微服务技术栈导学
微服务实现流程:

所有要学的技术:

分层次教学:

具体分层:

实用篇---第一天

一、认识微服务
单体架构
将业务所有功能集中在一个项目中开发,打成一个包部署
优点:架构简单、部署成本低
缺点:耦合度高

分布式架构
根据业务功能对系统进行查分,每个业务模块作为独立项目开发,称为一个服务
优点:降低服务耦合、有利于服务升级拓展

服务治理
分布式架构需要考虑的问题:
服务拆分粒度如何?
服务集群地址如何维护?
服务之间如何实现远程调用?
服务健康状态如何感知?
微服务
微服务是一种经过良好架构设计的分布式架构方案,微服务架构特征如下:
单一职责:微服务拆分粒度更小,每一个服务都对应唯一的业务能力,做到单一职责,避免重复业务开发
面向服务:微服务对外暴露业务接口
自治:团队独立、技术独立、数据独立、部署独立
隔离性强:服务调用做好隔离、容错、降级,避免出现级联问题

微服务技术对比
微服务这种方案需要技术框架来落地,全球的互联网公司都在积极尝试自己的微服务落地技术。在国内最知名的就是SpringCloud和阿里巴巴的Dubbo

企业场景

SpringCloud
SpingCloud是国内目前使用最广泛的微服务框架
SpringCloud集成了各种微服务功能组件,并基于SpringBoot实现饿了这些组件的自动装配,从而提供了良好的开箱即用的体验

SpringBoot和SpringCloud版本兼容如下:

二、服务拆分及远程调用
服务拆分
1.不同微服务,不要重复开发相同的业务
2.微服务数据独立,不要访问其他微服务的数据库
3.微服务可以将自己的业务暴露为接口,供其他微服务调用

远程调用
要想实现跨服务的远程调用,其实就是发送一次http请求
1.注册RestTemplate

2.调用api

三、Eureka
提供者与消费者
服务提供者:一次业务中,被其他微服务调用的服务(提供接口给其他服务)
服务消费者:一次业务中,调用其他微服务的服务(调用其他微服务提供的接口)
服务A调用服务B,服务B调用服务C,那么服务B是什么角色呢?
既是服务提供者,有时候服务消费者
Eureka原理分析
消费者该如何获取服务提供者的具体信息呢?
服务提供者启动时向eureka注册自己的信息
eureka保存这些信息
消费者根据服务名向eureka拉取提供者信息
如果有多个服务提供者,消费者该如何选择?
服务消费者利用负载均衡算法,从服务列表中挑选一个
消费者如何感知服务提供者健康状态?
服务提供者会每隔30s向EurekaServer发送心跳请求,报告健康状态
eureka会更新记录服务列表信息,心跳不正常会被踢除
消费者就可以拉取到最新的信息

搭建eureka服务
任务:

搭建EurekaServer:

注册user-service
服务注册两步:
1.引入eureka-client依赖
2.在application.yml中配置eureka地址

为了能够更方便的模拟多个服务请求,可以编辑配置
-D代表参数
server.port就是配置端口

此时可以看到USERSERVICE有两个

服务拉取
服务拉取是基于服务名称获取服务列表,然后对服务列表做负载均衡

四、 Ribbon
负载均衡原理

负载均衡策略
Ribbon的负载均衡规则是一个叫做IRule的接口来定义的,每一个子接口都是一种规则

策略详解:

通过定义IRule实现可以修改负载均衡规则:
方式①:在order-service中的OrderApplication类中,定义一个新的IRule
注意:这是全局配置
@Bean
public IRule randomRule(){
return new RandomRule();
}方式②:在order-service中的application.yml文件中,添加新的配置也可以修改规则
注意:这是局部配置
userservice:
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule饥饿加载
Ribbon默认采用懒加载,即第一次访问时才会创建LoadBalanceClient,请求时间会很长。
而饥饿加载则会在项目启动时创建,降低第一次访问的耗时,通过下面的配置开启饥饿加载:
ribbon:
eager-load:
enabled: true
clients: userservice总结:

五、Nacos
认识并安装Nacos
Nacos是阿里巴巴的产品,现在是SpringCloud中的一个组件,相比Eureka功能更加丰富,在国内受欢迎程度更高。
在nacos解压目录的bin目录下进入命令窗口,输入

进入nacos页面,初始用户名和密码都是nacos

nacos快速入门
服务注册到nacos:


nacos服务分级存储模型
①一级是服务,例如userservice
②二级是集群,例如杭州或上海
③三级是实例,例如杭州机房的某台部署了userservice的服务器

服务跨集群调用问题:
服务调用尽可能选择本地集群的服务,跨集群调用延迟较高
本地集群不可访问时,再去访问其他集群
服务集群属性配置:
修改application.yml文件,添加spring.cloud.nacos.discovery

NacosRule 负载均衡
根据集群负载均衡:

NacosRule负载均衡策略:
①优先选择同集群服务实例列表
②本地集群找不到提供者,才会去其它集群寻找,并且会报警告
③确定了可用实例列表后,再采用随机负载均衡挑选实例
根据权重负载均衡
在实际部署中会出现这样的场景:
服务器设备性能有差异,部分实例所在机器性能较好,另一些较差,我们希望性能好的机器承担更多的用户请求
Nacos提供了权重配置来控制访问频率,权重越大则访问频率越高

环境隔离---namespace
Nacos中服务存储和数据存储的最外层都是一个名为namespace的东西,用来做最外层隔离

新建命名空间:

创建好命名空间以后,添加namespace配置

Nacos环境隔离:
①namespace用来做环境隔离
②每个namespace都有唯一的id
③不同的namespace下的服务不可见
nacos注册中心细节分析

临时实例和非临时实例:
服务器注册到Nacos时,可以选择注册为临时或非临时实例,通过下面的配置来设置:

Nacos与eureka的共同点:
①都支持服务注册和服务拉取
②都支持服务提供者心跳方式做健康检测
Nacos和Eureka的区别:
①Nacos支持服务端主动检测提供者状态:临时实例采用心跳模式,非临时实例采用主动监测模式
②临时实例心跳不正常会被踢除,非临时实例则不会被剔除
③Nacos支持服务列表变更的消息推送模式,服务列表更新更及时
④Nacos集群默认采用AP方式,当集群中存在非临时实例时,采用CP模式,Eureka采用AP方式
实用篇---第二天

一、Nacos配置管理
Nacos实现配置管理

配置的统一管理:
Data ID命名:服务名称-profile.后缀名
Group:分组,默认即可
配置格式:目前支持yaml和properties
配置内容:填写将来可能会改变的配置

微服务配置拉取

进行微服务配置拉取可以实现:

步骤:

注意:如果你的userservice配置在dev命名空间下,请标明
spring:
application:
name: userservice
profiles:
active: dev
cloud:
nacos:
server-addr: localhost:8848
config:
file-extension: yaml #文件后缀名
namespace: 0482f978-fc0d-4030-948c-5a91488ff1d5
总结:
将配置交给Nacos管理的步骤
①在Nacos中添加配置文件
②在微服务中引入nacos的config依赖
③在为服务中添加bootstrap.yml,配置nacos地址、当前环境、服务名称、文件后缀名。这些决定了程序启动时去nacos读取哪个文件
配置热更新
Nacos中的配置文件变更后,微服务无需重启就可以感知,不过需要通过下面两种配置实现:
方式一:在@Value注入的变量所在类上添加注解@RefreshScope

方式二:使用@ConfigurationProperties注解
@Data
@ConfigurationProperties(prefix="pattern")
@Component
public class PatternProperties {
private String dateformat;
}在Controller中不再需要@Value注解,直接自动注入PatternProperties类即可
@Slf4j
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private PatternProperties properties;
@GetMapping("now")
public String now(){
return LocalDateTime.now().format(DateTimeFormatter.ofPattern(properties.getDateformat()));
}
}总结:

多环境配置共享
微服务启动时会从nacos读取多个配置文件:
[spring.application.name]-[spring.profiles.active].yaml,例如:userservice-dev.yaml
[spring.application.name].yaml,例如:userservice.yaml
无论profile如何变化,[spring.application.name].yaml这个文件一定会加载,因此多环境共享配置可以写入这个文件

多种配置的优先级:
服务名-profile.yaml > 服务名称.yaml > 本地配置

nacos集群搭建


搭建集群基本步骤:
搭建数据库,初始化数据库表结构
下载nacos安装包
配置nacos
启动nacos集群
nginx反向代理
mysql脚本:
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = config_info */
/******************************************/
CREATE TABLE `config_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`data_id` varchar(255) NOT NULL COMMENT 'data_id',
`group_id` varchar(255) DEFAULT NULL,
`content` longtext NOT NULL COMMENT 'content',
`md5` varchar(32) DEFAULT NULL COMMENT 'md5',
`gmt_create` datetime NOT NULL DEFAULT '2010-05-05 00:00:00' COMMENT '创建时间',
`gmt_modified` datetime NOT NULL DEFAULT '2010-05-05 00:00:00' COMMENT '修改时间',
`src_user` text COMMENT 'source user',
`src_ip` varchar(20) DEFAULT NULL COMMENT 'source ip',
`app_name` varchar(128) DEFAULT NULL,
`tenant_id` varchar(128) DEFAULT '' COMMENT '租户字段',
`c_desc` varchar(256) DEFAULT NULL,
`c_use` varchar(64) DEFAULT NULL,
`effect` varchar(64) DEFAULT NULL,
`type` varchar(64) DEFAULT NULL,
`c_schema` text,
PRIMARY KEY (`id`),
UNIQUE KEY `uk_configinfo_datagrouptenant` (`data_id`,`group_id`,`tenant_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='config_info';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = config_info_aggr */
/******************************************/
CREATE TABLE `config_info_aggr` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`data_id` varchar(255) NOT NULL COMMENT 'data_id',
`group_id` varchar(255) NOT NULL COMMENT 'group_id',
`datum_id` varchar(255) NOT NULL COMMENT 'datum_id',
`content` longtext NOT NULL COMMENT '内容',
`gmt_modified` datetime NOT NULL COMMENT '修改时间',
`app_name` varchar(128) DEFAULT NULL,
`tenant_id` varchar(128) DEFAULT '' COMMENT '租户字段',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_configinfoaggr_datagrouptenantdatum` (`data_id`,`group_id`,`tenant_id`,`datum_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='增加租户字段';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = config_info_beta */
/******************************************/
CREATE TABLE `config_info_beta` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`data_id` varchar(255) NOT NULL COMMENT 'data_id',
`group_id` varchar(128) NOT NULL COMMENT 'group_id',
`app_name` varchar(128) DEFAULT NULL COMMENT 'app_name',
`content` longtext NOT NULL COMMENT 'content',
`beta_ips` varchar(1024) DEFAULT NULL COMMENT 'betaIps',
`md5` varchar(32) DEFAULT NULL COMMENT 'md5',
`gmt_create` datetime NOT NULL DEFAULT '2010-05-05 00:00:00' COMMENT '创建时间',
`gmt_modified` datetime NOT NULL DEFAULT '2010-05-05 00:00:00' COMMENT '修改时间',
`src_user` text COMMENT 'source user',
`src_ip` varchar(20) DEFAULT NULL COMMENT 'source ip',
`tenant_id` varchar(128) DEFAULT '' COMMENT '租户字段',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_configinfobeta_datagrouptenant` (`data_id`,`group_id`,`tenant_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='config_info_beta';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = config_info_tag */
/******************************************/
CREATE TABLE `config_info_tag` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`data_id` varchar(255) NOT NULL COMMENT 'data_id',
`group_id` varchar(128) NOT NULL COMMENT 'group_id',
`tenant_id` varchar(128) DEFAULT '' COMMENT 'tenant_id',
`tag_id` varchar(128) NOT NULL COMMENT 'tag_id',
`app_name` varchar(128) DEFAULT NULL COMMENT 'app_name',
`content` longtext NOT NULL COMMENT 'content',
`md5` varchar(32) DEFAULT NULL COMMENT 'md5',
`gmt_create` datetime NOT NULL DEFAULT '2010-05-05 00:00:00' COMMENT '创建时间',
`gmt_modified` datetime NOT NULL DEFAULT '2010-05-05 00:00:00' COMMENT '修改时间',
`src_user` text COMMENT 'source user',
`src_ip` varchar(20) DEFAULT NULL COMMENT 'source ip',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_configinfotag_datagrouptenanttag` (`data_id`,`group_id`,`tenant_id`,`tag_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='config_info_tag';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = config_tags_relation */
/******************************************/
CREATE TABLE `config_tags_relation` (
`id` bigint(20) NOT NULL COMMENT 'id',
`tag_name` varchar(128) NOT NULL COMMENT 'tag_name',
`tag_type` varchar(64) DEFAULT NULL COMMENT 'tag_type',
`data_id` varchar(255) NOT NULL COMMENT 'data_id',
`group_id` varchar(128) NOT NULL COMMENT 'group_id',
`tenant_id` varchar(128) DEFAULT '' COMMENT 'tenant_id',
`nid` bigint(20) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`nid`),
UNIQUE KEY `uk_configtagrelation_configidtag` (`id`,`tag_name`,`tag_type`),
KEY `idx_tenant_id` (`tenant_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='config_tag_relation';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = group_capacity */
/******************************************/
CREATE TABLE `group_capacity` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`group_id` varchar(128) NOT NULL DEFAULT '' COMMENT 'Group ID,空字符表示整个集群',
`quota` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '配额,0表示使用默认值',
`usage` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '使用量',
`max_size` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '单个配置大小上限,单位为字节,0表示使用默认值',
`max_aggr_count` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '聚合子配置最大个数,,0表示使用默认值',
`max_aggr_size` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '单个聚合数据的子配置大小上限,单位为字节,0表示使用默认值',
`max_history_count` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '最大变更历史数量',
`gmt_create` datetime NOT NULL DEFAULT '2010-05-05 00:00:00' COMMENT '创建时间',
`gmt_modified` datetime NOT NULL DEFAULT '2010-05-05 00:00:00' COMMENT '修改时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_group_id` (`group_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='集群、各Group容量信息表';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = his_config_info */
/******************************************/
CREATE TABLE `his_config_info` (
`id` bigint(64) unsigned NOT NULL,
`nid` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`data_id` varchar(255) NOT NULL,
`group_id` varchar(128) NOT NULL,
`app_name` varchar(128) DEFAULT NULL COMMENT 'app_name',
`content` longtext NOT NULL,
`md5` varchar(32) DEFAULT NULL,
`gmt_create` datetime NOT NULL DEFAULT '2010-05-05 00:00:00',
`gmt_modified` datetime NOT NULL DEFAULT '2010-05-05 00:00:00',
`src_user` text,
`src_ip` varchar(20) DEFAULT NULL,
`op_type` char(10) DEFAULT NULL,
`tenant_id` varchar(128) DEFAULT '' COMMENT '租户字段',
PRIMARY KEY (`nid`),
KEY `idx_gmt_create` (`gmt_create`),
KEY `idx_gmt_modified` (`gmt_modified`),
KEY `idx_did` (`data_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='多租户改造';
/******************************************/
/* 数据库全名 = nacos_config */
/* 表名称 = tenant_capacity */
/******************************************/
CREATE TABLE `tenant_capacity` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`tenant_id` varchar(128) NOT NULL DEFAULT '' COMMENT 'Tenant ID',
`quota` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '配额,0表示使用默认值',
`usage` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '使用量',
`max_size` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '单个配置大小上限,单位为字节,0表示使用默认值',
`max_aggr_count` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '聚合子配置最大个数',
`max_aggr_size` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '单个聚合数据的子配置大小上限,单位为字节,0表示使用默认值',
`max_history_count` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '最大变更历史数量',
`gmt_create` datetime NOT NULL DEFAULT '2010-05-05 00:00:00' COMMENT '创建时间',
`gmt_modified` datetime NOT NULL DEFAULT '2010-05-05 00:00:00' COMMENT '修改时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_tenant_id` (`tenant_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='租户容量信息表';
CREATE TABLE `tenant_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`kp` varchar(128) NOT NULL COMMENT 'kp',
`tenant_id` varchar(128) default '' COMMENT 'tenant_id',
`tenant_name` varchar(128) default '' COMMENT 'tenant_name',
`tenant_desc` varchar(256) DEFAULT NULL COMMENT 'tenant_desc',
`create_source` varchar(32) DEFAULT NULL COMMENT 'create_source',
`gmt_create` bigint(20) NOT NULL COMMENT '创建时间',
`gmt_modified` bigint(20) NOT NULL COMMENT '修改时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_tenant_info_kptenantid` (`kp`,`tenant_id`),
KEY `idx_tenant_id` (`tenant_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='tenant_info';
CREATE TABLE users (
username varchar(50) NOT NULL PRIMARY KEY,
password varchar(500) NOT NULL,
enabled boolean NOT NULL
);
CREATE TABLE roles (
username varchar(50) NOT NULL,
role varchar(50) NOT NULL,
constraint uk_username_role UNIQUE (username,role)
);
CREATE TABLE permissions (
role varchar(50) NOT NULL,
resource varchar(512) NOT NULL,
action varchar(8) NOT NULL,
constraint uk_role_permission UNIQUE (role,resource,action)
);
INSERT INTO users (username, password, enabled) VALUES ('nacos', '$2a$10$EuWPZHzz32dJN7jexM34MOeYirDdFAZm2kuWj7VEOJhhZkDrxfvUu', TRUE);
INSERT INTO roles (username, role) VALUES ('nacos', 'ROLE_ADMIN');
进入nacos的conf目录,修改配置文件cluster.conf.example,重名名为cluster.conf

配置application.properties
打开注释,告诉nacos我们使用的是mysql集群
需要打开的注释:
spring.datasource.platform=mysql
db.num=1
DB:db.url.0=jdbc:mysql://127.0.0.1:3306/nacos?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC
db.user.0=nacos
db.password.0=nacos将配置好的文件复制三份:

将每份文件的server.port修改为之前配好的三个端口之一
比如:server.port=8845
启动:
找到bin目录,打开命令行窗口,输入命令:startup.cmd
修改config/nginx.conf文件,将下面的配置黏贴到http内部:
upstream nacos-cluster{
server 127.0.0.1:8845;
server 127.0.0.1:8846;
server 127.0.0.1:8847;
}
server{
listen 80;
server_name localhost;
location /nacos {
proxy_pass http://nacos-cluster;
}
}在nginx安装目录下打开命令符提示窗口,输入:
start nginx.exe
配置application.yaml或者bootstrap.yaml
spring:
cloud:
nacos:
server-addr: localhost:80二、Feign远程调用
初识http客户端Feign
restTemplate方式调用存在的问题

Feign是一个声明式的http客户端,其作用就是帮助我们优雅地实现http请求的发送,解决上面的问题
使用Feign的步骤:


注:如果Maven导入openfeign失败,可以加上版本号
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
<version>2.1.1.RELEASE</version>
</dependency>实现远程调用:
@RestController
@RequestMapping("order")
public class OrderController {
@Autowired
private OrderService orderService;
@Autowired
private UserClient userClient;
@GetMapping("{orderId}")
public Order queryOrderByUserId(@PathVariable("orderId") Long orderId) {
// 根据id查询订单并返回
Order order=orderService.queryOrderById(orderId);
User user = userClient.findById(order.getUserId());
order.setUser(user);
return order;
}
}
总结:
Feign的使用步骤
①引入依赖
②添加@EnableFeignClients注解
③编写FeignClient接口
④使用FeignClient中定义的方法代替RestTemplate
自定义Feign的配置

配置Feign日志有两种方式:


Feign的日志配置总结:
1.方式一是配置文件,feign.client.config.xxx.loggerLevel
①如果xxx是default则代表全局
②如果xxx是服务名称,例如userservice,则代表某服务
2.方式二是java代码配置Logger.Level这个Bean
①如果在@EnableFeignClients注解声明则代表全局
②如果在@FeignClient注解中声明则代表某服务
Feign性能优化
Feign底层的客户端实现:
URLConnection:默认实现,不支持连接池
Apache HttpClient:支持连接池
OKHttp:支持连接池
因此优化Feign的性能主要包括:
①使用连接池代替默认的URLConnection
②日志级别,最好用basic或none
Feign添加HttpClient的支持:

Feign的优化总结:
1.日志级别尽量用basic
2.使用HttpClient或OKHttp代替URLConnection
①引入feign-httpClient依赖
②配置文件开启httpClient功能,设置连接池参数
Feign的最佳实践
方式一(继承):给消费者的FeignClient和提供者的controller定义统一的父接口作为标准

方式二(抽取):将FeignClient抽取为独立模块,并且把接口有关的pojo、默认的Feign配置都放到这个模块中,提供给所有消费者使用

Feign的最佳实践总结:
①让controller和FeignClient继承同一个接口
②将FeignClient、POJO、Feign的默认配置都定义到一个项目中,供所有消费者使用
Feign最佳实践的实现
步骤:
1.首先创建一个module,命名为feign-api,然后引入feign的starter依赖
2.将order-service中编写的UserClient、User、DefaultFeignConfiguration都复制到feign-api项目中
3.在order-service中引入feign-api的依赖
4.修改order-service中所有与上诉三个组件有关的import部分,改成导入feign-api中的包

如上图,当定义的FeignClient不在SpringBootApplication的扫描包范围时,这些FeignClient无法使用。有两种方式解决:

总结:

三、统一网关Gateway
网关作用介绍
为什么需要网关?

网关的技术实现:
在SpringCloud中网关的实现有两种:
gateway
zuul
Zuul是基于Servlet的实现,属于阻塞式编程。而SpringCloudGateway则是基于Spring5中提供的WebFlux,属于响应式编程的实现,具备更好的性能
搭建网关服务
步骤:
1.创建新的module,引入SpringCloudGateway的依赖和nacos的服务发现依赖:
<dependencies>
<!--nacos服务注册发现依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<!--网关gateway依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
</dependencies>2.编写路由配置及nacos地址
server:
port: 10010 #网关端口
spring:
application:
name: gateway
cloud:
nacos:
server-addr: localhost:8848 #nacos地址
gateway:
routes: #网关路由配置
- id: user-service #路由id,自定义,只要唯一即可
uri: lb://userservice #路由的目标地址lb(loadBalance)就是负载均衡,后面跟服务名称
predicates: #路由断言,也就是判断请求是否符合路由规则的条件
- Path=/user/** #这个是按照路径匹配,只要以/user/开头就符合规则
- id: order-service
uri: lb://orderservice
predicates:
- Path=/order/**网关工作流程图:

总结:
网关搭建步骤:
1.创建项目,引入nacos服务发现和gateway依赖
2.配置application.yml,包括服务基本信息、nacos地址、路由
路由配置包括:
1.路由id:路由的唯一标识
2.路由目标(uri):路由的目标地址,http代表固定地址,lb代表根据服务名负载均衡
3.路由断言(predicates):判断路由的规则
4.路由过滤器(filters):对请求或响应做处理
路由断言工厂 Route Predicate Factory
网关路由可以配置的内容包括:
路由id:路由唯一标识
uri:路由目的地,支持lb和http两种
predicates:路由断言,判断请求是否符合要求,符合则转发到路由目的地
filters:路由过滤器,处理请求或响应
我们在配置文件中写的断言规则只是字符串,这些字符串会被Predicate Factory读取并处理,转变为路由判断条件
例如Path=/user/** 是按照路径匹配,这个规则是有org.springframework.cloud.gateway.handler.predicate.PathRoutePredicateFactory
像这样的断言工厂spring还有十几个:

以After为例,配置了未来的时间,则访问失败:
- After=2031-04-13T15:14:47.433+08:00[Asia/Shanghai]

路由过滤器 GatewayFilter
GatewayFilter是网关中提供的一种过滤器,可以对进入网关的请求和微服务返回的响应做处理

Spring提供了31种不同的路由过滤器工厂,例如:

案例:给所有进入userservicce的请求添加一个请求头:Truth=Itcast is freaking awesome!
实现方式:在gateway中修改application.yml文件,给userservice的路由添加过滤器:
filters:
- AddRequestHeader=Truth,Itcast is freaking awesome!验证方式:修改UserController,接收请求头Truth
@GetMapping("/{id}")
public User queryById(@PathVariable("id") Long id,@RequestHeader(value = "Truth",required = false)String truth) {
System.out.println("truth:"+truth);
return userService.queryById(id);
}打印成功:

默认过滤器:
如果要对所有的路由都生效,则可以将过滤器工厂写到default下

总结:
过滤器的作用是什么?
①对路由的请求或响应做加工处理,比如添加请求头
②配置在路由下的过滤器只对当前路由的请求生效
defaultFilters的作用是什么?
①对所有路由都生效的过滤器
全局过滤器 GlobalFilter
全局过滤器的作用也是处理一切进入网关的请求和微服务响应,与GatewayFilter的作用一样
区别在于GatewayFilter通过配置定义,处理逻辑是固定的。而GlobalFilter的逻辑需要自己写代码实现
定义方式是实现GlobalFilter接口:

定义全局过滤器,拦截并判断用户身份:
需求:定义全局过滤器,拦截请求、判断请求的参数是否满足下面条件:
参数中是否有authorization
authorization参数值是否有admin
如果同时满足则放行,否则拦截
@Component
@Order(-1) //指定过滤器的顺序
public class AuthorizeFilter implements GlobalFilter {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain){
//1.获取请求参数
ServerHttpRequest request = exchange.getRequest();
MultiValueMap<String, String> params = request.getQueryParams();
//2.获取参数中的authorization参数
String auth=params.getFirst("authorization");
//3.判断参数值是否等于admin
if("admin".equals(auth)){
//4.是,放行
return chain.filter(exchange);
}
//5.否,拦截
//5.1 设置状态码
exchange.getResponse().setStatusCode(HttpStatus.UNAUTHORIZED); //401代表未登录
//5.2 拦截请求
return exchange.getResponse().setComplete();
}
}总结:
全局过滤器的作用是什么?
对所有路由都生效的过滤器,并且可以自定义处理逻辑
实现全局过滤器的步骤是什么?
①实现GlobalFilter接口
②添加@Order注解或实现Ordered接口
③编写处理逻辑
过滤器执行顺序
请求进入网关会碰到三类过滤器:当前路由的过滤器、DefaultFilter、GlobalFilter
请求路由后,会将当前路由过滤器和DefaultFilter、GlobalFilter合并到一个过滤器链(集合)中,排序后依次执行每个过滤器

默认过滤器和路由过滤器很相似,他们都是GatewayFilter
而对于全局过滤器,虽然他是GlobalFilter,但是通过适配器模式,可以将他转为GatewayFilter
每一个过滤器必须指定一个int类型的order值,order值越小,优先级越高,执行顺序越靠前
GlobalFilter通过实现Ordered接口,或者添加@Order注解来指定order值,由我们自己指定
路由过滤器和defaultFilter的order由Spring指定,默认是按照声明顺序从1递增
当过滤器的order值一样时,会按照defaultFilter>路由过滤器>GlobalFilter的顺序执行

总结:

网关的cors跨域配置
跨域:域名不一致就是跨域
主要包括:

跨域问题:浏览器禁止请求的发起者与服务端发生跨域ajax请求,请求被浏览器拦截的问题
解决方案:CORS
网关处理跨域采用的同样是CORS方案,并且只需要简单的配置即可实现:

实用篇---第三天

一、初识Docker
什么是Docker
项目部署的问题:

Docker是如何解决依赖的兼容问题呢?

linux操作系统结构:

Ubuntu和CentOS都是基于Linux内核,只是系统应用不同,提供的函数库有差异,所以程序不能跨系统运行
Docker如何解决不同系统环境的问题?
==>Docker打包好的程序可以运行在任何linux系统上

总结:
Docker如何解决大型项目依赖关系复杂、不同组件依赖的兼容性问题?
Docker允许开发中将应用、依赖、函数库、配置一起打包,形成可移植镜像
Docker应用运行在容器中,使用沙箱机制,相互隔离
Docker如何解决开发、测试、生产环境有差异的问题?
Docker镜像中包含完整运行环境,包括系统函数库、仅依赖系统的linux内核,因此可以在任意的linux操作系统上运行
Docker是一个快速交付应用、运行应用的技术

Docker与虚拟机的差别

Docker与虚拟机性能的差别:

Docker和虚拟机的差异:
docker是一个系统进程;虚拟机是在操作系统中的操作系统
docker体积小、启动速度快、性能好;虚拟机体积大、启动速度慢、性能一般
Docker架构
镜像(Image):Docker将应用程序及其所需要的依赖、函数库、环境、配置等文件打包在一起,称为镜像
容器(Container):镜像中的应用程序运行后形成的进程就是容器,只是Docker会给容器做隔离,对外不可见

DockerHub:DockerHub是一个Docker镜像的托管平台,这样的平台称为Docker Registry
docker架构:

总结:

安装Docker
Docker分为CE和EE两大版本,CE是社区版免费,EE是企业版收费
Docker CE支持64为版本CentOS 7,并且要求内核版本不低于3.10,CentOS 7满足最低内核要求,所以我们在CentOS 7 上安装Docker
如果之前安装过旧版本的Docker,可以使用下面的命令卸载:

开始正式安装Docker
第一步:虚拟机联网,安装yum工具

第二步:更新本地镜像源

上面的命令要分开敲,如下:

第三步:安装docker-ce(社区免费版)

至此,docker安装完毕
启动docker
由于Docker应用需要用到这种端口,逐一去修改防火墙设置非常麻烦,因此建议大家直接关闭防火墙。
启动docker前,一定要关闭防火墙!!!

启动docker:
命令:systemctl start docker
启动后,可以用docker -v来查看docker的版本,如果能够查到,则启动docker成功

配置镜像:
docker官方镜像仓库网速较差,我们需要设置国内镜像

具体命令分步可以看我的代码:

二、Docker的基本操作
镜像操作
镜像名称一般分为两部分:
[repository]:[tag]
tag是版本号,在没有指定tag时,默认是latest,代表最新版本的镜像

镜像操作命令:

dock
案例一:从DockerHub中拉去一个nginx镜像并查看

拉取镜像成功后,可以通过docker images查看

案例二:利用docker save将nginx镜像导出磁盘,然后再通过load加载回来
步骤一:利用dockr xx --help命令查看docker save和docker load的语法

步骤二:使用docker tag 创建新镜像mynginx 1.0
步骤三:使用docker save导出镜像到磁盘

通过load加载回来:

总结:

镜像命令练习

我的练习代码如下:
[root@Soft soft]# docker pull redis:alpine3.17
[root@Soft soft]# docker save -o redis.tar redis:alpine3.17
[root@Soft soft]# docker rmi redis:alpine3.17
[root@Soft soft]# docker load -i redis.tar
最终操作结果:

容器相关命令

向浏览器
容器命令案例1
创建并运行一个nginx容器
去docker hub查看nginx的容器运行命令
docker run --name containerName -p 80:80 -d nginx
命令解读:
docker run:创建并运行一个容器
--name:给容器起一个名字,比如叫做mn
-p:将宿主端口与容器端口映射,冒号左侧是宿主机端口,右侧是容器端口
注意:宿主机的端口只要没被占用,可以任意指定;但是容器内的端口一般取决于运行的程序本身,一般是固定的,比如nginx一般监听的都是80端口
-d:后台运行容器
nginx:镜像名称,例如nginx,不写tag代表最新nginx

容器创建成功后,会返回一个字符串。这是容器的全局唯一标识,代表容器创建成功

查看容器运行状态:

浏览器访问:
注明,可以用ifconfig查看虚拟机的ip地址

向浏览器输入虚拟机的ip地址,查看到下面的页面则说明nginx部署成功:

查看日志:-f选项可以持续跟踪日志,而无需每次手动查询日志
[root@Soft soft]# docker logs -f mn
总结:

容器命令案例2
进入nginx容器,修改HTML文件内容,添加“传智教育欢迎您”
步骤一:进入容器。
进入我们刚刚创建的nginx容器的命令为:
docker exec -it mn bash
命令解读:
docker exec:进入容器命令,执行一个命令
-it:给当前进入的容器创建一个标准输入、输出终端,允许我们与容器交互
mn:要进入的容器的名称
bash:进入容器后执行的命令,bash是一个linux终端交互命令
进入nginx容器内部,其实就是一个阉割版的linux,可以使用linux的命令

步骤二:进入nginx的HTML所在目录 /usr/share/nginx/html
步骤三:修改index.html的内容

退出容器的命令:exit
docker ps默认只能查看运行中的容器,可以加-a参数查看所有容器

当容器处于运行状态时,不能直接通过docker rm containerName删除,需要先停止容器运行才行。为了方便,可以直接使用-f参数,强制删除运行时的容器

总结:
查看容器状态:
docker ps
添加-a参数查看所有状态的容器
删除容器:
docker rm
不能删除运行中的容器,除非添加-f参数
进入容器:
命令是docker exec -it [容器名] [要执行的命令]
exec命令可以进入容器修改文件,但是在容器内修改文件是不推荐的
容器命令练习
创建并运行一个redis容器,并且支持数据持久化

进入redis容器,并执行redis-cli客户端命令,存入num=555

数据卷命令
容器与数据耦合的问题:

数据卷(volume)是一个虚拟目录,指向宿主机文件系统中的某个目录

操作数据卷:
数据卷操作的基本语法如下:
docker volume [COMMAND]
docker volume 命令是数据卷操作,但根据命令后跟随的command来确定下一步的操作:
create 创建一个volume
inspect 显示一个或多个volume的信息
ls 列出所有的volume
prune 删除未使用的volume
rm 删除一个或多个指定的volume
官方释义:

案例:创建一个数据卷,并查看数据卷在宿主机的目录位置
①创建数据卷

②查看所有数据

③查看数据卷详细信息卷

删除未使用的数据卷:

移除特定的数据卷

总结:
数据卷的作用:
将容器与数据分离,解耦合,方便操作容器内的数据,保证数据安全
数据卷操作:
docker volume create
docker volume ls
docker volume inspect
docker volume rm
docker volume prune
挂载数据卷
我们在创建容器时,可以通过-v参数来挂载一个数据卷到某个容器目录

案例:创建一个nginx容器,修改容器内的html目录内的index.html内容
需求说明:上个案例中,我们进入nginx容器内部,已经知道nginx的html目录所在位置是 /usr/share/nginx/html,我们需要把这个目录挂载到html这个数据卷上,方便操作其中的内容
提示:运行容器时使用-v参数挂载数据卷
步骤:
①创建容器并挂载数据卷到容器内的HTML目录

②进入html数据卷所在位置,并修改HTML内容

运行结果:

如果做数据卷挂载,数据卷不存在,docker会自动创建需要的数据卷

总结:
数据卷挂载方式:
-v volumeName:/targetContainerPath
如果容器运行时volume不存在,会被自动创建出来
数据卷挂载案例
创建并运行一个MySQL容器,将宿主机目录直接挂载到容器上
目录挂载与数据卷挂载语法相似:
-v [宿主机目录]:[容器内目录]
-v [宿主机文件]:[容器内文件]

步骤1:

步骤2/3:

步骤4:

两种数据卷挂载方式的对比:

总结:

三、Dockerfile自定义镜像
镜像结构
镜像是将应用程序及其需要的系统函数库、环境、配置、依赖打包而成

总结:
镜像是分层结构,每一层称为一个Layer
BaseImage层:包含基本的系统函数库、环境变量、文件系统
Entrypoint:入口,是镜像中应用启动的命令
其他:在BaseImage基础上添加依赖、安装程序、完成整个应用的安装和配置
Dockerfile
Dockerfile是一个文本文件,其中包含一个个的指令(Instruction),用指令来说明要执行什么操作来构建镜像。每一个指令都会形成一层Layer

简单的Dockerfile为例:
# 指定基础镜像
FROM ubuntu:16.04
# 配置环境变量,JDK的安装目录
ENV JAVA_DIR=/usr/local
# 拷贝jdk和java项目的包
COPY ./jdk8.tar.gz $JAVA_DIR/
COPY ./docker-demo.jar /tmp/app.jar
# 安装JDK
RUN cd $JAVA_DIR \
&& tar -xf ./jdk8.tar.gz \
&& mv ./jdk1.8.0_144 ./java8
# 配置环境变量
ENV JAVA_HOME=$JAVA_DIR/java8
ENV PATH=$PATH:$JAVA_HOME/bin
# 暴露端口
EXPOSE 8090
# 入口,java项目的启动命令
ENTRYPOINT java -jar /tmp/app.jar案例1:
基于Ubuntu镜像构建一个新镜像,运行一个java项目
步骤1:新建一个空文件夹docker-demo
步骤2:拷贝课前资料的docker-demo.jar文件到docker-demo这个目录
步骤3:拷贝课前资料的jdk8.tar.gz文件到docker-demo这个目录
步骤4:拷贝课前资料提供的Dockerfile到docker-demo这个目录
步骤5:进入docker-demo
步骤6:运行命令
docker build -t javaweb:1.0 .
记得命令末尾 空格+一个点,这个点代表Dockerfile所在的目录(构建的时候要告诉docker Dockerfile在哪)

检查并运行此镜像:

访问页面,出现下面的页面即大功告成:

案例2:
基于java:8-alpine镜像,将一个Java项目构建为镜像
实现思路:
①新建一个空的目录,然后目录中新建一个文件,命名为Dockerfile
②拷贝课前资料提供的docker-demo.jar到这个目录中
③编写Dockerfile文件:
a)基于java:8-alpine作为基础镜像
b)将app.jar拷贝到镜像中
c)暴露端口
d)编写入口ENTRYPOINT
④使用docker build命令构建镜像
⑤使用docker run创建容器并运行
Dockerfile文件:
# 指定基础镜像
FROM java:8-alpine
# 拷贝
COPY ./docker-demo.jar /tmp/app.jar
# 暴露端口
EXPOSE 8090
# 入口,java项目的启动命令
ENTRYPOINT java -jar /tmp/app.jar注意不要随便更改暴露出来的端口,运行成功

初识DockerCompose
Docker Compose可以基于Compose文件帮我们快速地部署分布式应用,而无需手动一个个创建和运行容器
Compose文件是一个文本文件,通过指令定义集群中的每个容器如何运行

安装docker compose:
第一步:下载

第二步:修改文件权限
+x代表给docker-compose执行权(绿色代表可以执行)

第三步让tionBash自动补全命令

总结:
Docker compose有什么作用?
帮助我们快速部署分布式应用,无需一个个微服务去构建镜像和部署
DockerCompose部署微服务
案例:将之前学习的cloud-demo微服务集群利用DockerCompose部署
①查看docker-compose:

②修改自己的cloud-demo项目,将数据库、nacos地址都命名为docker-compose中的服务名
(用docker compose部署,所有的服务之间都可以用服务名访问)
③使用maven打包工具,将项目中的每个微服务都打包为app.jar
④将打包好的app.jar拷贝到cloud-demo中的每一个对应的子目录中
⑤将cloud-demo上传至虚拟机,利用docker-compose up -d 来部署
因为阿里代码有问题,nacos应该第一时间部署,而后再部署其他微服务,所以需要重启gateway、orderservice、userservice

访问页面成功则配置成功:

Docker镜像仓库
镜像仓库(Docker Registry)有共有和私有两种形式:
公共仓库:例如Docker官方的Docker Hub
私有仓库:用户自己搭建
简化版镜像仓库:
Docker官方的Docker Registry是一个基础版本的Docker镜像仓库,具备仓库管理的完整功能,但是没有图形化界面
搭建方式比较简单,命令如下:

访问http://Yourlp:5000/v2/ catalog 可以查看当前私有镜像服务中包含的镜像
带有图形化界面
使用DockerCompose部署带有图像界面的DockerRegistry,命令如下:

第一步:配置Docker信任地址
我们的私服采用的是http协议,默认不被Docker信任,所以需要做一个配置:

第二步:配置docker-compose

配置好后执行命令:
docker-compose up -d
加载完毕后,可以看到ui界面

在私有镜像仓库推送或拉取镜像:

推送镜像成功可以在私服看到:

总结:
1.推送本地镜像到仓库前都必须重命名(docker tag)镜像,以镜像仓库地址为前缀
2.镜像仓库推送前需要把仓库地址配置到docker服务的daemon.json文件,被docker信任
3.推送使用docker push命令
4.拉取使用docker pull命令
实用篇---第四天

一、初识MQ
同步通讯和异步通讯
同步通信相当于打视频,一次只能和一个人打
异步通信相当于聊天,一次可以和很多个人聊

同步通信的优缺点
缺点:
微服务间基于Feign的调用就属于同步方式,存在一些问题
①代码耦合严重,比如支付服务需要在加业务的时候不断修改
②耗时太长,性能下降
......


总结:
同步调用的优点:
时效性强,可以立即得到结果
同步调用的问题:
耦合度高
性能和吞吐能力下降
有额外的资源消耗
有级联失败问题
异步通信的优缺点
异步调用常见实现是事件驱动模式

优点:
①服务解耦
②性能提升,吞吐量提高
③服务没有强依赖,不担心级联失败问题(故障隔离)
④流量削峰
缺点:
①依赖于Broker的可靠性、安全性、吞吐力量
②架构复杂,业务没有明显的流程线,不好追踪管理
mq常见技术介绍
MQ:Message Queue,中文是消息队列,也就是事件驱动架构中的Broker

二、RabbitMQ入门
RabbitMQ介绍和安装
RabbitMQ是基于Erlang计开发的开源消息中间件
单机部署:
第一步:下载镜像
方式一:在线拉取
docker pull rabbitmq:3-management方式二:从本地加载
将mq.tar上传到虚拟机中,使用命令加载镜像即可:
docker load -i mq.tar第二步:执行下面的命令来运行MQ容器

然后就可以进入rabbitMQ了

RabbitMQ的结构和概念:

RabbitMQ中的几个概念:
channel:操作MQ的工具
exchange:路由消息到队列中
queue:缓存消息
virtual host:虚拟主机,是对queue、exchange等资源的逻辑分组
消息模型

HelloWorld案例
官方的HelloWorld是基于最基础的消息队列模型来实现的,只包括三个角色:
publisher:消息发布者,将消息发送到队列queue
queue:消息队列,负责接受并缓存消息
consumer:订阅消息,处理队列中的消息

完成官方Demo中的hello world案例
①导入课前资料的mq-demo工程
②运行publisher服务中的测试类PublisherTest中的测试方法testSendMessage()
③查看RabbitMQ控制台的消息
④启动consumer服务,查看是否能接收消息
总结:
基本消息队列的消息发送流程:
1.建立connection
2.创建channel
3.利用channel声明队列
4.利用channel向队列发送消息
基本消息队列的消息接收流程:
1.建立connection
2.建立channel
3.利用channel声明队列
4.利用consumer的消费行为handleDelivery()
5.利用channel将消费者与队列绑定
三、SpringAMQP
SpringAMQP基本介绍

特征:
侦听器容器,用于异步处理入站消息
用于发送和接收消息的RabbitTemplate
RabbitAdmin用于自动声明队列、交换和绑定
基本消息队列功能实现
消息发送:
1.在父工程中引入spring-amqp的依赖
2.在publisher服务中利用RabbitTemplate发送消息到simple.queue这个队列
3.在consumer服务中编写消费逻辑,绑定simple.queue这个队列
第一步实现:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>第二步实现:
①在publisher服务中编写application.yml,添加mq连接信息
spring:
rabbitmq:
host: 192.168.150.101
port: 5672
username: itcast
password: 123321
virtual-host: /②在publisher服务中新建一个测试类,编写测试方法
@SpringBootTest
public class SpringAmqpTest {
@Autowired
private RabbitTemplate rabbitTemplate;
@Test
public void testSendMessage2SimpleQueue(){
String queueName="simple.queue";
String message="hello,Spring AMQP!";
rabbitTemplate.convertAndSend(queueName,message);
}
}总结:
什么是AMQP?
应用间消息通信的一种协议,与语言和平台无关
SpringAMQP如何发送消息?
①引入amqp的starter依赖
②配置RabbitMQ地址
③利用RabbitTemplate的convertAndSend方法
消息消费:
1.在consumer服务中编写application.yml,添加mq连接信息
spring:
rabbitmq:
host: 192.168.202.128
port: 5672
virtual-host: /
username: itcast
password: 1233212.在consumer服务中新建一个类,编写消费逻辑
@Component
public class SpringRabbitListener {
@RabbitListener(queues = "simple.queue")
public void listenSimpleQueue(String msg){
System.out.println("消费者接收到simple.queue的消息【"+msg+"】");
}
}
接收消息成功:

总结:
SpringAMQP如何接收消息?
引入amqp的starter依赖
配置RabbitMQ地址
定义类,添加@Component注解
类中声明方法,添加@RabbitListener注解,方法参数接收消息
注意:消息一旦消费就会从队列中删除,RabbitMQ没有消息回溯功能
Work Queue 工作队列
Work Queue,工作队列,挂载两个消费者,可以提高消息处理的速度,避免队列消息堆积

案例:模拟WorkQueue,实现一个队列绑定多个消费者
基本思路如下:
1.在publisher服务中定义测试方法,每秒产生50条消息,发送到simple.queue
2.在consumer服务中定义两个消息监听者,都监听simple.queue队列
3.消费者1每秒处理50条消息,消费者2每秒处理10条消息
生产者:
@SpringBootTest
public class SpringAmqpTest {
@Autowired
private RabbitTemplate rabbitTemplate;
@Test
public void testSendMessage2SimpleQueue() throws InterruptedException {
String queueName = "simple.queue";
String message = "hello,message--";
for (int i = 0; i < 50; i++) {
rabbitTemplate.convertAndSend(queueName, message+i);
Thread.sleep(20);
}
}
}消费者:
@Component
public class SpringRabbitListener {
@RabbitListener(queues = "simple.queue")
public void listenWorkQueue(String msg) throws InterruptedException {
System.out.println("消费者1接收到simple.queue的消息【"+msg+"】"+ LocalTime.now());
Thread.sleep(20);
}
@RabbitListener(queues = "simple.queue")
public void listenWorkQueue2(String msg) throws InterruptedException {
System.err.println("消费者2接收到simple.queue的消息【"+msg+"】"+LocalTime.now());
Thread.sleep(200);
}
}因为消费预取限制,导致消息预取分配给两个cnsumer各一半。消费者1只接收奇数消息队列,消费者2只接收偶数消息队列,而消费者2的处理消息能力远低于消费者1,会拉低整体处理消息的能力
取消消费预取限制:
修改application.yml文件,设置preFetch这个值,可以控制预取消息的上限:
spring:
rabbitmq:
host: 192.168.202.128
port: 5672
virtual-host: /
username: itcast
password: 123321
listener:
simple:
prefetch: 1 #每次只能获取一条消息,处理完成才能获取下一个消息总结:
Work模型的使用:
多个消费者绑定到一个队列,同一条消息只会被一个消费者处理
通过设置prefetch来控制消费者预取的消息数量
发布订阅模型介绍
发布(publish)订阅(subscribe)模式与之前案例的区别就是允许将同一消息发送给多个消费者。实现方式是加入了exchange(交换机)
常见的exchange类型包括:
Fanout:广播
Direct:路由
Topic:话题
注意:exchange负责消息路由,而不是存储,路由失败则消息丢失

Fanout Exchange
Fanout Exchange会将接收到的消息路由到每一个跟其绑定的queue
案例:利用SpringAMQP演示FanoutExchange的使用
实现思路:
1.在consumer服务中,利用代码声明队列、交换机,并将两者绑定
2.在consumer服务中,编写两个消费者方法,分别监听fanout.queue1和fanout.queue2
3.在publisher中编写测试方法,向itcast.fanout发送消息

步骤一:
首先,SpringAMQP提供了声明交换机、队列、绑定关系的API,例如:

其次,在consumer服务创建一个类,添加@Configuration注解,并声明FanoutExchange、Queue和绑定关系对象Binding。
代码如下:
@Configuration
public class FanoutConfig {
//itcast.fanout
@Bean
public FanoutExchange fanoutExchange(){
return new FanoutExchange("itcast.fanout");
}
//fanout.queue1
@Bean
public Queue fanoutQueue1(){
return new Queue("itcast.queue1");
}
//fanout.queue2
@Bean
public Queue fanoutQueue2(){
return new Queue("itcast.queue2");
}
@Bean
public Binding fanoutBinding1(Queue fanoutQueue1,FanoutExchange fanoutExchange){
return BindingBuilder.bind(fanoutQueue1).to(fanoutExchange);
}
@Bean
public Binding fanoutBinding2(Queue fanoutQueue2,FanoutExchange fanoutExchange){
return BindingBuilder.bind(fanoutQueue2).to(fanoutExchange);
}
}
步骤二:
@Component
public class SpringRabbitListener {
@RabbitListener(queues = "itcast.queue1")
public void listenWorkQueue(String msg) throws InterruptedException {
System.out.println("消费者1接收到Fanout的消息【"+msg+"】"+ LocalTime.now());
}
@RabbitListener(queues = "itcast.queue2")
public void listenWorkQueue2(String msg) throws InterruptedException {
System.err.println("消费者2接收到Fanout的消息【"+msg+"】"+LocalTime.now());
}
}
步骤三:
@SpringBootTest
public class SpringAmqpTest {
@Autowired
private RabbitTemplate rabbitTemplate;
@Test
public void testSendFanoutExchange(){
//交换机名称
String exchangeName="itcast.fanout";
//消息
String message="hello,everybody~";
//发送
rabbitTemplate.convertAndSend(exchangeName,"",message);
}
}运行成功,nice

总结:
交换机的作用是什么?
接收publisher发送的消息
将消息按照规则路由到与之绑定的队列
不能缓存消息,路由失败,消息失败
FanoutExchange会将消息路由到每个绑定的队列
声明队列、交换机、绑定关系的Bean是什么?
Queue
FanoutExchange
Binding
DirectExchange
DirectExchange会将接收到的消息根据规则路由到指定的Queue,因此成为路由模式(routes)

案例:利用SpringAMQP演示DirectExchange的使用
实现思路如下:
1.利用@RabbitListener声明Exchange、Queue、RoutingKey
2.在consumer服务中,编写两个消费者方法,分别监听direct.queue1和direcct.queue2
3.在publisher中编写测试方法,向itcast.direct发送消息
步骤一、二:
@Component
public class SpringRabbitListener {
@RabbitListener(bindings=@QueueBinding(
value=@Queue(name="direct.queue1"),
exchange=@Exchange(name="itcast.direct",type= ExchangeTypes.DIRECT),
key={"red","blue"}
))
public void listenDirectQueue1(String msg){
System.err.println("消费者接收到direct.queue1的消息【"+msg+"】"+LocalTime.now());
}
@RabbitListener(bindings = @QueueBinding(
value=@Queue(name="direct.queue2"),
exchange = @Exchange(name="itcast.direct",type="direct"),
key={"red","yellow"}
))
public void listenDirectQueue2(String msg){
System.err.println("消费者接收到direct.queue2的消息【"+msg+"】"+LocalTime.now());
}
}步骤三:
@Test
public void testSendDirectExchange(){
String exchangeName="itcast.direct";
String message="hello,blue";
rabbitTemplate.convertAndSend(exchangeName,"blue",message);
}总结:
描述下Direct交换机与Fanout交换机的差异?
Fanout交换机将消息路由给每一个与之绑定的队列
Direct交换机根据RoutingKey判断路由给哪个队列
如果多个队列具有相同的RoutingKey,则与Fanout功能类似
基于@RabbitListener注解声明队列和交换机有哪些常见注解?
@Queue
@Exchange
TopicExchange
TopicExchange与DirectExchange类似,区别在于routingKey必须是多个单词的列表,且以点.做分割
Queue与Exchange指定BindingKey时可以使用通配符:
#:代指0个或多个单词
*:代指一个单词

案例:利用SpringAMQP演示TopicExchange的使用
实现思路如下:
1.利用@RabbitListener声明Exchange、Queue、RoutingKey
2.在consumer服务中编写两个消费者方法,分别监听topic.queue1和topic.queue2
3.在publisher中编写测试方法,向itcast.topic发送消息

步骤一、二:
@RabbitListener(bindings = @QueueBinding(
value=@Queue("topic.queue1"),
exchange = @Exchange(name="itcast.topic",type="topic"),
key = "china.#"
))
public void listenTopicQueue1(String msg){
System.err.println("消费者接收到topic.queue1的消息【"+msg+"】");
}
@RabbitListener(bindings = @QueueBinding(
value=@Queue("topic.queue2"),
exchange = @Exchange(name="itcast.topic",type="topic"),
key = "#.news"
))
public void listenTopicQueue2(String msg){
System.err.println("消费者接收到topic.queue2的消息【"+msg+"】");
}步骤三:
@Test
public void testSendTopicExchange(){
String exchangeName="itcast.topic";
String message="学it,来黑马";
rabbitTemplate.convertAndSend(exchangeName,"china.news",message);
}消息转换器
案例:测试发送Object类型消息
说明:在SpringAMQP的发送方法中,接收消息的类型是Object,也就是说我们可以发送任意类型的消息,SpringAMQP会帮我们序列化为字节后发送
@Bean Queue objectQueue(){
return new Queue("object.queue");
} public void testSendObjectQueue(){
Map<String,Object> msg=new HashMap<>();
msg.put("name","柳岩");
msg.put("age",21);
rabbitTemplate.convertAndSend("object.queue",msg);
}队列中收到的消息:

===>Spring对消息对象的处理是由org.springframework.amqp.support.converter.Messaegonverter来处理的。而默认实现是SimpleMessageConverter,基于JDK的ObjectOutputStream来完成序列化
如果要修改只需要定义一个MessageConverter类型的Bean即可。推荐用JSON方式序列号。步骤如下:
消息发送:
①在publisher服务引入依赖
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>②在publisher服务声明MessageConverter
@Bean
public MessageConverter messageConverter(){
return new Jackson2JsonMessageConverter();
}运行结果:

消息接收:
①引入jackson依赖
②在consumer服务中定义MessageConverter
③定义一个消费者,监听object.queue队列并消费消息
@RabbitListener(queues="object.queue")
public void listenObejctQueue(Map<String,Object> msg){
System.out.println("收到消息:【"+msg+"】");
}总结:
SpringAMQP中的消息序列化和反序列化是怎么实现的?
利用MessageConverter实现的,默认是JDK的序列化
注意发送方与接收方必须使用相同的MessageConverter
实用篇---第五天
分布式搜索---elasticsearch

一、初识elasticsearch
什么是elasticsearch?
elasticsearch是一款非常强大的开源搜索引擎,可以帮助我们从海量数据中快速找到需要的内容
elasticsearch结合kibana、Logstash、Beats,也就是elastic stack(ELK)。被广泛应用在日志数据分析、实时监控等领域
elasticsearch是elastic stack的核心,负责存储、搜索和分析数据

elasticsearch底层使用了Lucene技术
Lucene是一个Java语言的搜索引擎类库,是Apache公司的顶级项目,由DougCutting于1999年研发
Lucene的优势:
易扩展
高性能(基于倒排索引)
Lucene的缺点:
只限于Java语言开发
学习曲线陡峭
不支持水平扩展
elasticsearch的发展:
2004年Shay Banon基于Lucene开发了Compass
2010年Shay Banon重写了Compass,取名为Elasticsearch
相比于Lucene,elasticsearch具备下列优势:
支持分布式,可水平扩展
提供Restful接口,可悲任何语言调用

总结:

正向索引和倒排索引
传统数据库(如MySQL)采用正向索引
elasticsearch采用倒排索引:
文档(document):每条数据就是一个文档
词条(term):文档按照语义分成的词语

正向索引:基于文档id创建索引。查询词条时必须先找到文档,而后判断是否包含词条
倒排索引:对文档内容分词,对词条创建索引,并记录词条所在文档的信息。查询时先根据词条查询到文档id,而后获取文档
es和mysql概念对比
文档:
elasticsearch是面向文档存储的,可以是数据库中的一条商品数据、一个订单信息
文档数据会被序列化为json格式后存储在elasticsearch中

索引:
索引(index):是相同类型文档的集合
映射(mapping):索引中文档的字段约束信息,类似表的结构约束

概念对比:

架构
MySQL:擅长事务类型操作,可以确保数据的安全和一致性
Elasticsearch:擅长海量数据的搜索、分析和计算

总结:
文档:一条数据就是一个文档,es中是json格式
字段:json文档中的字段
索引:同类型文档的集合
映射:索引中文档的约束,比如字段名称、类型
elasticsearch与数据库的关系:
数据库负责事务类型操作
elasticsearch负责海量数据的搜索、分析和计算
安装es
第一步:创建网络
因为我们还需要部署kibana容器,因此需要让es和kibana容器互联。这里先创建一个网络:
docker network create es-net
第二步:将es.tar加载:
docker load -i es.tar
kibana的tar包也需要这样做
第三步:运行docker命令,部署单点es

只要看到下面的界面,就代表部署es成功:

安装kibana
kibana可以给我们提供一个elasticsearch的可视化界面,便于我们学习
部署:
运行docker命令,部署kibana

--network=es-net:加入一个名为es-net的网络中,与elasticsearch在同一个网络中
-e ELASTICSEARCH_HOSTS=http://es:9200:设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,所以可以用容器名直接访问elasticsearch
注意:kibana和elasticsearch的版本必须严格一致,并在同一网络中
看到下面这个界面代表部署kibana成功:

安装ik分词器
es在创建倒排索引时需要对文档分词
在搜索时,需要对用户输入内容分词。但默认的分词规则则对中文处理并不友好。
我们可以在kibana的DevTools中测试:
POST /_analyze
{
"analyzer": "standard",
"text": "黑马程序员学习java也太棒了吧!"
}语法说明:
POST:请求方式
/_analyze:请求路径,这里省略了http://192.168.150.101:9200,有kibana帮我们补充
请求参数,json风格:
analyzer:分词器类型,这里默认是standard
text:要分词的内容
分词结果:

处理中文分词,一般会使用lk分词器
安装ik:
第一步:查看数据卷目录
安装插件需要知道elasticsearch的plugins目录位置,而我们用了数据卷挂载,因此需要查看elasticsearch的数据卷目录,通过下面命令查看:

第二步:把课前资料中的lk分词器解压缩,重命名为ik

第三步:上传到es容器的插件数据卷中
也就是/var/lib/docker/volumes/es-plugins/_data

第四步:重启容器
docker restart es
第五步:测试
ik分词器包含两种模式:
ik_smart:最少切分
ik_max_word:最细切分
POST /_analyze
{
"analyzer": "ik_smart",
"text": "黑马程序员学习java也太棒了吧!"
}分词效果:

ik分词器的扩展和停用词典
测试:
POST /_analyze
{
"analyzer":"ik_smart",
"text":"传智播客的课程可白嫖"
}可以看到ik无法对所有词语完美分词:

扩展词库:

停用词库:

进入文件,可以看见:

entry标签里填入文件名,直接进入对应的文件添加内容即可

重启es:
docker restart es
测试:
POST /_analyze
{
"analyzer":"ik_smart",
"text":"传智播客的课程可白嫖了"
}
总结:
分词器的作用是什么?
创建倒排索引时对文档分词
用户搜索时,对输入的内容分词
ik分词器有几种模式?
ik_smart:只能切分,粗粒度
ik_max_word:最细切分,细粒度
ik分词器如何扩展词条?如何停用词条?
利用config目录的ikAnalyzer.cfg.xml文件添加扩展词典和停用词典
在词典中添加扩展词条或者停用词条
二、索引库操作
mapping映射属性
mapping是对索引库中文档的约束,常见的mapping属性包括:
type:字段数据类型,常见的简单类型有:
字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
数值:long、integer、short、byte、double、float
布尔:boolean
日期:date
对象:object
注意,在es中没有数组这个类型,但是允许某一种类型的字段有多个值,所以这些都可以作为数组
index:是否创建索引,默认为true。只有index为true,才会创建倒排索引,如果index设为false,则不参与倒排索引
analyzer:使用哪种分词器
properties:该字段的子字段

总结:

创建索引库
ES中通过Restful请求操作索引库、文档。请求内容用DSL语句表示。
创建索引库和mapping的DSL语法如下:

实操定义DSL语句:
PUT /heima
{
"mappings":{
"properties":{
"info":{
"type":"text",
"analyzer":"ik_smart"
},
"email":{
"type":"keyword",
"index":false
},
"name":{
"type":"object",
"properties": {
"firstName":{
"type":"keyword"
},
"lastName":{
"type":"keyword"
}
}
}
}
}
}创建成功:

查看、删除、修改索引库
查看索引库语法:
GET /索引库名
删除索引库语法:
DELETE /索引库名
修改索引库:
索引库和mapping一旦创建无法修改,但是可以添加新的字段,语法如下:
PUT /heima/_mapping
{
"properties":{
"age":{
"type":"integer"
}
}
}
总结:
索引库操作有哪些?
创建索引库:PUT/索引库名
查询索引库:GET/索引库名
删除索引库:DELETE/索引库名
添加字段:PUT/索引库名/_mapping
三、文档操作
新增、查询、删除文档
新增文档的DSL语法:

插入一个文档:
POST /heima/_doc/1
{
"name":{
"firstName":"信",
"lastName":"李"
},
"info":"人送外号峡谷拆迁队队长",
"email":"123@qq.com"
}查看文档:
语法:GET /索引库名/_doc/文档id
示例:
GET /heima/_doc/1
删除文档:
语法:DELETE 索引库名/_doc/文档id
示例:
DELETE /heima/_doc/1修改文档
方式一:全量修改,会删除旧文档,添加新文档
其实这种方式既可以做新增又可以做修改

方式二:
增量修改,修改制定的字段值

可以修改已经有的字段:
POST /heima/_update/1
{
"doc":{
"email":"lixin@qq.com"
}
}也可以添加没有的字段:
POST /heima/_update/1
{
"doc":{
"gender":"男"
}
}此时查看索引结构,可以发现gender字段被创建出来了

总结:

四、RestClient操作索引库
导入demo
ES官方提供了各种语言的客户端,用来操作ES。这些客户端的本质就是组装DSL语句,通过http请求发送给ES。
案例:利用JavaRestClient实现创建、删除索引库,判断索引库是否存在

hotel数据结构分析
mapping要考虑的问题:
字段名、数据类型、是否参与搜索、是否分词、如果分词,分词器是什么?


定义hotel:
PUT /hotel
{
"mappings":{
"properties":{
"id":{
"type":"keyword"
},
"name":{
"type":"text",
"analyzer":"ik_max_word",
"copy_to":"all"
},
"address":{
"type":"keyword",
"index":false
},
"price":{
"type":"integer"
},
"score":{
"type":"integer"
},
"brand":{
"type":"keyword",
"copy_to":"all"
},
"city":{
"type":"keyword"
},
"star_name":{
"type":"keyword"
},
"business":{
"type":"keyword",
"copy_to": "all"
},
"location":{
"type":"geo_point"
},
"pic":{
"type":"keyword",
"index":false
},
"all":{
"type":"text",
"analyzer":"ik_max_word"
}
}
}初始化RestClient
1.引入es的RestHighLevelClient依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.12.1</version>
</dependency>2.因为SpringBoot默认的ES版本是7.6.2,所以我们需要覆盖默认的ES版本
<elasticsearch.version>7.12.1</elasticsearch.version>
3.初始化RestHighLevelClient
public class HotelIndexTest {
private RestHighLevelClient client;
@BeforeEach
void setUp(){
this.client=new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.202.128:9200")
));
}
@AfterEach
void testDown() throws IOException {
this.client.close();
}
}创建索引库

删除和判断数据库
删除索引库:
@Test
void testDeleteHotelIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("hotel");
client.indices().delete(request,RequestOptions.DEFAULT);
}判断索引库是否存在
@Test
void testExistHotelIndex() throws IOException {
GetIndexRequest request = new GetIndexRequest("hotel");
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.err.println(exists?"索引库已经存在!":"索引库不存在!");
}总结:
索引库操作的基本步骤:
①初始化RestHighLevelClient
②创建XxxIndexRequest。Xxx是Create、Get、Delete
③准备DSL(Create时需要)
④发送请求。调用RestHighLevelClient的indices().xxx()方法
xxx是create、exists、delete
五、RestClient操作文档

新增文档
第一步:初始化JavaRestClient
新建一个测试类,实现文档相关操作,并且完成JavaestClient的初始化
第二步:添加酒店数据到索引库
先查询酒店数据,然后给这条数据创建倒排索引,即可完成添加
public class HotelDocumentTest {
private RestHighLevelClient client;
@BeforeEach
void setUp(){
this.client=new RestHighLevelClient(RestClient.builder(
HttpHost.create("192.168.202.128:9200")
));
}
@AfterEach
void testDown() throws IOException {
this.client.close();
}
}给测试类添加@SpringBootTest注解,可以自动注入
@Autowired
private IHotelService hotelService;
@Test
void testAddDocument() throws IOException {
//根据id查询酒店数据
Hotel hotel = hotelService.getById(61083L);
HotelDoc hotelDoc = new HotelDoc(hotel);
//1.准备Request对象
IndexRequest request = new IndexRequest("hotel").id(hotelDoc.getId().toString());
//2.准备Json文档
request.source(JSON.toJSONString(hotelDoc), XContentType.JSON);
//3.发送请求
client.index(request, RequestOptions.DEFAULT);
}注:因为我们准备的实体类和索引库的实体类有差异,所以需要为索引库数据专门准备一个转变的实体类
@Data
@NoArgsConstructor
public class HotelDoc {
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String location;
private String pic;
public HotelDoc(Hotel hotel) {
this.id = hotel.getId();
this.name = hotel.getName();
this.address = hotel.getAddress();
this.price = hotel.getPrice();
this.score = hotel.getScore();
this.brand = hotel.getBrand();
this.city = hotel.getCity();
this.starName = hotel.getStarName();
this.business = hotel.getBusiness();
this.location = hotel.getLatitude() + ", " + hotel.getLongitude();
this.pic = hotel.getPic();
}
}在索引库中查询
GET /hotel/_doc/61083

查询文档
@Test
void testGetDocumentById() throws IOException {
//1.准备Request
GetRequest request = new GetRequest("hotel", "61083");
//2.发送请求,得到响应
GetResponse response = client.get(request, RequestOptions.DEFAULT);
//3.解析响应结果
String json = response.getSourceAsString();
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
System.out.println(hotelDoc);
}运行结果:

更新文档
修改文档数据有两种方式:
方式一:全量更新。再次写入id一样的文档,就会删除旧文档,添加新文档
方式二:局部更新。只更新部分字段
我们演示方式二:
@Test
void testUpdateDocument() throws IOException {
//1.准备Request
UpdateRequest request = new UpdateRequest("hotel", "61083");
//2.准备请求参数
request.doc(
"price","952",
"starName","四钻"
);
//3.发送请求
client.update(request,RequestOptions.DEFAULT);
}可以看到price和starName修改成功:

删除文档
@Test
void testDeleteDocument() throws IOException {
DeleteRequest request = new DeleteRequest("hotel", "61083");
client.delete(request,RequestOptions.DEFAULT);
}总结:
文档操作的基本步骤:
初始化RestHighLevelClient
初始化XxxRequest。Xxx是Index、Get、Update、Delete
准备参数(Index和Update时需要)
发送请求。调用RestHighLevelClient的xxx()方法
xxx是index、get、update、delete
批量导入文档
需求:批量查询酒店数据,然后批量导入索引库中
思路:
1.利用mybatis-plus查询酒店数据
2.将查询到的酒店数据(Hotel)转换为文档类型数据(HotelDoc)
3.利用JavaRestClient中的Bulk批处理,实现批量新增文档
@Test
void testBulkRequest() throws IOException {
//批量查询酒店数据
List<Hotel> hotels = hotelService.list();
//1.创建Request
BulkRequest request = new BulkRequest();
for(Hotel hotel:hotels){
HotelDoc hotelDoc = new HotelDoc(hotel);
//2.准备参数,添加多个新增的Request
request.add(new IndexRequest("hotel").id(hotelDoc.getId().toString()).source(JSON.toJSONString(hotelDoc),XContentType.JSON));
}
//3.发送请求
client.bulk(request,RequestOptions.DEFAULT);
}可以用DSL语句:GET /hotel/_search 对批量导入功能进行验证

六、分布式搜索引擎

DSL查询文档
Elasticsearch提供了基于JSON的DSL来定义查询。常见的查询类型包括:
查询所有:查询出所有数据,一般测试用。例如:match_all
全文检索(full text)查询:利用分词器对用户输入内容分词,然后去倒排索引库中匹配。例如:
match_query
multi_match_query
精确查询:根据精确词条值查找数据,一般是查找keyword、数值、日期、boolean等类型字段
ids
range
term
地理(geo)查询:根据经纬度查询。例如:
geo_distance
geo_bounding_box
复合(compound)查询:复合查询可以将上述各种条件组合起来,合并查询条件。例如:
bool
function_score

GET /hotel/_search
{
"query":{
"match_all":{
}
}
}查询DSL的基本语法是什么?
GET /索引库名/_search
{
“query”:{
“查询类型”:{
“FIELD”:“TEXT”
}
}
}
全文检索查询
全文检索查询,会对用户输入内容分词,常用于搜索框搜索:

match查询:全文检索查询的一种,会对用户输入内容分词,然后去倒排索引库检索。
语法:

比如查询如家外滩,首先会对“如家外滩”分词,匹配度越高,得分越高,越靠前
GET /hotel/_search
{
"query":{
"match":{
"all":"外滩如家"
}
}
}multi_match:与match查询类似,只不过允许同时查询多个字段

GET /hotel/_search
{
"query": {
"multi_match": {
"query": "外滩如家",
"fields": ["brand","name","business"]
}
}
}总结:
match和multi_match的区别是什么?
match:根据一个字段查询
multi_match:根据多个字段查询,参与查询的字段越多,性能就越差
精确查询
精确查询一般是查找keyword、数值、日期、boolean等类型字段。所以不会对搜索条件分词。常见的有:
term:根据词条精确值查询
range:根据值的范围查询

term查询:
GET /hotel/_search
{
"query":{
"term":{
"city":{
"value":"上海"
}
}
}
}range查询:
GET /hotel/_search
{
"query": {
"range":{
"price":{
"gte":100,
"lte":300
}
}
}
}
地理查询

geo_bounding_box:查询geo_point值落在某个矩形范围的所有文档

geo_distance:查询到指定中心点小于某个距离值的所有文档

GET /hotel/_search
{
"query":{
"geo_distance":{
"distance":"15km",
"location":"31.21,121.5"
}
}
}相关性打分算法
复合(compound)查询:复合查询可以将其他简单查询组合起来,实现更复杂的搜索逻辑:
例如:
function score:算分函数查询,可以控制文档相关性算分,控制文档排名。例如百度竞价
相关性算分:
当我们利用match查询时,文档结果会根据与搜索词条的关联度打分(_score),返回结果时按照分值降序排列

总结:

Function Score Query

案例:给“如家”这个品牌的酒店排名靠前一点
==>翻译来说,function score需要的三要素:
1.哪些文档需要算分加权?
品牌为如家的酒店
2.算分函数是什么?
weight
3.加权模式是什么?
求和
GET /hotel/_search
{
"query":{
"function_score":{
"query":{
"match":{
"all":"外滩"
}
},
"functions":[
{
"filter":{
"term":{
"brand":"如家"
}
},
"weight":10
}
],
"boost_mode":"sum"
}
}
}function score query定义的三要素是什么?
过滤条件:哪些文档要加分
算分函数:如何计算function score
加权方式:function score与query score如何运算
Boolean Query
布尔查询是一个或多个查询子句的组合。子查询的组合方式有:
must:必须匹配每个子查询,类似“与”
should:选择性匹配子查询,类似“或”
must_not:必须不匹配,不参与算分,类似于“非”
filter:必须匹配,不参与算分
案例:利用bool查询实现功能
需求:搜索名字包含“如家”,价格不高于400,在坐标31.21,121.5周围10km范围内的酒店
GET /hotel/_search
{
"query":{
"bool":{
"must": [
{
"match": {
"name":"如家"
}
}
],
"must_not":[
{
"range":{
"price":{
"gt":400
}
}
}
],
"filter":[
{
"geo_distance":{
"distance":"10km",
"location":{
"lat": 31.21,
"lon":121.5
}
}
}
]
}
}
}二、搜索结果处理
排序
elasticsearch支持对搜索结果排序,默认是根据相关度算分(_score)来排序。可以排序的字段类型由:keyword类型、数值类型、地理坐标类型、日期类型等

案例:对酒店数据按照用户评价降序排序,评价相同的按照价格升序排序
GET /hotel/_search
{
"query":{
"match_all":{}
},
"sort":[
{
"score":"desc"
},
{
"price":"asc"
}
]
}案例:实现对酒店数据按照你的位置坐标的距离升序排序
GET /hotel/_search
{
"query":{
"match_all":{}
},
"sort":[
{
"_geo_distance": {
"location": {
"lat": 31.034661,
"lon": 121.612282
},
"order": "asc",
"unit":"km"
}
}
]
}分页
elasticsearch默认情况下只返回top10的数据。而如果要查询更多的数据,就需要修改分页参数
elasticsearch中通过from、size参数来控制要返回的分页结果:
GET /hotel/_search
{
"query":{
"match_all": {}
},
"sort":[
{
"price":"asc"
}
],
"from":2,
"size":10
}
深度分页问题:
ES是分布式的,所以会面临深度分页问题。例如按price排序后,获取from=990,size=10的数据:

针对深度分页,ES提供了两种解决方案:
search after:分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐。
scroll:原理是将排序数据形成快照,保存在内存。官方已经不推荐使用。
总结:

高亮
高亮就是在搜索结果中把搜索关键字突出显示
原理:
将搜索结果中的关键字用标签标记出来
在页面中给标签添加css样式
注意:高亮查询,默认情况下ES搜索字段必须和高亮字段一致
GET /hotel/_search
{
"query":{
"match":{
"all":"如家"
}
},
"highlight": {
"fields":{
"name":{
"require_field_match":"false"
}
}
}
} 
总结:

三、RestClient查询文档
快速入门
@Test
void testMatchAll() throws IOException {
SearchRequest request = new SearchRequest("hotel");
request.source().query(QueryBuilders.matchAllQuery());
SearchResponse search = client.search(request, RequestOptions.DEFAULT);
System.out.println(search);
}解析拿到的结果:

总代码:
@Test
void testMatchAll() throws IOException {
SearchRequest request = new SearchRequest("hotel");
request.source().query(QueryBuilders.matchAllQuery());
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
SearchHits searchHits = response.getHits();
long total = searchHits.getTotalHits().value;
System.out.println("共搜索到"+total+"条数据");
SearchHit[] hits = searchHits.getHits();
for(SearchHit hit:searchHits){
String json = hit.getSourceAsString();
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
System.out.println(hotelDoc);
}
}总结:

总结:
查询的基本步骤是:
1.创建SearchRequest对象
2.准备Request.source(),也就是DSL
①QueryBuilders来构建查询条件
②传入Request.source()的query()方法
3.发送请求,得到结果
4.解析结果(参考JSON结果,从外到内,逐层解析)
match、term、range、bool查询
match语句只需修改QueryBuilders的方法
request.source().query(QueryBuilders.matchQuery("all","如家"));
term、range、bool查询:


@Test
void testBool() throws IOException {
SearchRequest request = new SearchRequest("hotel");
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
boolQuery.must(QueryBuilders.termQuery("city","上海"));
boolQuery.filter(QueryBuilders.rangeQuery("price").gte(50).lte(250));
request.source().query(boolQuery);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
handleResponse(response);
}排序和分页

@Test
void testPageAndSort() throws IOException {
//定义页码、每页大小
int page=1,size=5;
SearchRequest request = new SearchRequest("hotel");
request.source().query(QueryBuilders.matchAllQuery());
//排序 sort
request.source().sort("price", SortOrder.ASC);
//分页 from、size
request.source().from((page-1)*size).size(size);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
handleResponse(response);
}高亮

@Test
void testHighLight() throws IOException {
SearchRequest request = new SearchRequest("hotel");
//准备query
request.source().query(QueryBuilders.matchQuery("name","如家"));
//高亮
request.source().highlighter(new HighlightBuilder().field("name").requireFieldMatch(false));
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
handleResponse(response);
}
private void handleResponse(SearchResponse response){
SearchHits searchHits = response.getHits();
long total = searchHits.getTotalHits().value;
System.out.println("共搜索到"+total+"条数据");
SearchHit[] hits = searchHits.getHits();
for(SearchHit hit:hits){
//获取文档source
String json = hit.getSourceAsString();
//反序列化
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
//获取高亮结果
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
//根据字段名获取高亮结果
if(!CollectionUtils.isEmpty(highlightFields)) {
HighlightField highlightField = highlightFields.get("name");
//获取高亮值
String name = highlightField.getFragments()[0].string();
//覆盖非高亮结果
hotelDoc.setName(name);
}
System.out.println(hotelDoc);
}
}总结:
所有搜索DSL的构建,记住一个API:
SearchRequest的source()方法
高亮结果解析是参考JSON结果,逐层解析
四、黑马旅游案例
酒店搜索和分页
案例1:实现黑马旅游的酒店搜索功能,完成关键字搜索和分页
先实现其中的关键字搜索功能,实现步骤如下:
1.实现实体类、接收前端请求
@Data
public class RequestParams {
private String key;
private Integer page;
private Integer size;
private String sortBy;
}2.定义controller接口,接受页面请求,调用IHostServicce的search方法
请求方式:Post
请求路径:/hotel/list
请求参数:对象,类型为RequestParam
返回值:PageResult,包含两个属性:
①Long total:总条数
②List<HotelDoc> hotels:酒店数据
@Data
@NoArgsConstructor
@AllArgsConstructor
public class PageResult {
private Long total;
private List<HotelDoc> hotels;
}public interface IHotelService extends IService<Hotel> {
PageResult search(RequestParams params);
}@MapperScan("cn.itcast.hotel.mapper")
@SpringBootApplication
public class HotelDemoApplication {
public static void main(String[] args) {
SpringApplication.run(HotelDemoApplication.class, args);
}
@Bean
public RestHighLevelClient client(){
return new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.202.128:9200")
));
}
}@Service
public class HotelService extends ServiceImpl<HotelMapper, Hotel> implements IHotelService {
@Autowired
RestHighLevelClient client;
@Override
public PageResult search(RequestParams params) {
try {
SearchRequest request = new SearchRequest("hotel");
String key=params.getKey();
if(key==null || "".equals(key))
request.source().query(QueryBuilders.matchAllQuery());
else
request.source().query(QueryBuilders.matchQuery("all",key));
int page=params.getPage();
int size=params.getSize();
request.source().from((page-1)*size).size(size);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
return handleResponse(response);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private PageResult handleResponse(SearchResponse response){
SearchHits searchHits = response.getHits();
long total = searchHits.getTotalHits().value;
SearchHit[] hits = searchHits.getHits();
List<HotelDoc> hotels=new ArrayList<>();
for(SearchHit hit:hits){
String json = hit.getSourceAsString();
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
hotels.add(hotelDoc);
}
return new PageResult(total,hotels);
}
}
3.定义IHotelService中的search方法,利用match查询实现根据关键字搜索酒店的信息
添加品牌、城市、星级、价格等过滤功能
步骤:
1.修改RequestParams类,添加brand、city、starName、minPrice、maxPrice等参数
@Data
public class RequestParams {
private String key;
private Integer page;
private Integer size;
private String sortBy;
private String city;
private String brand;
private String starName;
private Integer minPrice;
private Integer maxPrice;
}2.修改search方法的实现,在关键字搜索时,如果brand等参数存在,对其做过滤
过滤条件包括:
city精确匹配
brand精确匹配
starName精确匹配
price范围过滤
注意事项:
多个条件之间是AND关系,组合多条件用BooleanQuery
参数存在才需要过滤,做好非空判断
初始代码:
@Override
public PageResult search(RequestParams params) {
try {
SearchRequest request = new SearchRequest("hotel");
// 构建BooleanQuery
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
//关键字搜索
String key=params.getKey();
if(key==null || "".equals(key))
boolQuery.must(QueryBuilders.matchAllQuery());
else
boolQuery.must(QueryBuilders.matchQuery("all",key));
//条件过滤
//城市条件
if(params.getCity()!=null && !"".equals(params.getCity())){
boolQuery.filter(QueryBuilders.termQuery("city",params.getCity()));
}
//品牌条件
if(params.getBrand()!=null && !params.getBrand().equals("")){
boolQuery.filter(QueryBuilders.termQuery("brand",params.getBrand()));
}
//星级条件
if(params.getStarName()!=null && !params.getStarName().equals("")){
boolQuery.filter(QueryBuilders.termQuery("starName",params.getStarName()));
}
if(params.getMaxPrice()!=null && params.getMinPrice()!=null){
boolQuery.filter(QueryBuilders.rangeQuery("price").gte(params.getMinPrice()).lte(params.getMaxPrice()));
}
request.source().query(boolQuery);
int page=params.getPage();
int size=params.getSize();
request.source().from((page-1)*size).size(size);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
return handleResponse(response);
} catch (IOException e) {
throw new RuntimeException(e);
}
}可以按快捷键 ctrl+alt+m,快速重构代码,抽取冗余部分
@Override
public PageResult search(RequestParams params) {
try {
SearchRequest request = new SearchRequest("hotel");
buildBasicQuery(params,request);
int page=params.getPage();
int size=params.getSize();
request.source().from((page-1)*size).size(size);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
return handleResponse(response);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private void buildBasicQuery(RequestParams params,SearchRequest request) {
// 构建BooleanQuery
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
//关键字搜索
String key= params.getKey();
if(key==null || "".equals(key))
boolQuery.must(QueryBuilders.matchAllQuery());
else
boolQuery.must(QueryBuilders.matchQuery("all",key));
//条件过滤
//城市条件
if(params.getCity()!=null && !"".equals(params.getCity())){
boolQuery.filter(QueryBuilders.termQuery("city", params.getCity()));
}
//品牌条件
if(params.getBrand()!=null && !params.getBrand().equals("")){
boolQuery.filter(QueryBuilders.termQuery("brand", params.getBrand()));
}
//星级条件
if(params.getStarName()!=null && !params.getStarName().equals("")){
boolQuery.filter(QueryBuilders.termQuery("starName", params.getStarName()));
}
if(params.getMaxPrice()!=null && params.getMinPrice()!=null){
boolQuery.filter(QueryBuilders.rangeQuery("price").gte(params.getMinPrice()).lte(params.getMaxPrice()));
}
request.source().query(boolQuery);
}
附近的酒店
前端页面点击定位后,会将你所在的位置发送给后台:

步骤:

1.修改RequestParams参数,接收location字段
2.修改search方法业务逻辑,如果location有值,添加根据geo_distance排序的功能
//排序
String location = params.getLocation();
if(location != null && location.equals("")){
request.source().sort(SortBuilders
.geoDistanceSort("location",new GeoPoint(location))
.order(SortOrder.ASC)
.unit(DistanceUnit.KILOMETERS)
);
}处理定位结果:
1.给HotelDoc添加distance字段
private Object distance;
2.在handleResponse方法中添加如下代码(给hotelDoc注入distance字段):
for(SearchHit hit:hits){
String json = hit.getSourceAsString();
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
Object[] sortValues = hit.getSortValues();
if(sortValues.length>0){
Object sortValue = sortValues[0];
hotelDoc.setDistance(sortValue);
}
hotels.add(hotelDoc);广告置顶
让指定的酒店在搜索结果中排名置顶
我们给需要置顶的酒店文档添加一个标记,然后利用function score给带有标记的文档增加权重

步骤二:
POST /hotel/_update/60935
{
"doc":{
"isAD":true
}
}
POST /hotel/_update/309208
{
"doc":{
"isAD":true
}
}第三步:

//算分控制
FunctionScoreQueryBuilder functionScoreQuery = QueryBuilders.functionScoreQuery(boolQuery, new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{
new FunctionScoreQueryBuilder.FilterFunctionBuilder(
QueryBuilders.termQuery("isAD", true),
ScoreFunctionBuilders.weightFactorFunction(10)
)
});
request.source().query(functionScoreQuery);广告标识效果:

实用篇---第七天

一、数据聚合
聚合的分类
聚合(aggregations)可以实现对文档数据的统计、分析、运算。聚合常见的有三类:
桶聚合:用来对文档做分组
TermAggregation:按照文档字段值分组
Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
度量(Metric)聚合:用来计算一些值,比如:最大值、最小值、平均值等
Avg:求平均值
Max:求最大值
Min:求最小值
Stats:同时求max、min、avg、sum等
管道(pipeline)聚合:其他聚合的结果为聚合做基础
总结:

DSL实现Bucket聚合

桶聚合代码:
GET /hotel/_search
{
"size":0,
"aggs":{
"brandAgg":{
"terms":{
"field": "brand",
"size":20
}
}
}
}运行结果:

默认情况下,Bucket聚合会统计Bucket内的文档数量,记为_count,并且按照_count降序排序
我们可以修改结果排序方式:
GET /hotel/_search
{
"size":0,
"aggs":{
"brandAgg":{
"terms":{
"field": "brand",
"size":20,
"order":{
"_count": "asc"
}
}
}
}
}
默认情况下,Bucket聚合是对索引库的所有文档做聚合,我们可以限定要聚合的文档范围,只要添加query条件即可
GET /hotel/_search
{
"query":{
"range":{
"price":{
"lte":200
}
}
},
"size":0,
"aggs":{
"brandAgg":{
"terms":{
"field": "brand",
"size":10
}
}
}
}
总结:
aggs代表聚合,与query同级,此时query的作用是?
限定聚合的文档范围
聚合必须的三要素:
聚合名称
聚合类型
聚合字段
聚合可配置的属性有:
size:指定聚合结果数量
order:指定聚合结果排序方式
field:指定聚合字段
DSL实现Metrics聚合
例如,我们要求获取每个品牌的用户评分的min、max、avg等值
我们可以利用stats聚合:

代码示例:
GET /hotel/_search
{
"size":0,
"aggs":{
"brandAggs":{
"terms":{
"field": "brand",
"size":20
},
"aggs":{
"scoreAgg":{
"stats":{
"field":"score"
}
}
}
}
}
} 
需求:按照分类好的avg降序排序
GET /hotel/_search
{
"size":0,
"aggs":{
"brandAggs":{
"terms":{
"field": "brand",
"size":20,
"order":{
"scoreAgg.avg": "desc"
}
},
"aggs":{
"scoreAgg":{
"stats":{
"field":"score"
}
}
}
}
}
}
RestAPI实现聚合

发起请求:
@Test
void testAggregation() throws IOException {
SearchRequest request = new SearchRequest("hotel");
request.source().size(0);
request.source().aggregation(AggregationBuilders
.terms("brandAgg")
.field("brand")
.size(20)
);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
System.out.println(response);
}
处理响应:

@Test
void testAggregation() throws IOException {
SearchRequest request = new SearchRequest("hotel");
request.source().size(0);
request.source().aggregation(AggregationBuilders
.terms("brandAgg")
.field("brand")
.size(20)
);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
Aggregations aggregations = response.getAggregations();
Terms brandTerms = aggregations.get("brandAgg");
List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();
for(Terms.Bucket bucket:buckets){
String key = bucket.getKeyAsString();
System.out.println(key);
}
}
多条件聚合
案例:在IUserService中定义方法,实现对品牌、城市、星级的聚合

@Override
public Map<String, List<String>> filters() {
try {
SearchRequest request = new SearchRequest("hotel");
request.source().size(0);
String[] arr = {"brandAgg", "cityAgg", "starAgg"};
String[] fields = {"brand", "city", "starName.keyword"};
for (int i = 0; i < arr.length; i++) {
request.source().aggregation(AggregationBuilders
.terms(arr[i])
.field(fields[i])
.size(100)
);
}
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
Aggregations aggregations = response.getAggregations();
Map<String, List<String>> res = new HashMap<>();
for (int i = 0; i < arr.length; i++) {
List<String> brandList = new ArrayList<>();
Terms arrTerms = aggregations.get(arr[i]);
List<? extends Terms.Bucket> buckets = arrTerms.getBuckets();
for (Terms.Bucket bucket : buckets) {
brandList.add(bucket.getKeyAsString());
}
res.put(fields[i], brandList);
}
return res;
}catch (Exception e){
throw new RuntimeException();
}
} 
带过滤条件的聚合

第一步:
@PostMapping("/filters")
public Map<String, List<String>> getFilters(@RequestBody RequestParams params){
return hotelService.filters(params);
}第二、三步:
buildBasicQuery(params,request);
二、自动补全
安装拼音分词器
①解压
②上传至虚拟机的elasticsearch的plugin目录
③重启elasticsearch
④测试
POST /_analyze
{
"text":["如家酒店还不错"],
"analyzer": "pinyin"
}
自定义分词器
elasticsearch中分词器(analyzer)的组成包含三部分:
character filters:在tokenizer之前对文本进行处理。例如删除字符,替换字符
tokenizer:将文本按照一定的规则切割成词条(term)。例如keyword,就是不分词,还有ik_smart
tokenizer filter:将tokenizer输出的词条做进一步的处理。例如大小写转换、同义词处理、拼音处理等

PUT /test
{
"settings":{
"analysis": {
"analyzer":{
"my_analyzer":{
"tokenizer":"ik_max_word",
"filter":"py"
}
},
"filter":{
"py":{
"type":"pinyin",
"keep_full_pinyin":false,
"keep_joined_full_pinyin":true,
"keep_original":true,
"limit_first_letter_length":16,
"remove_duplicated_term":true,
"none_chinese_pinyin_tokenizer":false
}
}
}
},
"mappings":{
"properties":{
"name":{
"type":"text",
"analyzer": "my_analyzer"
}
}
}
}测试一:
测试代码及结果:
POST /test/_analyze
{
"text":["如家酒店还不错"],
"analyzer": "my_analyzer"
}
测试二:
POST /test/_doc/1
{
"id":1,
"name":"狮子"
}
POST /test/_doc/2
{
"id":2,
"name":"虱子"
}
GET /test/_search
{
"query":{
"match":{
"name":"shizi"
}
}
}

拼音分词器适合在创建倒排索引的时候使用,但不能在搜索的时候使用
==>因此字段在创建倒排索引时应该用my_analyzer分词器;字段在搜索时应该使用ik_smart分词器
PUT /test
{
"settings":{
"analysis": {
"analyzer":{
"my_analyzer":{
"tokenizer":"ik_max_word",
"filter":"py"
}
},
"filter":{
"py":{
"type":"pinyin",
"keep_full_pinyin":false,
"keep_joined_full_pinyin":true,
"keep_original":true,
"limit_first_letter_length":16,
"remove_duplicated_term":true,
"none_chinese_pinyin_tokenizer":false
}
}
}
},
"mappings":{
"properties":{
"name":{
"type":"text",
"analyzer": "my_analyzer",
"search_analyzer": "ik_smart"
}
}
}
}DSL实现自动补全查询
elasticsearch提供了completion suggester查询来实现自动补全功能。这个查询会匹配以用户输入内容开头的词条并返回。为了提高补全查询的效率,对于文档中的类型有一些约束
参与补全查询的字段必须是completion类型
字段的内容一般是用来补全的多个词条形成的数组

代码:
# 自动补全的索引库
PUT /auto-test
{
"mappings":{
"properties": {
"title":{
"type":"completion"
}
}
}
}
# 示例数据
POST /auto-test/_doc
{
"title":["Sonny","WH-1000XM3"]
}
POST /auto-test/_doc
{
"title":["SK-II","PITERA"]
}
POST /auto-test/_doc
{
"title":["Nintendo","switch"]
}测试:
GET /auto-test/_search
{
"suggest":{
"titleSuggest":{
"text":"s",
"completion":{
"field":"title",
"skip_duplicates":true,
"size":10
}
}
}
}
酒店数据自动补全
案例:实现hotel索引库的自动补全、拼音搜索功能
实现思路:
1.修改hotel索引库结构,设置自定义拼音分词器
2.修改索引库的name、all字段,使用自定义分词器
3.索引库添加一个新字段suggestion,类型为completion类型,使用自定义的分词器
4.给HotelDoc类添加suggestion字段,内容包含brand、business
5.重新导入数据到hotel库
一、查看酒店的数据结构
# 查看酒店数据结构
GET /hotel/_mapping二、创建hotel索引库
PUT /hotel
{
"settings":{
"analysis": {
"analyzer": {
"text_analyzer":{
"tokenizer":"ik_max_word",
"filter":"py"
},
"completion_analyzer":{
"tokenizer":"keyword",
"filter":"py"
}
},
"filter": {
"py":{
"type":"pinyin",
"keep_full_pinyin":false,
"keep_joined_full_pinyin":true,
"keep_original":true,
"limit_first_letter_length":16,
"remove_duplicated_term":true,
"none_chinese_pinyin_tokenizer":false
}
}
}
},
"mappings":{
"properties":{
"id":{
"type":"keyword"
},
"name":{
"type":"text",
"analyzer":"text_analyzer",
"search_analyzer": "ik_smart",
"copy_to":"all"
},
"address":{
"type":"keyword",
"index":false
},
"price":{
"type":"integer"
},
"score":{
"type":"integer"
},
"brand":{
"type":"keyword",
"copy_to":"all"
},
"city":{
"type":"keyword"
},
"star_name":{
"type":"keyword"
},
"business":{
"type":"keyword",
"copy_to": "all"
},
"location":{
"type":"geo_point"
},
"pic":{
"type":"keyword",
"index":false
},
"all":{
"type":"text",
"analyzer":"text_analyzer",
"search_analyzer": "ik_smart"
},
"suggestion":{
"type":"completion",
"analyzer": "completion_analyzer"
}
}
}
}三、修改HotelDoc实体类并批处理导入数据
@Data
@NoArgsConstructor
public class HotelDoc {
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String location;
private String pic;
private Object distance;
private Boolean isAD;
private List<String> suggestion;
public HotelDoc(Hotel hotel) {
this.id = hotel.getId();
this.name = hotel.getName();
this.address = hotel.getAddress();
this.price = hotel.getPrice();
this.score = hotel.getScore();
this.brand = hotel.getBrand();
this.city = hotel.getCity();
this.starName = hotel.getStarName();
this.business = hotel.getBusiness();
this.location = hotel.getLatitude() + ", " + hotel.getLongitude();
this.pic = hotel.getPic();
this.suggestion= Arrays.asList(this.brand,this.business);
}
}四、优化自动补全结果
因为查出来的结果如果商圈business有多个,会用、分隔,所以为了自动补全更为智能,可以做优化

if(this.business.contains("、")||this.business.contains("/")){
String[] arr ;
if(this.business.contains("、"))
arr= this.business.split("、");
else
arr=this.business.split("/");
this.suggestion=new ArrayList<>();
this.suggestion.add(this.brand);
Collections.addAll(this.suggestion,arr);
}else
this.suggestion= Arrays.asList(this.brand,this.business);
重新导入数据,优化成功:

RestAPI实现自动补全查询


@Test
void testSuggest() throws IOException {
SearchRequest request = new SearchRequest("hotel");
request.source().suggest(new SuggestBuilder()
.addSuggestion("suggestions", SuggestBuilders.completionSuggestion("suggestion")
.prefix("h")
.skipDuplicates(true)
.size(10)
));
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//解析结果
Suggest suggest = response.getSuggest();
//根据补全查询名称,获取补全结果
CompletionSuggestion suggestions = suggest.getSuggestion("suggestions");
//获取options
List<CompletionSuggestion.Entry.Option> options = suggestions.getOptions();
//遍历
for(CompletionSuggestion.Entry.Option option:options){
String s = option.getText().toString();
System.out.println(s);
}
}实现搜索框自动补全
第一步:在Controller中添加如下方法
@GetMapping("/suggestion")
public List<String> getSuggestions(@RequestParam("key") String prefix){
return hotelService.getSuggestion(prefix);
}第二步:在IHotelService接口中添加对应的方法并实现
@Override
public List<String> getSuggestion(String prefix) {
List<String> list=new ArrayList<>();
try {
SearchRequest request = new SearchRequest("hotel");
request.source().suggest(new SuggestBuilder().addSuggestion("suggestions",
SuggestBuilders.completionSuggestion("suggestion")
.prefix(prefix)
.skipDuplicates(true)
.size(10)
));
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
Suggest suggest = response.getSuggest();
CompletionSuggestion suggestions = suggest.getSuggestion("suggestions");
List<CompletionSuggestion.Entry.Option> options = suggestions.getOptions();
for (CompletionSuggestion.Entry.Option option : options) {
list.add(option.getText().toString());
}
return list;
}catch(IOException e){
throw new RuntimeException(e);
}
}测试效果:

三、数据同步
同步方案分析
elasticsearch中的酒店数据来自于mysql数据库,因此mysql数据发生改变时,elasticsearch也必须跟着改变,这个就是elasticsearch与mysql之间的数据同步
方案一:同步调用

方案二:异步通知

方案三:监听binlog

总结:
方式一:同步调用
优点:实现简单、粗暴
缺点:业务耦合度高
方式二:异步通知
优点:低耦合,实现难度一般
缺点:依赖mq的可靠性
方式三:监听binlog
优点:完全解除服务间耦合
缺点:开启binlog增加数据库负担,实现复杂度高
利用MQ实现mysql与elasticsearch数据同步
案例:利用课前资料提供的hotel-admin项目作为酒店管理的微服务。当酒店数据发生增、删、改时,要求对elasticsearch中数据也要完成相同操作
步骤:
导入课前资料提供的hotel-admin项目,启动并测试酒店数据的CRUD
声明exchange、queue、RoutingKey
在hotel-admin中的增、删、改业务中完成消息发送
在hotel-demo中完成消息监听,并更新elasticsearch中数据
启动并测试数据同步功能
声明队列和交换机

第一步:导入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>第二步:配置rabbitmq
rabbitmq:
host: 192.168.150.101
port: 5672
username: itcast
password: 123321
virtual-host: /第三步:定义常量
public class MqConstants {
/*
* 交换机
* */
public final static String HOTEL_EXCHANGE="hotel.topic";
/*
* 监听新增和修改的队列
* */
public final static String HOTEL_INSERT_QUEUE="hotel.insert.queue";
/*
* 监听删除的队列
* */
public final static String HOTEL_DELETE_QUEUE="hotel.delete.queue";
/*
* 新增或修改的RoutingKey
* */
public final static String HOTEL_INSERT_KEY="hotel.insert";
/*
* 删除的RoutingKey
* */
public final static String HOTEL_DELETE_KEY="hotel.delete";
}第四步:创建消息队列并绑定到交换机上
@Configuration
public class MqConfig {
@Bean
public TopicExchange topicExchange(){
return new TopicExchange(MqConstants.HOTEL_EXCHANGE,true,false);
}
@Bean
public Queue insertQueue(){
return new Queue(MqConstants.HOTEL_INSERT_QUEUE,true);
}
@Bean
public Binding insertQueueBinding(){
return BindingBuilder.bind(insertQueue()).to(topicExchange()).with(MqConstants.HOTEL_INSERT_KEY);
}
@Bean
public Queue deleteQueue(){
return new Queue(MqConstants.HOTEL_DELETE_QUEUE,true);
}
@Bean
public Binding deleteQueueBinding(){
return BindingBuilder.bind(deleteQueue()).to(topicExchange()).with(MqConstants.HOTEL_DELETE_KEY);
}
}发送mq消息
第一步:配置常量(即上一节的MqConstants)
第二步:修改controller的代码
@RestController
@RequestMapping("hotel")
public class HotelController {
@Autowired
private IHotelService hotelService;
@Autowired
private RabbitTemplate rabbitTemplate;
@GetMapping("/{id}")
public Hotel queryById(@PathVariable("id") Long id){
return hotelService.getById(id);
}
@GetMapping("/list")
public PageResult hotelList(
@RequestParam(value = "page", defaultValue = "1") Integer page,
@RequestParam(value = "size", defaultValue = "1") Integer size
){
Page<Hotel> result = hotelService.page(new Page<>(page, size));
return new PageResult(result.getTotal(), result.getRecords());
}
@PostMapping
public void saveHotel(@RequestBody Hotel hotel){
hotelService.save(hotel);
rabbitTemplate.convertAndSend(MqConstants.HOTEL_EXCHANGE,MqConstants.HOTEL_INSERT_KEY,hotel.getId());
}
@PutMapping()
public void updateById(@RequestBody Hotel hotel){
if (hotel.getId() == null) {
throw new InvalidParameterException("id不能为空");
}
hotelService.updateById(hotel);
rabbitTemplate.convertAndSend(MqConstants.HOTEL_EXCHANGE,MqConstants.HOTEL_INSERT_KEY,hotel.getId());
}
@DeleteMapping("/{id}")
public void deleteById(@PathVariable("id") Long id) {
hotelService.removeById(id);
rabbitTemplate.convertAndSend(MqConstants.HOTEL_EXCHANGE,MqConstants.HOTEL_DELETE_KEY,id);
}
}
监听mq消息
第一步:消费者监听队列
@Component
public class HotelListener {
@Autowired
private IHotelService hotelService;
/*
* 监听酒店新增或修改的业务
* */
@RabbitListener(queues = MqConstants.HOTEL_INSERT_QUEUE)
public void listenHotelInsertOrUpdate(Long id){
hotelService.insertById(id);
}
/*
* 监听酒店删除的业务
* */
@RabbitListener(queues = MqConstants.HOTEL_DELETE_QUEUE)
public void listenHotelDelete(Long id){
hotelService.deleteById(id);
}
}第二步:在HotelService中编写对应的方法
@Override
public void deleteById(Long id) {
try {
//准备Request
DeleteRequest request = new DeleteRequest("hotel", id.toString());
//发送请求
client.delete(request, RequestOptions.DEFAULT);
}catch(IOException e){
throw new RuntimeException();
}
}
@Override
public void insertById(Long id) {
try {
//根据id查询酒店数据
Hotel hotel = getById(id);
//转换为文档类型
HotelDoc hotelDoc = new HotelDoc(hotel);
//准备request对象
IndexRequest request = new IndexRequest("hotel").id(hotel.getId().toString());
//准备json文档
request.source(JSON.toJSONString(hotelDoc), XContentType.JSON);
//发送请求
client.index(request, RequestOptions.DEFAULT);
}catch (IOException e){
throw new RuntimeException();
}
}四、elasticsearch集群

ES集群结构
单机的elasticsearch做数据存储,必然面临两个问题:海量数据存储问题、单点故障问题

搭建ES集群
我们计划利用3个docker容器模拟3个es的节点。
①es运行需要修改一些linux系统权限,修改/etc/sysctl.conf文件
vi /etc/sysctl.conf②添加下面的内容
vm.max_map_count=262144③通过sysctl -p使上面的配置生效
sysctl -p运行docker-compose.yml
docker-compose up -ddocker-compose.yml完整内容:
version: '2.2'
services:
es01:
image: elasticsearch:7.12.1
container_name: es01
environment:
- node.name=es01
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es02,es03
- cluster.initial_master_nodes=es01,es02,es03
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- data01:/usr/share/elasticsearch/data
ports:
- 9200:9200
networks:
- elastic
es02:
image: elasticsearch:7.12.1
container_name: es02
environment:
- node.name=es02
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es03
- cluster.initial_master_nodes=es01,es02,es03
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- data02:/usr/share/elasticsearch/data
ports:
- 9201:9200
networks:
- elastic
es03:
image: elasticsearch:7.12.1
container_name: es03
environment:
- node.name=es03
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es02
- cluster.initial_master_nodes=es01,es02,es03集群状态监控:
kibana可以监控es集群,不过新版本需要依赖es的x-pack功能,配置比较复杂
这里推荐使用cerebro来监控es集群状态
找到bin目录,双击cerebro.bat即可运行

进入cerebro管理界面,可以任意输入一个你想管理的地址,比如http://192.168.150.101:9200

绿色的条代表集群很健康:

分片备份(more-->create index)

实线的方框是主分片,虚线的方框是备份分配

集群职责及脑裂
elasticsearch中集群节点有不同的职责划分:

elasticsearch的每个节点角色都有自己不同的职责,因此建议集群部署时,每个节点都有独立的角色
es集群的脑裂:默认情况下,每个结点都是master eligible节点,因此一旦master节点宕机,其他候选节点会选举一个成为主节点。当主节点与其他节点网络故障时,可能发生脑裂问题。
为了避免脑裂,需要要求选票(eligible节点数量+1)/ 2,才能当选为主,因此eligible节点数量最好是奇数。对应配置项是discovery.zen.minimum_master_nodes,在es7.0以后,已经成为默认配置,因此一般不会发生脑裂问题

总结:

分布式新增和查询流程
当新增文档时,应该保存到不同分片,保证数据均衡,那么coordinating node如何确定数据该存储到那个分片呢?
在9200端口插入三条数据:

可以发现,任意三个端口之一都能查到这三条数据:

通过explain命令查看数据到底存储在哪个分片:
{
"explain":true,
"query":{
"match_all":{}
}
}查询结果:
"hits": [
{
"_shard": "[itcast][1]",
"_node": "vf7qm8YERz2UgcLwCpSX9A",
"_index": "itcast",
"_type": "_doc",
"_id": "2",
"_score": 1.0,
"_source": {
"title": "试着插入一条 id = 2"
},
"_explanation": {
"value": 1.0,
"description": "*:*",
"details": []
}
},
{
"_shard": "[itcast][1]",
"_node": "vf7qm8YERz2UgcLwCpSX9A",
"_index": "itcast",
"_type": "_doc",
"_id": "3",
"_score": 1.0,
"_source": {
"title": "试着插入一条 id = 3"
},
"_explanation": {
"value": 1.0,
"description": "*:*",
"details": []
}
},
{
"_shard": "[itcast][2]",
"_node": "C6sNM5bbT2arRKIrOos8iA",
"_index": "itcast",
"_type": "_doc",
"_id": "1",
"_score": 1.0,
"_source": {
"title": "试着插入一条 id = 1"
},
"_explanation": {
"value": 1.0,
"description": "*:*",
"details": []
}
}
] 可以看到虽然是向9200存数据,但是数据会存到不同分片上。
原理如下:

新增文档流程:


总结:
分布式新增如何确定分片?
coordinating node 根据id做hash运算,得到结果对shard数量取余,余数就是对应的分片
分布式查询:
分散阶段:coordinating node将查询请求分发给不同分片
收集阶段:将查询结果汇总到coordinating node,整理并返回给用户
故障转移
集群的master节点会监控集群中的节点状态,如果发现有节点宕机,会立即将宕机节点的分片数据迁移到其他节点,确保数据安全,这个叫做故障转移

演示:
停掉主节点
[root@Soft soft]# docker-compose stop es02
此时集群状态不健康:

短暂等待后可以发现故障节点的数据成功迁移到健康的节点了:

再次查询,数据没有丢失:

重新开启es02
[root@Soft soft]# docker-compose start es02
数据又会从健康分片上转移到es02

总结:
 文章来源:https://www.toymoban.com/news/detail-729275.html
文章来源:https://www.toymoban.com/news/detail-729275.html
至此,springcloud的基础篇完结,恭喜大家通关~❀文章来源地址https://www.toymoban.com/news/detail-729275.html
到了这里,关于黑马程序员---微服务笔记【实用篇】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
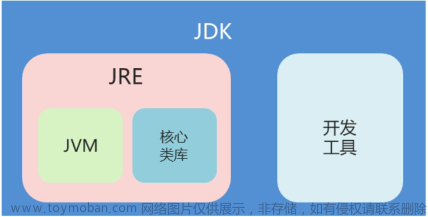
![[学习笔记]黑马程序员python教程](https://imgs.yssmx.com/Uploads/2024/02/723818-1.png)

![[学习笔记]黑马程序员-Hadoop入门视频教程](https://imgs.yssmx.com/Uploads/2024/02/648432-1.png)