声明:只是因为工作中需要,且基本不会对别人的网站构成什么不好的影响,做个思路记录!!!
尊重网站所有者、控制请求频率、遵守网站规则、尊重个人隐私
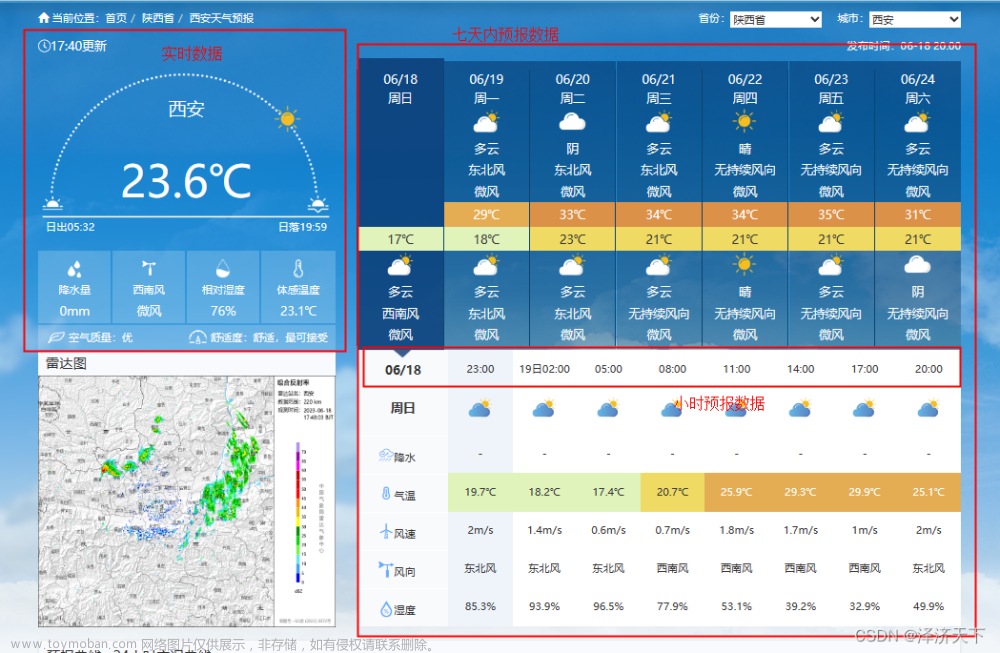
平常工作中难免会遇到需要爬取别人网站的需求,例如爬取兑换之类的流程,把接口爬取下来封装到项目中,这种一般不会对别人的网站有什么的影响,因为也是正常流程下单,例如下面的活动截图:
- 1、先理解需求,从需求和界面上看,很容易知道我们基本只需要获取两个接口,一个是发送验证码接口,一个是兑换接口。当然也可能存在前置接口,具体情况具体分析
- 2、先不要急着分析网站源码,可以先尝试找个手机号发送验证码,看看请求了哪些接口,接口的参数是什么,返回的数据是什么,例如:


- 3、从请求接口的参数的返回分析,这个网站的数据部分接口需要加密,部分不需要,如果不需要加密的接口,基本很容易就获取请求参数,这里可以大胆猜测accessId、reqId可能为uuid,reqMethod为请求的方法,encrypted表示接口请求参数是否需要加密,但是光这样看有点难以看出data和dataKey是什么加密算法加密而成,dataKey大概率是解密data的关键密钥。这里建议一般情况下看一下加密后的数据的长度,是不是一些比较特殊的长度,比如36位、512位之类的长度,可以根据这个长度大胆猜测是否是平常常用的算法。
- 4、对网站有个大概的数据交互认识之后,我们就可以知道难点基本在数据加密这一块,这时候就可以来看源码了,这里的思路我一般是直接定位到“发送验证码”的按钮上,然后找到F12控制台元素的事件监听器的click事件上,直接进入相关的代码中,就可以看到这个按钮的点击事件的代码了。
- 5、网站的代码都是经过编译的,且一般线上是不会直接开放源代码的,这种时候如何光看编译过后的代码,有时候是比较难以理解,这种时候就需要打断点,一步步调试了,看函数的参数和返回值,以及大概的处理过程。
- 6、前面已经分析过了,难点就在加密算法上,经过代码分析找到加密部分的代码,如下图:

从这段的代码中,存在RSA和AES的字眼,且打断点都走了这些函数,可以看出这个网站是AES+RSA结合使用进行加密的。
AES+RSA:使用RSA秘钥生成工具生成一对公钥(A)和私钥(B),前端保留A,后端保留B。
前端发送数据时,先生成一串随机16位字符串作为AES的秘钥(C),然后使用A使用RSA算法对C进行加密,得到加密后的AES秘钥(D)。将要发送的数据(E)用C使用AES加密,得到密文(F)。将D和F一同发给后端进行处理。
后端处理数据时,先用B对D使用RSA进行解密得到C,用C对F使用AES进行解密得到E,处理后得到结果G,再用C对G进行AES加密得到H,将H返回给前端。
前端接收到H后用C进行解密,得到处理的结果G。
根据AES和RSA的配合流程来看,这里没有直接返回RSA公钥,而是根据摸和指数来生成RSA公钥然后加密AES私钥,用AES私钥去加密数据进行传输,但是从前面请求参数来看,跟我们平常看到的AES和RSA字符串不一样,显然还做了相关的转换,dataKey字段只有数字和小写字母,平常看到的加密数据还有大写字母、+、/等。文章来源:https://www.toymoban.com/news/detail-729028.html
- 7、这里有一个比较难的地方就是“new no.RSAKeyPair(e,“”,t,2048)”这个对象,这个对象去加密随机生成的AES密钥生成dataKey字段,这里我也是看了半天,打断点半天,也难以理解,因为编译后很多变量是单个字母,且你需要换算成你自己项目的语言,如JAVA、Python等,有时候是比较难的,这时候你可能会想我能不能反编译一下js文件,那你可以尝试一下,比如找一些在线的网站上传文件看看能不能反编译,希望你能成功😂
- 8、遇到难点无法继续下的时候怎么办呢?给大家提供一种思路,就是尝试直接拷贝它的js文件下来,然后在项目去执行它的函数,获取结果,我这里是使用JAVA、jdk1.8版本,由JavaScript引擎去执行js文件中的函数,根据上面的截图,我只需要执行Fp()函数即可拿到dataKey,和随机生成的AES私钥。
当然你如果直接执行拷贝下来的js文件大概率是失败,会报各种错误,例如jdk1.8不支持ES6语法,你需要先转化成ES5语法格式(es6转es5在线网站:https://babeljs.io/repl,需要勾选左侧下面的"FORCE ALL TRANSFORMS"),其次你需要把不需要用到的代码都删掉,只留加密部分的代码,可以根据入口函数一步步找到所有需要的变量和函数等,可以根据报错一步步处理,这也是个小挑战~
public static void main(String[] args) {
// 创建JavaScript引擎
ScriptEngineManager manager = new ScriptEngineManager();
ScriptEngine engine = manager.getEngineByName("js");
try {
// 加载JavaScript文件
engine.eval(new FileReader("C:\\Users\\win\\Desktop\\index2.js"));
// 执行JavaScript函数
Object result = engine.eval("Fp()");
// 这里是我习惯用serr打印测试日志,因为标红比较显眼
System.err.println("Function Result: " + JSONObject.toJSONString(result));
// 拿到Fp()函数返回的dataKey等数据
JSONObject object = JSONObject.parseObject(JSONObject.toJSONString(result));
// 要加密的数据
String content = "{\"appId\":\"xxxx\"}";
System.err.println("加密前的数据:" + content);
// 加密后的数据
String encryptAES = encryptAES(content, object.getString("key"), object.getString("iv"));
System.err.println("加密后的数据:" + encryptAES);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* AES加密
* @param plaintext 要加密的数据
* @param key
* @param iv
*/
public static String encryptAES(String plaintext, String key, String iv) {
try {
SecretKeySpec secretKey = new SecretKeySpec(key.getBytes(StandardCharsets.UTF_8), "AES");
IvParameterSpec ivParameterSpec = new IvParameterSpec(iv.getBytes(StandardCharsets.UTF_8));
Cipher cipher = Cipher.getInstance("AES/CBC/PKCS5Padding");
cipher.init(Cipher.ENCRYPT_MODE, secretKey, ivParameterSpec);
byte[] encryptedBytes = cipher.doFinal(plaintext.getBytes(StandardCharsets.UTF_8));
return bytesToHex(encryptedBytes).toUpperCase();
} catch (Exception e) {
log.error("AES加密异常,{}", e.getMessage());
return "";
}
}
private static String bytesToHex(byte[] bytes) {
StringBuilder result = new StringBuilder();
for (byte b : bytes) {
result.append(String.format("%02X", b));
}
return result.toString();
}
- 9、终极方案:无头浏览器!!!如果上面还不能解决你的问题,你可以尝试使用无头浏览器,模拟人工点击操作,当然这比接口慢很多,但你不需要考虑网站的加密和接口调用等等,按照人工操作的流程执行即可。注意,无头浏览器你可能需要考虑代理ip和请求头问题,尽可能模拟真实的操作,一直使用同一个ip和userAgent有可能会被检测到。
/**
* 获取浏览器驱动
*/
private WebDriver getDriver(Param pm) {
// 设置随机的设备 user-agent 和屏幕大小
Map<String, Object> mobileEmulation = new HashMap<>();
Map<String, Object> map = new HashMap<>();
Dimension randomScreenSize = getRandomScreenSize();
map.put("width", randomScreenSize.getWidth());
map.put("height", randomScreenSize.getHeight());
mobileEmulation.put("deviceMetrics", map);
if (pm != null && Func.isNotBlank(pm.getUserAgent())) {
// 设置UA
mobileEmulation.put("userAgent", pm.getUserAgent());
}
//谷歌浏览器设置
ChromeOptions options = new ChromeOptions();
// 隐藏浏览器、无头浏览器
options.addArguments("-headless");
options.setExperimentalOption("mobileEmulation", mobileEmulation);
// 打开F12
// options.addArguments("--auto-open-devtools-for-tabs");
// 启动无沙盒模式运行,以最高权限运行
options.addArguments("--no-sandbox");
// 不加载图片, 提升速度
options.addArguments("blink-settings=imagesEnabled=false");
options.addArguments("--disable-dev-shm-usage");
// 禁用gpu渲染
options.addArguments("--disable-gpu");
// 禁用阻止弹出窗口
options.addArguments("--disable-popup-blocking");
// 禁用扩展
options.addArguments("disable-extensions");
// 禁用默认浏览器检查
options.addArguments("no-default-browser-check");
// 忽略不信任证书
options.addArguments("–ignore-certificate-errors");
// 禁用自动化控制特性
options.addArguments("--disable-blink-features=AutomationControlled");
// 禁用通知
options.addArguments("--disable-notifications");
// 禁用信息栏
options.addArguments("--disable-infobars");
// 禁用日志记录
options.addArguments("--disable-logging");
LoggingPreferences logPrefs = new LoggingPreferences();
logPrefs.enable(LogType.PERFORMANCE, Level.ALL);
options.setCapability("goog:loggingPrefs", logPrefs);
// 禁用默认应用程序
options.addArguments("--disable-default-apps");
// 静音
options.addArguments("--mute-audio");
// 禁用自动化标志
options.setExperimentalOption("excludeSwitches", new String[]{"enable-automation"});
// 设置代理ip
if (pm != null && Func.isNotBlank(pm.getProxyIp())) {
String proxyAddress = pm.getProxyIp() + ":" + pm.getProxyPort();
Proxy proxy = new Proxy();
proxy.setHttpProxy(proxyAddress);
proxy.setSslProxy(proxyAddress);
options.setProxy(proxy);
}
return new ChromeDriver(options);
}
谷歌浏览器驱动路径:https://googlechromelabs.github.io/chrome-for-testing/#stable文章来源地址https://www.toymoban.com/news/detail-729028.html
public void handle(Param pm) {
WebDriver driver = null;
try {
if (Func.isBlank(pm.getUserAgent())) {
// 这个工具类只是随机生成userAgent的工具类
pm.setUserAgent(UserAgentUtil.getUserAgent());
}
// 谷歌浏览器驱动路径,注意驱动版本问题
System.setProperty("webdriver.chrome.driver", "F:/chromedriver-win64/chromedriver.exe");
driver = getDriver(pm);
// driver.manage().window().maximize();
// 进入页面
driver.get("https://xxx");
JavascriptExecutor js = (JavascriptExecutor) driver;
//添加cookie
if (pm.getCookies() != null && pm.getCookies().size() > 0) {
setCookie(js, pm.getCookies());
}
// 隐式等待
driver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS);
// 其他相关处理代码
...
} catch (Exception e) {
e.printStackTrace();
} finally {
if (driver != null) {
driver.quit();
}
}
}
到了这里,关于关于工作中爬取网站的一些思路记录的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!