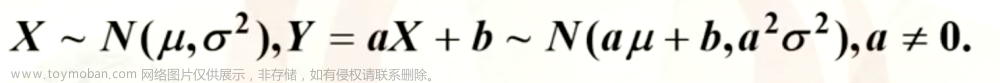综合统计量方法和正态分布的拟合优度检验方法是常用于检验数据是否呈正态分布的两类主要方法。以下是具体的检验方法:
综合统计量方法:
- Shapiro-Wilk检验:基于W统计量,适用于各种样本大小。
- D'Agostino检验:结合了偏度和峰度的信息,适用于中等样本大小。
- Shapiro-Francia检验:使用W'统计量,特别适用于大样本。
- Lilliefors检验:类似于Kolmogorov-Smirnov,但适用于小样本。
- Ryan-Joiner检验:基于观察数据的偏度和峰度,适用于偏态和厚尾分布。
正态分布的拟合优度检验方法:
- Kolmogorov-Smirnov检验:通过比较观察数据与理论正态分布的累积分布函数,适用于大样本。
- Anderson-Darling检验:对尾部分布敏感,用于评估数据是否来自正态分布。
- Cramér-von Mises检验:考虑了所有分布区域的差异,评估观察数据与理论正态分布之间的拟合度。
- D'Agostino's K-squared检验:用于检验数据是否符合正态分布的一种变体。
这些方法提供了多样化的工具,用于全面评估数据是否遵循正态分布。在使用时,你可以根据样本大小、数据特性和分析需求选择适当的方法。在实际应用中,通常使用多种方法相互印证,以获得更可靠的结论。
from scipy import stats
import numpy as np
from statsmodels.stats.diagnostic import lilliefors
# 这个函数的实现是基于Shapiro-Francia检验的一种常见形式,但在特定情况下可能需要根据您的需求进行微调。
def shapiro_francia(data):
n = len(data)
data = np.sort(data)
w = np.corrcoef(data, np.arange(1, n + 1) / (n + 1), rowvar=False)[0, 1]
# 参数a和b通常是Shapiro-Francia检验的推荐值,用于计算这些权重。
a = 1.0378
b = 0.365
statistic = (w / a) ** 2
p_value = 1 - stats.chi2.cdf(statistic, df=2)
return statistic, p_value
# 示例数据,用您的实际数据替换这里的数据
# data = [2.5, 3.0, 2.7, 3.2, 2.8, 3.5, 2.9, 3.7, 2.8, 3.9]
data = [34,56,39,71,84,92,44,67,98,49,55,73,50,62,75,44,88,53,61,25,36,66,77,35]
# 执行Shapiro-Francia正态性检验
# Shapiro-Francia检验通过计算样本数据的统计量来评估数据是否来自正态分布。
statistic, p_value = shapiro_francia(data)
# 输出检验结果
print("Shapiro-Francia Statistic:", statistic)
print("Shapiro-Francia p-value:", p_value)
# 根据p-value进行假设检验
alpha = 0.05 # 设置显著性水平
if p_value < alpha:
print("拒绝零假设,数据不符合正态分布。\n")
else:
print("无法拒绝零假设,数据可能符合正态分布。\n")
print("其他检验验证方法参考:")
# 正态性检验 - Shapiro-Wilk检验
stat, p = stats.shapiro(data)
print("Shapiro-Wilk检验统计量:", stat)
print("Shapiro-Wilk检验p值:", p)
print("\n")
# Anderson-Darling检验
result = stats.anderson(data, dist='norm')
# Anderson-Darling统量
print("Anderson-Darling统计量:", result.statistic)
# 临界值
print("临界值:", result.critical_values)
# 显著性水平
print("显著性水平:", result.significance_level)
# 适配结果
fit_result = result.fit_result
print("适配结果 params:", fit_result.params)
print("适配结果 success:", fit_result.success)
print("适配结果 message:", fit_result.message)
print("\n")
# 执行单样本K-S检验,假设数据服从正态分布
statistic, p_value = stats.kstest(data, 'norm')
print("K-S检验统计量:", statistic)
print("K-S检验p值:", p_value)
print("\n")
# 执行正态分布检验
k2, p_value = stats.normaltest(data)
print(f"normaltest正态分布检验的统计量 (K^2): {k2}")
print(f"normaltest检验p值: {p_value}")
print("\n")
# 执行Jarque-Bera检验
jb_statistic, jb_p_value = stats.jarque_bera(data)
# 输出检验结果
print("Jarque-Bera Statistic:", jb_statistic)
print("Jarque-Bera p-value:", jb_p_value)
print("\n")
# 执行Lilliefors检验
lilliefors_statistic, p_value = lilliefors(data)
# 打印结果
print("lilliefors_statistic =", lilliefors_statistic)
print("Lilliefors p_value =", p_value)
------------
综合统计量方法用于检验数据是否呈正态分布,它综合考虑了数据的各种特征。在正态性检验中,一些常用的综合统计量方法包括:
-
Shapiro-Wilk统计量(W统计量):Shapiro-Wilk检验使用W统计量来评估数据是否符合正态分布。该统计量综合了样本数据的排序顺序和回归分析的概念,对于小样本和大样本均适用。
-
D'Agostino统计量:D'Agostino检验结合了样本的偏度和峰度信息,通过计算一个综合的统计量来判断数据是否呈正态分布。它适用于中等样本大小。
-
Shapiro-Francia统计量(W'统计量):类似于Shapiro-Wilk检验,但使用了修正的统计量W'。它特别适用于大样本数据的正态性检验。
-
Ryan-Joiner统计量:Ryan-Joiner检验基于观察数据的偏度和峰度,通过计算一个综合的统计量来判断数据是否呈正态分布。它对于偏态和厚尾分布的数据更具敏感性。
这些综合统计量方法考虑了数据的不同方面,包括排序顺序、偏度、峰度等,从而提供了更全面的判断数据是否符合正态分布的手段。选择合适的方法通常依赖于样本大小和数据特性。在实际应用中,可以综合使用多种方法来得出更可信的结论。
-------------------------------
拟合优度指的是观察数据与理论分布之间的拟合程度。在正态性检验中,拟合优度主要关注以下几个方面:
-
累积分布函数(CDF)的拟合:观察数据的累积分布函数(ECDF)与理论分布的CDF进行比较。理论上,如果观察数据符合某种理论分布(如正态分布),它们的ECDF应该接近于对应理论分布的CDF。
-
分位数的拟合:观察数据的分位数与理论分布的分位数进行比较。常见的方法包括QQ图(Quantile-Quantile plot),它绘制了观察数据的分位数与理论分布的分位数之间的关系。如果数据符合理论分布,这些点应该落在一条直线上。
-
统计量的拟合:通过计算统计量(如均值、方差等)来比较观察数据与理论分布的差异。通常,如果观察数据符合理论分布,它们的统计量应该接近于理论分布的相应统计量。
-
拟合优度检验统计量:在拟合优度检验中,一些统计量(如Kolmogorov-Smirnov统计量、Anderson-Darling统计量等)用于量化观察数据与理论分布之间的差异,这些统计量的值越小,表示拟合越好。
-
尾部拟合:一些拟合优度检验方法关注观察数据与理论分布在尾部(高分位数或低分位数)的拟合程度,因为在这些区域的拟合往往更难。
通过以上方面的比较和分析,可以判断观察数据是否符合特定的理论分布。在实际应用中,通常会结合多个方面的信息,综合评估拟合优度,以便更全面地了解数据分布的特性。
=======
当处理小样本数据时,Lilliefors检验和Kolmogorov-Smirnov检验有些相似,但Lilliefors检验在计算临界值时考虑了样本大小,因此更适用于小样本场景。这两种检验方法的共同点在于都用于检验观察数据是否来自于特定的理论分布,例如正态分布。
具体来说,Lilliefors检验的步骤如下:
-
计算观察数据的累积分布函数(ECDF):将观察数据按大小排序,计算每个数据点的累积概率。
-
计算Lilliefors统计量:Lilliefors统计量是观察数据ECDF与理论分布的累积分布函数之间的最大差异。该差异通常用来衡量观察数据与理论分布之间的拟合程度。
-
计算临界值:Lilliefors检验根据样本大小和显著性水平(通常为0.05)计算临界值。如果Lilliefors统计量超过了临界值,就拒绝了数据符合理论分布的假设。
总的来说,Lilliefors检验是Kolmogorov-Smirnov检验的一个变种,适用于小样本数据。它的优势在于在小样本情况下,能够更准确地确定数据是否符合特定的分布,如正态分布。
========
当我们讨论综合统计量方法和正态分布的拟合优度检验方法时,我们可以更深入地了解这些方法的具体特点和用途。
综合统计量方法:
-
Shapiro-Wilk检验:
- 特点:适用于各种样本大小,对非正态分布的敏感性较高,对小样本数据较为准确。
- 使用场景:适用于小样本和大样本,特别适用于小样本的正态性检验。
-
D'Agostino检验:
- 特点:结合了偏度和峰度信息,对中等样本数据的正态性检验较为准确。
- 使用场景:适用于中等样本,可以检测数据的偏态和峰度,对正态性的判断更加全面。
-
Shapiro-Francia检验:
- 特点:使用W'统计量,特别适用于大样本,对正态性的判断较为准确。
- 使用场景:适用于大样本,相对于Shapiro-Wilk检验,在大样本下更快速且准确。
-
Ryan-Joiner检验:
- 特点:基于观察数据的偏度和峰度,对偏态和厚尾分布的数据更敏感。
- 使用场景:适用于偏态和厚尾分布的数据,可以捕捉到数据分布的更多特征。
正态分布的拟合优度检验方法:
-
Kolmogorov-Smirnov检验:
- 特点:通过比较观察数据与理论正态分布的累积分布函数,适用于大样本,但对尾部的拟合相对较弱。
- 使用场景:适用于大样本,一般用于初步判断数据是否符合正态分布。
-
Anderson-Darling检验:
- 特点:对尾部分布较为敏感,适用于各种样本大小,对非正态分布的敏感性较高。
- 使用场景:适用于各种样本大小,特别适用于对尾部分布拟合的敏感性要求较高的场景。
-
Cramér-von Mises检验:
- 特点:考虑了所有分布区域的差异,对整体分布拟合的敏感性较高。
- 使用场景:适用于各种样本大小,用于全面评估数据与理论正态分布之间的拟合度。
-
D'Agostino's K-squared检验:文章来源:https://www.toymoban.com/news/detail-729511.html
- 特点:是D'Agostino检验的一种变体,结合了偏度和峰度信息。
- 使用场景:适用于中等样本,对数据的整体分布特征进行评估。
这些方法各自有其特点和适用范围。在选择方法时,需要根据样本大小、数据分布的特性以及研究问题的需求进行权衡和选择。通常,为了提高结果的可靠性,可以综合使用多种方法来进行正态性检验。文章来源地址https://www.toymoban.com/news/detail-729511.html
到了这里,关于正态分布检验的拟合优度法与综合统计量法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!