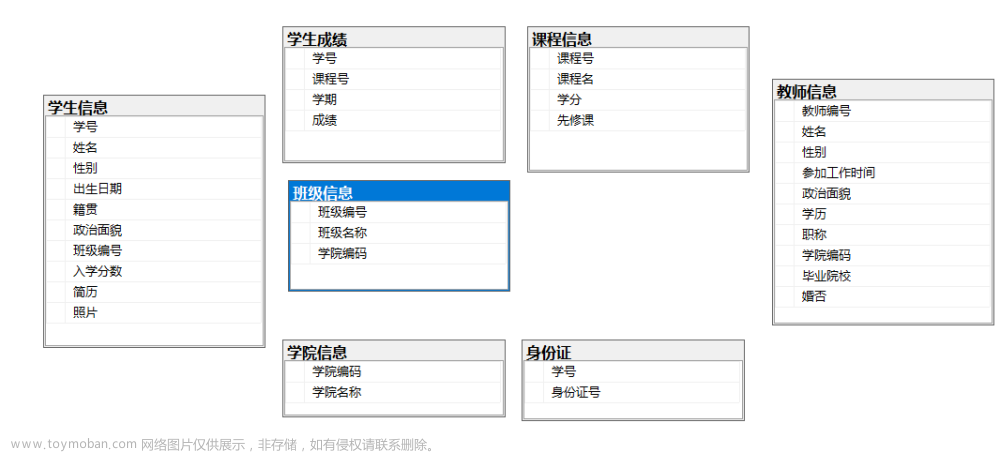
目录
连接数据库准备工作
1、查询"01"课程比"02"课程成绩高的学生的信息及课程分数
2、查询"01"课程比"02"课程成绩低的学生的信息及课程分数
3、查询平均成绩大于等于60分的同学的学生编号和学生姓名和平均成绩
4、查询平均成绩小于60分的同学的学生编号和学生姓名和平均成绩
5、查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩
6、查询"李"姓老师的数量
7、查询学过"李四"老师授课的同学的信息
8、查询没有学过"李四"老师授课的同学的信息
9、查询学过编号为"01"并且也学过编号为"02"的课程的同学的信息
10、查询学过编号为"01"并且没有学过编号为"02"的课程的同学的信息
11、查询没有学全所有课程的同学的信息
12、查询至少有一门课与学号为"01"的同学所学相同的同学的信息
13、查询和"01"号的同学学习的课程完全相同的其他同学的信息
14、查询没学过"张三"老师讲授的任一门课程的学生姓名
15、查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩
16、检索"01"课程分数小于60,按分数降序排列的学生信息
17、按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩
18、查询各科成绩最高分、最低分和平均分:
以如下形式显示:课程ID,课程name,最高分,最低分,平均分,及格率,中等率,优良率
及格为>=60,中等为:70-80,优良为:80-90,优秀为:>=90
19、按各科成绩进行排序,并显示排名
20、查询学生的总成绩并进行排名
21、查询不同老师所教不同课程平均分从高到低显示
22、查询所有课程的成绩第2名到第3名的学生信息及该课程成绩
23、统计各科成绩各分数段人数:课程编号,课程名称, 100-85 , 85-70 , 70-60 , 0-60 及所占百分比
24、查询学生平均成绩及其名次
25、查询各科成绩前三名的记录
26、查询每门课程被选修的学生数
27、查询出只有两门课程的全部学生的学号和姓名
28、查询男生、女生人数
29、查询名字中含有"风"字的学生信息
30、查询同名同性学生名单,并统计同名人数
31、查询1990年出生的学生名单(注:Student表中Sage列的类型是datetime)
32、查询每门课程的平均成绩,结果按平均成绩降序排列,平均成绩相同时,按课程编号升序排列
33、查询平均成绩大于等于85的所有学生的学号、姓名和平均成绩
34、查询课程名称为"数学",且分数低于60的学生姓名和分数
35、查询所有学生的课程及分数情况
36、查询任何一门课程成绩在70分以上的姓名、课程名称和分数
37、查询课程不及格的学生
38、查询课程编号为01且课程成绩在80分及以上的学生的学号和姓名
39、求每门课程的学生人数
40、查询选修"张三"老师所授课程的学生中,成绩最高的学生信息及其成绩
41、查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩
42、查询每门功课成绩最好的前两名
43、统计每门课程的学生选修人数(超过5人的课程才统计)。要求输出课程号和选修人数, 查询结果按人数降序排列,若人数相同,按课程号升序排列
44、检索至少选修两门课程的学生学号
45、查询选修了全部课程的学生信息
46、查询各学生的年龄
47、查询本周过生日的学生
48、查询下周过生日的学生
49、查询本月过生日的学生
50、查询下月过生日的学生
连接数据库准备工作
创建DataFrame
val spark: SparkSession = SparkSession
.builder()
.appName("Spark_SQL50")
.master("local[*]")
.getOrCreate()
import spark.implicits._
import org.apache.spark.sql.functions._
val url = "jdbc:mysql://192.168.142.129:3306/sql50"
val user = "root"
val pwd = "123456"
val driver = "com.mysql.cj.jdbc.Driver"
val properties = new Properties()
properties.setProperty("user", user)
properties.setProperty("password", pwd)
properties.setProperty("driver", driver)
val score = spark.read.jdbc(url, "score", properties)
val course = spark.read.jdbc(url, "course", properties)
val student = spark.read.jdbc(url, "student", properties)
val teacher = spark.read.jdbc(url, "teacher", properties)
val student_copy1 = spark.read.jdbc(url, "student_copy1", properties)1、查询"01"课程比"02"课程成绩高的学生的信息及课程分数
score.as("s1").join(score.as("s2"), "s_id")
.where("s1.s_score>s2.s_score and s1.c_id = 01 and s2.c_id = 02")
.join(student, "s_id")
.select("s_name", "s1.c_id", "s1.s_score", "s2.c_id", "s2.s_score")
.show()

2、查询"01"课程比"02"课程成绩低的学生的信息及课程分数
score.as("s1").join(score.as("s2"), "s_id")
.where("s1.s_score < s2.s_score and s1.c_id = 01 and s2.c_id = 02")
.join(student, "s_id")
.select("s_name", "s1.c_id", "s1.s_score", "s2.c_id", "s2.s_score")
.show()

3、查询平均成绩大于等于60分的同学的学生编号和学生姓名和平均成绩
score.groupBy("s_id")
.avg("s_score")
.where($"avg(s_score)">=60)
.join(student, "s_id")
.select("s_id", "s_name", "avg(s_score)")
.show

4、查询平均成绩小于60分的同学的学生编号和学生姓名和平均成绩
student
.join(score.groupBy("s_id").avg("s_score"), Seq("s_id"), "left")
.where($"avg(s_score)" < 60 || $"avg(s_score)".isNull)
.select("s_id", "s_name", "avg(s_score)")
.show

5、查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩
student
.join(score.groupBy("s_id").count(),Seq("s_id"), "left")
.join(score.groupBy("s_id").sum("s_score"), Seq("s_id"), "left")
.select("s_id", "s_name", "count", "sum(s_score)")
.show()

6、查询"李"姓老师的数量
println(teacher
.where($"t_name".like("李%"))
.count())
7、查询学过"李四"老师授课的同学的信息
student.join(score,"s_id")
.join(course, "c_id")
.join(teacher, "t_id")
.where($"t_name" === "李四")
.select("s_name", "c_name","t_name")
.show

8、查询没有学过"李四"老师授课的同学的信息
student.join(student.join(score,Seq("s_id"), "left")
.join(course,Seq("c_id"), "left")
.join(teacher,Seq("t_id"), "left")
.where($"t_name" === "李四").select("s_id","s_score"),Seq("s_id"), "left"
).where($"s_score".isNull)
.select("s_id", "s_name")
.show()

9、查询学过编号为"01"并且也学过编号为"02"的课程的同学的信息
student
.join(score,Seq("s_id")).where("c_id == 01")
.join(student.join(score,Seq("s_id")).where("c_id == 02"),"s_id")
.show()

10、查询学过编号为"01"并且没有学过编号为"02"的课程的同学的信息
student.as("s1")
.join(score, "s_id").where("c_id == 01")
.join(student.as("s2").join(score, "s_id")
.where("c_id == 02"), Seq("s_id"), "left")
.where($"s2.s_name".isNull)
.show()

11、查询没有学全所有课程的同学的信息
student.join(
student.join(score,"s_id").join(course,"c_id").groupBy("s_id").count()
, Seq("s_id"), "left"
).where($"count" < course.count() || $"count".isNull).show()

12、查询至少有一门课与学号为"01"的同学所学相同的同学的信息
student.as("stu")
.join(score.as("sc").join(score.where($"s_id"==="01"),
Seq("c_id"), "left"),
Seq("s_id"))
.where($"stu.s_id".notEqual("01"))
.select("stu.s_id","s_name")
.distinct()
.show

13、查询和"01"号的同学学习的课程完全相同的其他同学的信息
student
.join(score, "s_id")
.groupBy($"s_id").count().where($"count".equalTo(3))
.where($"s_id".notEqual("01"))
.join(student, Seq("s_id"), "left")
.show()

14、查询没学过"张三"老师讲授的任一门课程的学生姓名
student
.join(score, "s_id")
.join(course,"c_id")
.join(teacher,"t_id")
.where($"t_name"==="张三")
.as("stu1")
.join(student.as("stu2"),Seq("s_id"),"right")
.where($"t_name".isNull)
.select("stu2.s_id","stu2.s_name")
.show

15、查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩
score
.where($"s_score" < 60).groupBy("s_id").count()
.where($"count" >= 2)
.join(score,"s_id")
.groupBy("s_id")
.agg(round(avg("s_score"),2))
.join(student,"s_id")
.show

16、检索"01"课程分数小于60,按分数降序排列的学生信息
score
.where($"c_id"==="01" && $"s_score" < 60)
.join(student,"s_id")
.sort(desc("s_score"))
.show

17、按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩
score.groupBy("s_id").agg(round(avg("s_score"),2).as("avgScore"))
.join(score,"s_id")
.join(student,"s_id")
.orderBy($"avgScore".desc)
.show

18、查询各科成绩最高分、最低分和平均分:
以如下形式显示:课程ID,课程name,最高分,最低分,平均分,及格率,中等率,优良率
及格为>=60,中等为:70-80,优良为:80-90,优秀为:>=90
//1 先求出 及格,中等,优良,优秀 各阶段人数
val numDF = score.groupBy("c_id").count()
val passDF = score.where($"s_score" >= 60).groupBy("c_id").count()
val midDF = score.where($"s_score" >= 70 && $"s_score" < 80).groupBy("c_id").count()
val goodDF = score.where($"s_score" >= 80 && $"s_score" < 90).groupBy("c_id").count()
val bestDF = score.where($"s_score" >= 90).groupBy("c_id").count()
//2 求出及格率,中等率,优良率,优秀率
val passPerDF = numDF.as("n")
.join(passDF.as("m"), "c_id").withColumn("passPer", round($"m.count" / $"n.count", 2))
.drop("count")
val midPerDF = numDF.as("n")
.join(midDF.as("m"), "c_id").withColumn("midPer", round($"m.count" / $"n.count", 2))
.drop("count")
val goodPerDF = numDF.as("n")
.join(goodDF.as("m"), "c_id").withColumn("goodPer", round($"m.count" / $"n.count", 2))
.drop("count")
val bestPerDF = numDF.as("n")
.join(bestDF.as("m"), "c_id").withColumn("bestPer", round($"m.count" / $"n.count", 2))
.drop("count")
//3 求出课程最高分,最低分,平均分 join各比率
course
.join(
score.groupBy("c_id")
.agg(max("s_score").as("maxScore"),
min("s_score").as("minScore"),
round(avg("s_score"),2).as("avgScore")),"c_id")
.join(passPerDF,Seq("c_id"),"left")
.join(midPerDF,Seq("c_id"),"left")
.join(goodPerDF,Seq("c_id"),"left")
.join(bestPerDF,Seq("c_id"),"left")
.drop("t_id")
.show

19、按各科成绩进行排序,并显示排名
score
.withColumn("rank",
dense_rank()
.over(
Window.partitionBy("c_id").orderBy($"s_score".desc)
)
)
.show()

20、查询学生的总成绩并进行排名
score
.groupBy("s_id")
.sum("s_score")
.withColumn("rank",dense_rank().over(Window.orderBy($"sum(s_score)".desc)))
.show()

21、查询不同老师所教不同课程平均分从高到低显示
score
.groupBy("c_id")
.agg(round(avg("s_score"), 2).as("avgScore"))
.withColumn("rank", dense_rank().over(Window.orderBy($"avgScore".desc)))
.show()

22、查询所有课程的成绩第2名到第3名的学生信息及该课程成绩
score
.withColumn("rank", dense_rank().over(Window.partitionBy("c_id").orderBy($"s_score".desc)))
.where($"rank".isin(2,3))
.join(student,"s_id")
.show()

23、统计各科成绩各分数段人数:课程编号,课程名称, 100-85 , 85-70 , 70-60 , 0-60 及所占百分比
//方法一
//1 先求出 总人数 及 100-85 , 85-70 , 70-60 , 0-60 各阶段人数
val numDF = score.groupBy("c_id").count()
val passDF = score.where($"s_score" >= 0 && $"s_score" < 60).groupBy("c_id").count()
val midDF = score.where($"s_score" >= 60 && $"s_score" < 70).groupBy("c_id").count()
val goodDF = score.where($"s_score" >= 70 && $"s_score" < 85).groupBy("c_id").count()
val bestDF = score.where($"s_score" >= 85 && $"s_score" <= 100).groupBy("c_id").count()
//2 求出 100-85 , 85-70 , 70-60 , 0-60所占百分比
val passPerDF = numDF.as("n")
.join(passDF.as("m"), "c_id").withColumn("lt60", round($"m.count" / $"n.count", 2))
.drop("count")
val midPerDF = numDF.as("n")
.join(midDF.as("m"), "c_id").withColumn("70-60", round($"m.count" / $"n.count", 2))
.drop("count")
val goodPerDF = numDF.as("n")
.join(goodDF.as("m"), "c_id").withColumn("85-70", round($"m.count" / $"n.count", 2))
.drop("count")
val bestPerDF = numDF.as("n")
.join(bestDF.as("m"), "c_id").withColumn("100-85", round($"m.count" / $"n.count", 2))
.drop("count")
//3 course表 join各比率
course
.join(passPerDF,Seq("c_id"),"left")
.join(midPerDF,Seq("c_id"),"left")
.join(goodPerDF,Seq("c_id"),"left")
.join(bestPerDF,Seq("c_id"),"left")
.drop("t_id")
.show
//方法2 count(when(condition), value),
// 由于between操作符是包含左右边界的,临界点分数存在重复计算,此方法仅供参考
score.groupBy("c_id").agg(
count("s_score").as("count"),
count(when($"s_score".between(85, 100), 1)).as("lt60Row"),
count(when($"s_score".between(70, 85), 1)).as("60-70Row"),
count(when($"s_score".between(60, 70), 1)).as("70-85Row"),
count(when($"s_score".between(0, 60), 1)).as("85-100Row")
)
.withColumn("lt60", round($"lt60Row" / $"count", 2))
.withColumn("60-70", round($"60-70Row" / $"count", 2))
.withColumn("70-85", round($"70-85Row" / $"count", 2))
.withColumn("85-100", round($"85-100Row" / $"count", 2))
.join(course, "c_id")
.select("c_id", "c_name", "lt60", "60-70", "70-85", "85-100")
.show()



24、查询学生平均成绩及其名次
score
.groupBy("s_id")
.agg(round(avg("s_score"), 2).as("avgScore"))
.withColumn("rank",dense_rank().over(Window.orderBy($"avgScore".desc)))
.show()

25、查询各科成绩前三名的记录
score
.withColumn("rank",
dense_rank().over(Window.partitionBy("c_id").orderBy($"s_score".desc))
)
.where($"rank".between(1,3))
.show()

26、查询每门课程被选修的学生数
score
.groupBy("c_id")
.count()
.show()

27、查询出只有两门课程的全部学生的学号和姓名
score
.groupBy("s_id")
.agg(count($"c_id").as("count"))
.where($"count" === 2)
.join(student, "s_id")
.select("s_id", "s_name", "count")
.show()

28、查询男生、女生人数
student
.groupBy("s_sex")
.count()
.show()

29、查询名字中含有"风"字的学生信息
student
.where($"s_name".contains("风"))
.show()

30、查询同名同性学生名单,并统计同名人数
student_copy1
.groupBy("s_name","s_sex")
.count()
.where($"count" > 1)
.show

31、查询1990年出生的学生名单(注:Student表中Sage列的类型是datetime)
student
.where(year($"s_birth")==="1990")
.show

32、查询每门课程的平均成绩,结果按平均成绩降序排列,平均成绩相同时,按课程编号升序排列
score
.groupBy("c_id")
.avg("s_score")
.orderBy($"avg(s_score)".desc, $"c_id")
.show()

33、查询平均成绩大于等于85的所有学生的学号、姓名和平均成绩
score
.groupBy("s_id")
.avg("s_score")
.where($"avg(s_score)" >= 85)
.join(student,"s_id")
.select("s_id", "s_name", "avg(s_score)")
.show()

34、查询课程名称为"数学",且分数低于60的学生姓名和分数
score
.join(course, "c_id")
.where($"c_name" === "数学" && $"s_score" < 60)
.join(student, "s_id")
.select("s_name", "s_score")
.show

35、查询所有学生的课程及分数情况
student
.join(score, Seq("s_id"), "left")
.show()

36、查询任何一门课程成绩在70分以上的姓名、课程名称和分数
score
.where($"s_score" > 70)
.join(student, "s_id")
.join(course, "c_id")
.select("s_name", "c_name", "s_score")
.show()

37、查询课程不及格的学生
score
.where($"s_score" < 60)
.show()

38、查询课程编号为01且课程成绩在80分及以上的学生的学号和姓名
score
.where($"c_id" === "01" && $"s_score" >= 80)
.join(student, "s_id")
.select("s_id", "s_name", "c_id","s_score")
.show()

39、求每门课程的学生人数
score
.groupBy("c_id")
.count()
.show()

40、查询选修"张三"老师所授课程的学生中,成绩最高的学生信息及其成绩
score
.join(course, "c_id")
.join(teacher, "t_id")
.where($"t_name" === "张三")
.orderBy($"s_score".desc)
.limit(1)
.join(student, "s_id")
.show()

41、查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩
score
.groupBy("s_score")
.count()
.where($"count" > 1)
.join(score, "s_score")
.show()

42、查询每门功课成绩最好的前两名
score
.withColumn("rank",
rank().over(Window.partitionBy("c_id").orderBy($"s_score".desc))
)
.where($"rank".isin(1, 2))
.show()

43、统计每门课程的学生选修人数(超过5人的课程才统计)。要求输出课程号和选修人数, 查询结果按人数降序排列,若人数相同,按课程号升序排列
score
.groupBy("c_id")
.count()
.where($"count" > 5)
.orderBy($"count".desc, $"c_id")
.show

44、检索至少选修两门课程的学生学号
score
.groupBy("s_id").count()
.where($"count" >= 2)
.show()

45、查询选修了全部课程的学生信息
score
.groupBy("s_id")
.count()
.where($"count" === course.count())
.join(student, "s_id")
.show()

46、查询各学生的年龄
student
.withColumn("age", year(current_date()) - year($"s_birth"))
.show()

47、查询本周过生日的学生
student
.withColumn("birthOfWeek", weekofyear($"s_birth"))
.where($"birthOfWeek" === weekofyear(current_date()))
.show
48、查询下周过生日的学生
student
.withColumn("birthOfWeek", weekofyear($"s_birth"))
.where($"birthOfWeek" === weekofyear(current_date()) + 1)
.show 文章来源:https://www.toymoban.com/news/detail-728798.html
文章来源:https://www.toymoban.com/news/detail-728798.html
49、查询本月过生日的学生
student
.withColumn("birthOfMonth", month($"s_birth"))
.where($"birthOfMonth" === month(current_date()))
.show 文章来源地址https://www.toymoban.com/news/detail-728798.html
文章来源地址https://www.toymoban.com/news/detail-728798.html
50、查询下月过生日的学生
student
.withColumn("birthOfMonth", month($"s_birth"))
.where($"birthOfMonth" === month(current_date() + 1))
.show到了这里,关于Spark--经典SQL50题的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!