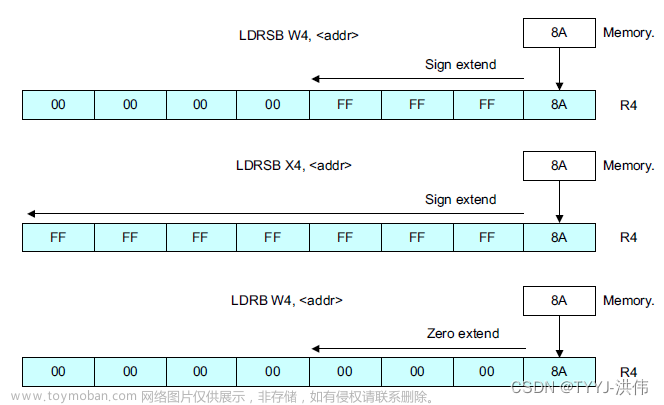
除了基础的 LDx 指令,还有 LDP、LDR 这些指令,我们也需要关注。
1 LDNP (SIMD&FP)
加载 SIMD&FP 寄存器对,带有非临时提示。该指令从内存加载一对 SIMD&FP 寄存器,向内存系统发出访问是非临时的提示。用于加载的地址是根据基址寄存器值和可选的立即偏移量计算得出的。

32-bit (opc == 00)
LDNP <St1>, <St2>, [<Xn|SP>{, #<imm>}]
64-bit (opc == 01)
LDNP <Dt1>, <Dt2>, [<Xn|SP>{, #<imm>}]
128-bit (opc == 10)
LDNP <Qt1>, <Qt2>, [<Xn|SP>{, #<imm>}]
<Dt1> 是要传输的第一个 SIMD&FP 寄存器的 64 位名称,编码在“Rt”字段中。
<Dt2> 是要传输的第二个 SIMD&FP 寄存器的 64 位名称,编码在“Rt2”字段中。文章来源:https://www.toymoban.com/news/detail-729176.html
<Qt1> 是要传输的第一个 SIMD&am文章来源地址https://www.toymoban.com/news/detail-729176.html
到了这里,关于【ARMv8 SIMD和浮点指令编程】NEON 加载指令——如何将数据从内存搬到寄存器(其它指令)?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!