目录
概要
Motivation
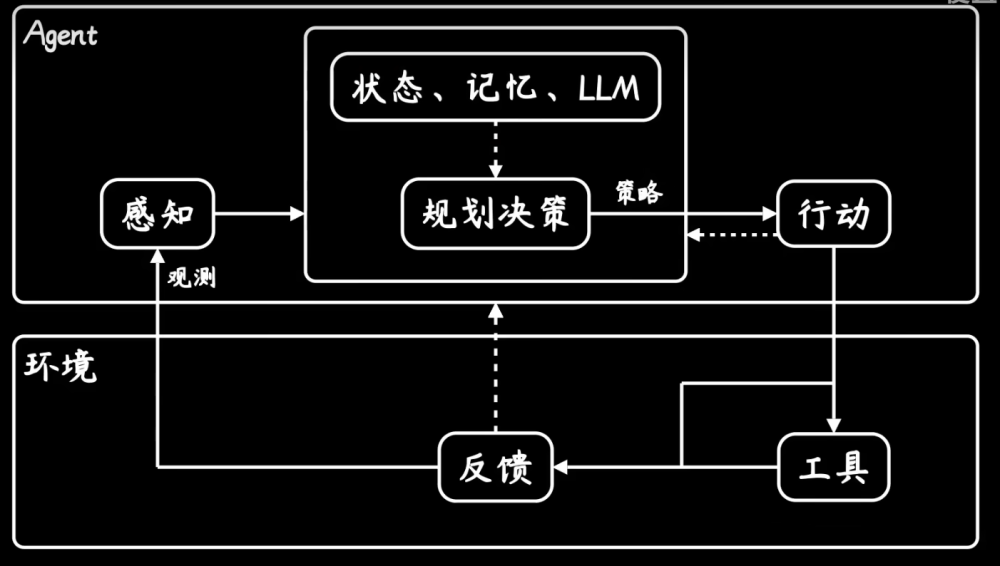
整体架构流程
技术细节
Multi-scale Center Proposal Network
Multi-scale Center Transformer Decoder
Multi-frame CenterFormer
小结
论文地址:[2209.05588] CenterFormer: Center-based Transformer for 3D Object Detection (arxiv.org)
代码地址:GitHub - TuSimple/centerformer: Implementation for CenterFormer: Center-based Transformer for 3D Object Detection (ECCV 2022)
概要
CenterFormer,这是一种基于中心的变压器网络,用于3D目标检测。CenterFormer首先使用中心热图在标准基于体素的点云编码器之上选择中心候选。然后它使用中心候选的特征作为转换器中的查询嵌入。设计了一种通过交叉注意融合特征的方法,能进一步聚合多帧的特征。最后,添加回归头来预测输出中心特征表示上的边界框。整体设计降低了变压器结构的收敛难度和计算复杂度;与无锚目标检测网络强基线相比有显著改进。
Motivation
- 与图像域目标检测相比,LiDAR数据中的扫描点可能是稀疏且不规则的,这取决于与传感器的距离;
- 目前的两阶段网络缺乏上下文和全局信息学习,它们只使用提案的局部特征(RoI)来优化结果,其他方框或相邻位置中的特征也可能有利于细化,但这些特征被忽略;
- 自动驾驶场景的环境不是静止的。当使用扫描序列时,局部特征学习有更多的局限性;
- 变压器解码器使用大的特征映射,查询嵌入很难在训练过程中集中;
- DETRstyle编码器-解码器变压器网络有两个主要问题:随着输入大小的增加,计算复杂度呈二次增长,限制了转换器仅将低维特征作为输入,这导致小对象的性能较低;查询嵌入是通过网络学习的,使得训练很难收敛。
整体架构流程
一种基于中心的变压器网络,称为中心变压器(CenterFormer),用于三维目标检测。具体来说,首先使用标准的基于Voxel的骨干网将点云编码为BEV特征表示。接下来,使用多尺度中心提议网络将特征转换为不同的尺度并预测初始中心位置。所提出的中心的特征被输入Transformer解码器作为query embedding。在每个Transformer 模块中,使用可变形交叉注意力层来有效地聚合来自多尺度特征图的特征。然后输出对象表示回归到其他对象属性以创建最终的对象预测。
如下图所示,该方法可以对对象级连接和远程特征注意力进行建模。为了进一步探索变压器的能力,还提出了一种多帧设计,通过交叉注意融合来自不同帧的特征。

上图中,center前与 RCNN 样式检测器的比较。RCNN 在 RoI 中聚合点或网格特征,而居中前可以通过注意力机制学习对象级上下文信息和远程特征。

上图所示为CenterFormer的整体架构。该网络由四个部分组成:将原始点云编码为 BEV 特征表示的体素特征编码器、多尺度中心提议网络 (CPN)、基于中心的Transformer解码器和用于预测边界框的回归头。
技术细节
Multi-scale Center Proposal Network
DETR 风格的 Transformer 编码器需要将特征图压缩成小尺寸,以便计算成本可以接受。这使得网络失去了对检测小物体至关重要的细粒度特征,这些小物体通常占据 BEV 地图中小于 1% 的空间。因此,提出了一个多尺度中心提议网络(CPN)来代替 BEV 特征的Transformer编码器。为了准备多尺度特征图,使用特征金字塔网络将 BEV 特征表示处理成3个不同的尺度。在每个尺度结束时,添加一个卷积块注意力模块 (CBAM),以通过通道和空间注意力来增强特征。
使用最高比例特征图 C 上的中心Head来预测目标中心的 l 通道Heatmap。每个通道包含一个类的Heatmap分数。将前 N 个Heatmap分数的位置作为中心提案。在实验中凭经验使用 N = 500。
Multi-scale Center Transformer Decoder

在建议的中心位置提取特征作为Transformer解码器的query embedding。使用线性层将中心的位置编码为位置嵌入。传统的 DETR 解码器使用可学习的参数初始化query。因此,在解码器中获得的注意力权重在所有特征中几乎相同。通过使用中心特征作为初始query embedding,可以引导训练专注于包含有意义的目标信息的特征。
在 vanilla Transformer 解码器中使用相同的自注意力层来学习目标之间的上下文注意力。计算中心query对所有多尺度 BEV 特征的交叉注意力的复杂度为 :

由于 BEV 特征图的分辨率需要相对较大以保持小目标的细粒度特征,因此将所有 BEV 特征用作attending keypoints是不切实际的。或者,将attending keypoints限制在每个尺度的中心位置附近的一个 3×3 小窗口,如上图 所示。这种交叉注意力的复杂度为 ,比正常实现更有效。由于具有多尺度特征,因此能够在提议的中心周围捕获广泛的特征。多尺度交叉注意力可以表述为:

其中p表示中心建议,这里的Ωj是中心周围的窗口,s是尺度的索引。前馈层也保持不变。文章来源:https://www.toymoban.com/news/detail-728879.html
Multi-frame CenterFormer
多帧通常用于 3D 检测以提高性能。当前基于 CNN 的检测器无法有效融合快速移动物体的特征,而由于注意力机制,transformer 结构更适合融合。为了进一步探索 CenterFormer 的潜力,提出了一种使用交叉注意力transformer的多帧特征融合方法。使用相同的骨干网络单独处理每个帧。前一帧的最后一个 BEV 特征被转换为当前坐标,并与中心头和交叉注意力层中的当前 BEV 特征融合。文章来源地址https://www.toymoban.com/news/detail-728879.html
小结
- 引入了一种基于中心的变压器网络进行3D目标检测。
- 使用中心特征作为初始查询嵌入query embedding来促进Transformer的学习。
- 提出了一种多尺度交叉注意层来有效地聚合相邻特征,而不会显著增加计算复杂度。
- 建议使用交叉注意Transformer来融合来自不同帧的对象特征。
- 方法大大优于所有以前发布的方法,在Waymo开放数据集上设置了新的最先进的性能。
到了这里,关于论文阅读:CenterFormer: Center-based Transformer for 3D Object Detection的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!




![[异构图-论文阅读]Heterogeneous Graph Transformer](https://imgs.yssmx.com/Uploads/2024/02/737736-1.png)