2 Λ2大小为 n × n n\times n n×n,两个矩阵对角线上的非零元素相同 (即矩阵 A A T AA^T AAT和矩阵 A T A A^TA ATA的非零特征值相同);
- 矩阵 Σ \Sigma Σ 大小为 m × n m\times n m×n,位于对角线上的元素被称为 奇异值(singular value)。
为什么 A A T = P Λ 1 P T AA^T=P\Lambda_1 P^T AAT=PΛ1PT, A T A = Q Λ 2 Q T A^TA=Q\Lambda_2Q^T ATA=QΛ2QT ,矩阵 A A A的奇异值分解 A = P Σ Q T A=P\Sigma Q^T A=PΣQT?
自己未理解透,自己反推理解如下:
假设 A = P Σ Q T A=P\Sigma Q^T A=PΣQT,则
A A T = P Σ Q T ( P Σ Q T ) T = P Σ Q T ( Q Σ T P T ) = P Σ Σ T P T = P Λ 1 P T AA^T=P\Sigma Q^T(P\Sigma Q^T)^T=P\Sigma Q^T(Q\Sigma^T P^T)=P\Sigma \Sigma^T P^T=P\Lambda_1 P^T AAT=PΣQT(PΣQT)T=PΣQT(QΣTPT)=PΣΣTPT=PΛ1PT ( Q T Q = I Q^TQ=I QTQ=I)
同理,
A T A = ( P Σ Q T ) T P Σ Q T = ( Q Σ T P T ) P Σ Q T = Q Σ T Σ Q T = Q Λ 2 Q T A^TA=(P\Sigma Q^T)^TP\Sigma Q^T=(Q\Sigma^T P^T)P\Sigma Q^T=Q\Sigma^T \Sigma Q^T=Q\Lambda_2 Q^T ATA=(PΣQT)TPΣQT=(QΣTPT)PΣQT=QΣTΣQT=QΛ2QT ( P T P = I P^TP=I PTP=I)
这样理解不知是否正确,还望指正
接下来,我们来看看矩阵
Σ
\Sigma
Σ与矩阵
A
A
T
AA^T
AAT和矩阵
A
T
A
A^TA
ATA的关系。
令常数
k
k
k是矩阵
A
A
A的秩,则
k
⩽
m
i
n
(
m
,
n
)
k\leqslant min(m,n)
k⩽min(m,n),当
m
≠
n
m\ne n
m=n时,矩阵
Λ
1
\Lambda_1
Λ1和矩阵
Λ
2
\Lambda_2
Λ2的大小不同,但矩阵
Λ
1
\Lambda_1
Λ1和矩阵
Λ
2
\Lambda_2
Λ2对角线上的非零元素却是相同的,若矩阵
Λ
1
\Lambda_1
Λ1(或矩阵
Λ
2
\Lambda_2
Λ2)对角线上的非零元素分别为
λ
1
,
λ
2
,
.
.
.
,
λ
k
\lambda_1,\lambda_2,...,\lambda_k
λ1,λ2,...,λk,其中,这些特征值也都是非负的,再令矩阵
Σ
\Sigma
Σ对角线上的非零元素分别为
σ
1
,
σ
2
,
.
.
.
,
σ
k
\sigma_1,\sigma_2,...,\sigma_k
σ1,σ2,...,σk,则
σ
1
=
λ
1
,
σ
2
=
λ
2
,
.
.
.
,
σ
k
=
λ
k
\sigma_1=\sqrt{\lambda_1},\sigma_2=\sqrt{\lambda_2},...,\sigma_k=\sqrt{\lambda_k}
σ1=λ1,σ2=λ2,...,σk=λk
即非零奇异值的平方对应着矩阵 Λ 1 \Lambda_1 Λ1(或矩阵 Λ 2 \Lambda_2 Λ2)的非零特征值,到这里,我们就不难看出奇异值分解与对称对角化分解的关系了,即我们可以由对称对角化分解得到我们想要的奇异值分解。
为便于理解,给定一大小为 2 × 2 2\times 2 2×2的矩阵 A = [ 4 4 − 3 3 ] A=\left[ \begin{array}{cc} 4 & 4 \\ -3 & 3 \\ \end{array} \right] A=[4−343] (该矩阵是方阵但不是对称矩阵)
对
A
A
T
=
[
32
0
0
18
]
AA^T=\left[ \begin{array}{cc} 32 & 0 \\ 0 & 18 \\ \end{array} \right]
AAT=[320018]进行对称对角化分解,
得到特征值为
λ
1
=
32
,
λ
2
=
18
\lambda_1=32,\lambda_2=18
λ1=32,λ2=18,相应地,特征向量为
p
⃗
1
=
(
1
,
0
)
T
\vec{p}_1=\left( 1,0 \right) ^T
p1=(1,0)T,
p
⃗
2
=
(
0
,
1
)
T
\vec{p}_2=\left(0,1\right)^T
p2=(0,1)T;
对
A
T
A
=
[
25
7
7
25
]
A^TA=\left[ \begin{array}{cc} 25 & 7 \\ 7 & 25 \\ \end{array} \right]
ATA=[257725]进行对称对角化分解,得到特征值为
λ
1
=
32
\lambda_1=32
λ1=32,
λ
2
=
18
\lambda_2=18
λ2=18,
相应地,特征向量为
q
⃗
1
=
(
2
2
,
2
2
)
T
\vec{q}_1=\left(\frac{\sqrt{2}}{2},\frac{\sqrt{2}}{2}\right)^T
q1=(22,22)T,
q
⃗
2
=
(
−
2
2
,
2
2
)
T
\vec{q}_2=\left(-\frac{\sqrt{2}}{2}, \frac{\sqrt{2}}{2}\right)^T
q2=(−22,22)T。
取
Σ
=
[
4
2
0
0
3
2
]
\Sigma =\left[ \begin{array}{cc} 4\sqrt{2} & 0 \\ 0 & 3\sqrt{2} \\ \end{array} \right]
Σ=[420032],则矩阵A的奇异值分解为
A
=
P
Σ
Q
T
=
(
p
⃗
1
,
p
⃗
2
)
Σ
(
q
⃗
1
,
q
⃗
2
)
T
=
[
1
0
0
1
]
[
4
2
0
0
3
2
]
[
2
2
2
2
−
2
2
2
2
]
=
[
4
4
−
3
3
]
A=P\Sigma Q^T=\left(\vec{p}_1,\vec{p}_2\right)\Sigma \left(\vec{q}_1,\vec{q}_2\right)^T =\left[ \begin{array}{cc} 1 & 0 \\ 0 & 1 \\ \end{array} \right] \left[ \begin{array}{cc} 4\sqrt{2} & 0 \\ 0 & 3\sqrt{2} \\ \end{array} \right] \left[ \begin{array}{cc} \frac{\sqrt{2}}{2} & \frac{\sqrt{2}}{2} \\ -\frac{\sqrt{2}}{2} & \frac{\sqrt{2}}{2} \\ \end{array} \right] =\left[ \begin{array}{cc} 4 & 4 \\ -3 & 3 \\ \end{array} \right]
A=PΣQT=(p1,p2)Σ(q1,q2)T=[1001][420032][22−222222]=[4−343]
若矩阵
A
A
A不是一方阵,如,给定一大小为
3
×
2
3\times 2
3×2的
A
=
[
1
2
0
0
0
0
]
A=\left[ \begin{array}{cc} 1 & 2 \\ 0 & 0 \\ 0 & 0 \\ \end{array} \right]
A=
100200
由
A
A
T
=
[
5
0
0
0
0
0
0
0
0
]
AA^T=\left[ \begin{array}{ccc} 5 & 0 & 0 \\ 0 & 0 & 0 \\ 0 & 0 & 0 \\ \end{array} \right]
AAT=
500000000
得到
特征值为
λ
1
=
5
,
λ
2
=
λ
3
=
0
\lambda_1=5,\lambda_2=\lambda_3=0
λ1=5,λ2=λ3=0,特征向量为
p
⃗
1
=
(
1
,
0
,
0
)
T
,
p
⃗
2
=
(
0
,
1
,
0
)
T
,
p
⃗
3
=
(
0
,
0
,
1
)
T
\vec{p}_1=\left(1,0,0\right)^T,\vec{p}_2=\left(0,1,0\right)^T,\vec{p}_3=\left(0,0,1\right)^T
p1=(1,0,0)T,p2=(0,1,0)T,p3=(0,0,1)T
由
A
T
A
=
[
1
2
2
4
]
A^TA=\left[ \begin{array}{cc} 1 & 2 \\ 2 & 4 \\ \end{array} \right]
ATA=[1224]得到
特征值为
λ
1
=
5
,
λ
2
=
0
\lambda_1=5,\lambda_2=0
λ1=5,λ2=0,特征向量为
q
⃗
1
=
(
5
5
,
2
5
5
)
T
,
q
⃗
2
=
(
−
2
5
5
,
5
5
)
T
\vec{q}_1=\left(\frac{\sqrt{5}}{5},\frac{2\sqrt{5}}{5}\right)^T,\vec{q}_2=\left(-\frac{2\sqrt{5}}{5},\frac{\sqrt{5}}{5}\right)^T
q1=(55,525)T,q2=(−525,55)T
令 Σ = [ 5 0 0 0 0 0 ] \Sigma=\left[ \begin{array}{cc} \sqrt{5} & 0 \\ 0 & 0 \\ 0 & 0 \\ \end{array} \right] Σ= 500000 (矩阵 Σ \Sigma Σ大小为 3 × 2 3\times 2 3×2)
此时,矩阵
A
A
A的奇异值分解为
A
=
P
Σ
Q
T
=
(
p
⃗
1
,
p
⃗
2
)
Σ
(
q
⃗
1
,
q
⃗
2
)
T
=
[
1
0
0
0
1
0
0
0
1
]
[
5
0
0
0
0
0
]
[
5
5
2
5
5
−
2
5
5
5
5
]
=
[
1
2
0
0
0
0
]
A=P\Sigma Q^T=\left(\vec{p}_1,\vec{p}_2\right)\Sigma \left(\vec{q}_1,\vec{q}_2\right)^T =\left[ \begin{array}{ccc} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \\ \end{array} \right] \left[ \begin{array}{cc} \sqrt{5} & 0 \\ 0 & 0 \\ 0 & 0 \\ \end{array} \right] \left[ \begin{array}{cc} \frac{\sqrt{5}}{5} & \frac{2\sqrt{5}}{5} \\ -\frac{2\sqrt{5}}{5} & \frac{\sqrt{5}}{5} \\ \end{array} \right] =\left[ \begin{array}{cc} 1 & 2 \\ 0 & 0 \\ 0 & 0 \\ \end{array} \right]
A=PΣQT=(p1,p2)Σ(q1,q2)T=
100010001
500000
[55−52552555]=
100200
特别的,假设给定一对称矩阵 A = [ 2 1 1 2 ] A=\left[ \begin{array}{cc} 2 & 1 \\ 1 & 2 \\ \end{array} \right] A=[2112] (对称矩阵),分别计算 A A T AA^T AAT和 A T A A^TA ATA,会发现:
① A A T = A T A = [ 2 1 1 2 ] [ 2 1 1 2 ] = [ 5 4 4 5 ] AA^T=A^TA=\left[ \begin{array}{cc} 2 & 1 \\ 1 & 2 \\ \end{array} \right] \left[ \begin{array}{cc} 2 & 1 \\ 1 & 2 \\ \end{array} \right] =\left[ \begin{array}{cc} 5 & 4 \\ 4 & 5 \\ \end{array} \right] AAT=ATA=[2112][2112]=[5445]
② 左奇异向量和右奇异向量构成的矩阵相等,即 P = Q = [ 2 2 − 2 2 2 2 2 2 ] P=Q=\left[ \begin{array}{cc} \frac{\sqrt{2}}{2} & -\frac{\sqrt{2}}{2} \\ \frac{\sqrt{2}}{2} & \frac{\sqrt{2}}{2} \\ \end{array} \right] P=Q=[2222−2222]
③ 该矩阵的奇异值分解和对称对角化分解相同,即 A = [ 2 2 − 2 2 2 2 2 2 ] [ 3 0 0 1 ] [ 2 2 2 2 − 2 2 2 2 ] A=\left[ \begin{array}{cc} \frac{\sqrt{2}}{2} & -\frac{\sqrt{2}}{2} \\ \frac{\sqrt{2}}{2} & \frac{\sqrt{2}}{2} \\ \end{array} \right] \left[ \begin{array}{cc} 3 & 0 \\ 0 & 1 \\ \end{array} \right] \left[ \begin{array}{cc} \frac{\sqrt{2}}{2} & \frac{\sqrt{2}}{2} \\ -\frac{\sqrt{2}}{2} & \frac{\sqrt{2}}{2} \\ \end{array} \right] A=[2222−2222][3001][22−222222]
这是由于对于正定对称矩阵而言,奇异值分解和对称对角化分解结果相同。
三、奇异值分解低秩逼近
在对称对角化分解中,若给定一个大小为 3 × 3 3\times 3 3×3的矩阵 A = [ 30 0 0 0 20 0 0 0 1 ] A=\left[ \begin{array}{ccc} 30 & 0 & 0 \\ 0 & 20 & 0 \\ 0 & 0 & 1 \\ \end{array} \right] A= 30000200001
矩阵 A A A的秩为 r a n k ( A ) = 3 rank\left(A\right)=3 rank(A)=3,特征值为 λ 1 = 30 , λ 2 = 20 , λ 3 = 1 \lambda_1=30,\lambda_2=20,\lambda_3=1 λ1=30,λ2=20,λ3=1,对应特征向量分别为 q ⃗ 1 = ( 1 , 0 , 0 ) T , q ⃗ 2 = ( 0 , 1 , 0 ) T , q ⃗ 3 = ( 0 , 0 , 1 ) T \vec{q}_1=\left(1,0,0\right)^T,\vec{q}_2=\left(0,1,0\right)^T,\vec{q}_3=\left(0,0,1\right)^T q1=(1,0,0)T,q2=(0,1,0)T,q3=(0,0,1)T
考虑任意一向量
v
⃗
=
(
2
,
4
,
6
)
T
=
2
q
⃗
1
+
4
q
⃗
2
+
6
q
⃗
3
\vec{v}=\left(2,4,6\right)^T=2\vec{q}_1+4\vec{q}_2+6\vec{q}_3
v=(2,4,6)T=2q1+4q2+6q3,则
A
v
⃗
=
A
(
2
q
⃗
1
+
4
q
⃗
2
+
6
q
⃗
3
)
=
2
λ
1
q
⃗
1
+
4
λ
2
q
⃗
2
+
6
λ
3
q
⃗
3
=
60
q
⃗
1
+
80
q
⃗
2
+
6
q
⃗
3
A\vec{v}=A\left(2\vec{q}_1+4\vec{q}_2+6\vec{q}_3\right) =2\lambda_1\vec{q}_1+4\lambda_2\vec{q}_2+6\lambda_3\vec{q}_3=60\vec{q}_1+80\vec{q}_2+6\vec{q}_3
Av=A(2q1+4q2+6q3)=2λ1q1+4λ2q2+6λ3q3=60q1+80q2+6q3
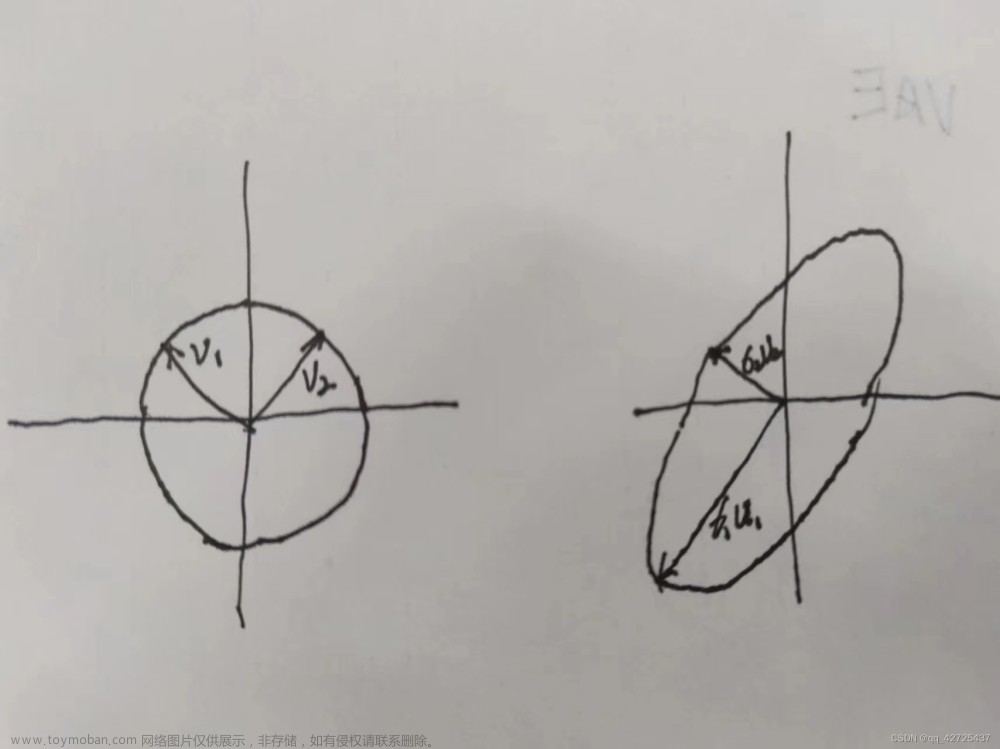
上述表明:用矩阵去乘以任意一向量的效果取决于较大的特征值及其特征向量,类似地,在奇异值分解中 较大的奇异值会决定原矩阵的“主要特征”,即 奇异值分解的低秩逼近(也称为截断奇异值分解)。
给定一个大小为
m
×
n
m\times n
m×n的矩阵
A
A
A,由于
A
=
P
Σ
Q
T
A=P\Sigma Q^T
A=PΣQT可以写成
A
=
∑
i
=
1
k
σ
i
p
⃗
i
q
⃗
i
T
=
σ
1
p
⃗
1
q
⃗
1
T
+
σ
2
p
⃗
2
q
⃗
2
T
+
.
.
.
+
σ
k
p
⃗
k
q
⃗
k
T
A=\sum_{i=1}^{k}{\sigma_i\vec{p}_i\vec{q}_i^T}=\sigma_1\vec{p}_1\vec{q}_1^T+\sigma_2\vec{p}_2\vec{q}_2^T+...+\sigma_k\vec{p}_k\vec{q}_k^T
A=i=1∑kσipiqiT=σ1p1q1T+σ2p2q2T+...+σkpkqkT
其中,
向量
p
⃗
1
,
p
⃗
2
,
.
.
.
,
p
⃗
k
\vec{p}_1,\vec{p}_2,...,\vec{p}_k
p1,p2,...,pk之间相互正交,向量
q
⃗
1
,
q
⃗
2
,
.
.
.
,
q
⃗
k
\vec{q}_1,\vec{q}_2,...,\vec{q}_k
q1,q2,...,qk之间也相互正交,
由内积
<
σ
i
p
⃗
i
q
⃗
i
T
,
σ
j
p
⃗
j
q
⃗
j
T
>
=
0
,
1
≤
i
≤
k
,
1
≤
j
≤
k
,
i
≠
j
\left<\sigma_i\vec{p}_i\vec{q}_i^T,\sigma_j\vec{p}_j\vec{q}_j^T\right>=0,1\leq i\leq k,1\leq j\leq k,i\ne j
⟨σipiqiT,σjpjqjT⟩=0,1≤i≤k,1≤j≤k,i=j 得到矩阵A的F-范数的平方为
∣
∣
A
∣
∣
F
2
=
∣
∣
σ
1
p
⃗
1
q
⃗
1
T
+
σ
2
p
⃗
2
q
⃗
2
T
+
.
.
.
+
σ
k
p
⃗
k
q
⃗
k
T
∣
∣
F
2
||A||_F^2=||\sigma_1\vec{p}_1\vec{q}_1^T+\sigma_2\vec{p}_2\vec{q}_2^T+...+\sigma_k\vec{p}_k\vec{q}_k^T||_F^2
∣∣A∣∣F2=∣∣σ1p1q1T+σ2p2q2T+...+σkpkqkT∣∣F2
=
σ
1
2
∣
∣
p
⃗
1
q
⃗
1
T
∣
∣
F
2
+
σ
2
2
∣
∣
p
⃗
2
q
⃗
2
T
∣
∣
F
2
+
.
.
.
+
σ
k
2
∣
∣
p
⃗
k
q
⃗
k
T
∣
∣
F
2
=
σ
1
2
+
σ
2
2
+
.
.
.
+
σ
k
2
=
∑
i
=
1
r
σ
i
2
=\sigma_1^2||\vec p_1\vec q_1^T||_F^2+\sigma_2^2||\vec p_2\vec q_2^T||_F^2+...+\sigma_k^2||\vec p_k\vec q_k^T||_F^2=\sigma_1^2+\sigma_2^2+...+\sigma_k^2=\sum_{i=1}^{r}{\sigma_i^2}
=σ12∣∣p1q1T∣∣F2+σ22∣∣p2q2T∣∣F2+...+σk2∣∣pkqkT∣∣F2=σ12+σ22+...+σk2=i=1∑rσi2
可知,矩阵 A A A的F-范数的平方 等于 其所有奇异值的平方和
假设 A 1 = σ 1 p ⃗ 1 q ⃗ 1 T A_1=\sigma_1\vec p_1\vec q_1^T A1=σ1p1q1T是矩阵A的一个秩一逼近(rank one approximation),那么,它所带来的误差则是 σ 2 2 + σ 3 2 + . . . + σ k 2 \sigma_2^2+\sigma_3^2+...+\sigma_k^2 σ22+σ32+...+σk2( k k k是矩阵 A A A的秩),如何证明 A 1 = σ 1 p ⃗ 1 q ⃗ 1 T A_1=\sigma_1\vec p_1\vec q_1^T A1=σ1p1q1T是最好的秩一逼近呢?
由于 ∣ ∣ A − A 1 ∣ ∣ F 2 = ∣ ∣ P Σ Q T − A 1 ∣ ∣ F 2 = ∣ ∣ Σ − P T A 1 Q ∣ ∣ F 2 ||A-A_1||_F^2=||P\Sigma Q^T-A_1||_F^2=||\Sigma-P^TA_1Q||_F^2 ∣∣A−A1∣∣F2=∣∣PΣQT−A1∣∣F2=∣∣Σ−PTA1Q∣∣F2
令 P T A 1 Q = α x ⃗ y ⃗ T P^TA_1Q=\alpha \vec x\vec y^T PTA1Q=αxyT,其中, α \alpha α是一个正常数,向量 x ⃗ \vec x x 和 y ⃗ \vec y y 分别是大小为 m × 1 m\times 1 m×1和 n × 1 n\times 1 n×1的单位向量,则
∣ ∣ Σ − P T A 1 Q ∣ ∣ F 2 = ∣ ∣ Σ − α x ⃗ y ⃗ T ∣ ∣ F 2 = ∣ ∣ Σ ∣ ∣ F 2 + α 2 − 2 α < Σ , x ⃗ y ⃗ T > ||\Sigma-P^TA_1Q||_F^2=||\Sigma-\alpha \vec x\vec y^T||_F^2 =||\Sigma||_F^2+\alpha^2-2\alpha \left<\Sigma, \vec x\vec y^T\right> ∣∣Σ−PTA1Q∣∣F2=∣∣Σ−αxyT∣∣F2=∣∣Σ∣∣F2+α2−2α⟨Σ,xyT⟩
单独看大小为 m × n m\times n m×n的矩阵 Σ \Sigma Σ和 x ⃗ y ⃗ T \vec x\vec y^T xyT的内积 < Σ , x ⃗ y ⃗ T > \left<\Sigma, \vec x\vec y^T\right> ⟨Σ,xyT⟩,会发现
< Σ , x ⃗ y ⃗ T > = ∑ i = 1 k σ i x i y i ≤ ∑ i = 1 k σ i ∣ x i ∣ ∣ y i ∣ \left<\Sigma, \vec x\vec y^T\right>=\sum_{i=1}^{k}{\sigma_i x_i y_i}\leq \sum_{i=1}^{k}{\sigma_i\left| x_i\right|\left| y_i\right|} ⟨Σ,xyT⟩=i=1∑kσixiyi≤i=1∑kσi∣xi∣∣yi∣ ≤ σ 1 ∑ i = 1 k ∣ x i ∣ ∣ y i ∣ = σ 1 < x ⃗ ∗ , y ⃗ ∗ > ≤ σ 1 ∣ ∣ x ⃗ ∗ ∣ ∣ ⋅ ∣ ∣ y ⃗ ∗ ∣ ∣ ≤ σ 1 ∣ ∣ x ⃗ ∣ ∣ ⋅ ∣ ∣ y ⃗ ∣ ∣ = σ 1 \leq\sigma_1 \sum_{i=1}^{k}{\left| x_i\right|\left| y_i\right|}=\sigma_1\left<\vec x^*,\vec y^*\right> \leq \sigma_1||\vec x^*||\cdot ||\vec y^*||\leq \sigma_1||\vec x||\cdot ||\vec y||=\sigma_1 ≤σ1i=1∑k∣xi∣∣yi∣=σ1⟨x∗,y∗⟩≤σ1∣∣x∗∣∣⋅∣∣y∗∣∣≤σ1∣∣x∣∣⋅∣∣y∣∣=σ1
其中,
①
x
i
,
y
i
x_i,y_i
xi,yi分别是向量
x
⃗
\vec x
x和
y
⃗
\vec y
y的第
i
i
i个元素;
② 向量
x
⃗
∗
=
(
∣
x
1
∣
,
∣
x
2
∣
,
.
.
.
,
∣
x
k
∣
)
T
\vec x^*=\left(\left|x_1\right|,\left|x_2\right|,...,\left|x_k\right|\right)^T
x∗=(∣x1∣,∣x2∣,...,∣xk∣)T的大小为
k
×
1
k\times 1
k×1,向量
y
⃗
∗
=
(
∣
y
1
∣
,
∣
y
2
∣
,
.
.
.
,
∣
y
k
∣
)
T
\vec y^*=\left(\left|y_1\right|,\left|y_2\right|,...,\left|y_k\right|\right)^T
y∗=(∣y1∣,∣y2∣,...,∣yk∣)T的大小也为
k
×
1
k\times 1
k×1,另外,以
x
⃗
∗
\vec x^*
x∗为例,
∣
∣
x
⃗
∗
∣
∣
=
x
1
2
+
x
2
2
+
.
.
.
+
x
k
2
||\vec x^*||=\sqrt{x_1^2+x_2^2+...+x_k^2}
∣∣x∗∣∣=x12+x22+...+xk2是向量的模,则
∣
∣
A
−
A
1
∣
∣
F
2
||A-A_1||_F^2
∣∣A−A1∣∣F2(残差矩阵的平方和)为
∣ ∣ Σ − α x ⃗ y ⃗ T ∣ ∣ F 2 ≥ ∣ ∣ Σ ∣ ∣ F 2 + α 2 − 2 α σ 1 = ∣ ∣ Σ ∣ ∣ F 2 + ( α − σ 1 ) 2 − σ 1 2 ||\Sigma-\alpha \vec x\vec y^T||_F^2\geq ||\Sigma||_F^2+\alpha^2-2\alpha \sigma_1 =||\Sigma||_F^2+\left(\alpha-\sigma_1\right)^2-\sigma_1^2 ∣∣Σ−αxyT∣∣F2≥∣∣Σ∣∣F2+α2−2ασ1=∣∣Σ∣∣F2+(α−σ1)2−σ12
当且仅当 α = σ 1 \alpha=\sigma_1 α=σ1时, ∣ ∣ A − A 1 ∣ ∣ F 2 ||A-A_1||_F^2 ∣∣A−A1∣∣F2取得最小值 σ 2 2 + σ 3 2 + . . . + σ k 2 \sigma_2^2+\sigma_3^2+...+\sigma_k^2 σ22+σ32+...+σk2,此时,矩阵 A A A的秩一逼近恰好是 A 1 = σ 1 p ⃗ 1 q ⃗ 1 T A_1=\sigma_1\vec p_1\vec q_1^T A1=σ1p1q1T。
当然,可以证明
A
2
=
σ
2
p
⃗
2
q
⃗
2
T
A_2=\sigma_2\vec p_2\vec q_2^T
A2=σ2p2q2T是矩阵
A
−
A
1
A-A_1
A−A1的最佳秩一逼近,
以此类推,
A
r
=
σ
r
p
⃗
r
q
⃗
r
T
,
r
<
k
A_r=\sigma_r\vec p_r\vec q_r^T,r< k
Ar=σrprqrT,r<k 是矩阵
A
−
A
1
−
A
2
−
.
.
.
−
A
r
−
1
A-A_1-A_2-...-A_{r-1}
A−A1−A2−...−Ar−1的最佳秩一逼近。
由于矩阵
A
1
+
A
2
+
.
.
.
+
A
r
A_1+A_2+...+A_r
A1+A2+...+Ar的秩为
r
r
r,这样,可以得到矩阵
A
A
A的最佳秩
r
r
r逼近(rank-r approximation),即
A
≈
A
1
+
A
2
+
.
.
.
+
A
r
=
∑
i
=
1
r
A
i
A\approx A_1+A_2+...+A_r=\sum_{i=1}^{r}{A_i}
A≈A1+A2+...+Ar=i=1∑rAi这里得到的矩阵
P
r
P_r
Pr的大小为
m
×
r
m\times r
m×r,矩阵
Σ
r
\Sigma_r
Σr的大小为
r
×
r
r\times r
r×r,矩阵
Q
r
Q_r
Qr的大小为
n
×
r
n\times r
n×r,矩阵A可以用
P
r
Σ
r
Q
r
T
P_r\Sigma_rQ_r^T
PrΣrQrT来做近似。
用低秩逼近去近似矩阵A有什么价值呢?
给定一个很大的矩阵,大小为
m
×
n
m\times n
m×n,需要存储的元素数量是
m
n
mn
mn个,当矩阵
A
A
A的秩
k
k
k远小于
m
m
m和
n
n
n,只需要存储
k
(
m
+
n
+
1
)
k(m+n+1)
k(m+n+1)个元素就能得到原矩阵
A
A
A,即
k
k
k个奇异值、
k
m
km
km个左奇异向量的元素和kn个右奇异向量的元素;若采用一个秩
r
r
r矩阵
A
1
+
A
2
+
.
.
.
+
A
r
A_1+A_2+...+A_r
A1+A2+...+Ar去逼近,我们则只需要存储更少的
r
(
m
+
n
+
1
)
r(m+n+1)
r(m+n+1)个元素。因此,奇异值分解是一种重要的数据压缩方法。文章来源:https://www.toymoban.com/news/detail-728602.html
参考链接1
参考链接2
参考链接3
参考链接4文章来源地址https://www.toymoban.com/news/detail-728602.html
到了这里,关于ORB-SLAM之SVD奇异值分解——理论 (一)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!