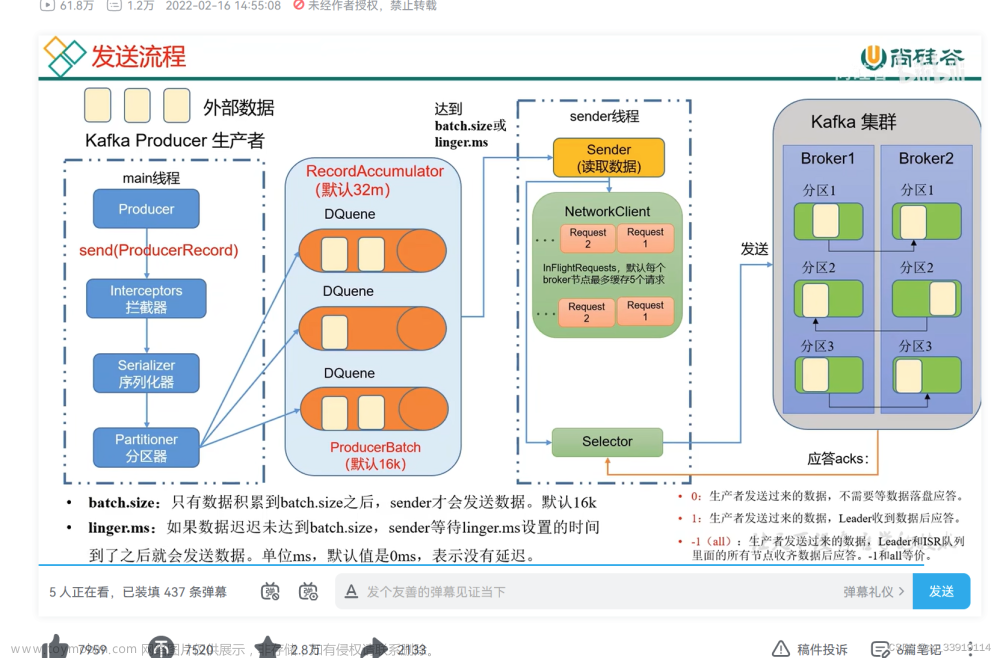
1、从基础的客户端说起
Kafka提供了非常简单的客户端API。只需要引入一个Maven依赖即可:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.13</artifactId>
<version>3.4.0</version>
</dependency>
1.1、消息发送者主流程
然后可以使用Kafka提供的Producer类,快速发送消息。
public class MyProducer {
private static final String BOOTSTRAP_SERVERS = "worker1:9092,worker2:9092,worker3:9092";
private static final String TOPIC = "disTopic";
public static void main(String[] args) throws ExecutionException, InterruptedException {
//PART1:设置发送者相关属性
Properties props = new Properties();
// 此处配置的是kafka的端口
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
// 配置key的序列化类
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
// 配置value的序列化类
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
Producer<String,String> producer = new KafkaProducer<>(props);
CountDownLatch latch = new CountDownLatch(5);
for(int i = 0; i < 5; i++) {
//Part2:构建消息
ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC, Integer.toString(i), "MyProducer" + i);
//Part3:发送消息
//单向发送:不关心服务端的应答。
producer.send(record);
System.out.println("message "+i+" sended");
//同步发送:获取服务端应答消息前,会阻塞当前线程。
RecordMetadata recordMetadata = producer.send(record).get();
String topic = recordMetadata.topic();
int partition = recordMetadata.partition();
long offset = recordMetadata.offset();
String message = recordMetadata.toString();
System.out.println("message:["+ message+"] sended with topic:"+topic+"; partition:"+partition+ ";offset:"+offset);
//异步发送:消息发送后不阻塞,服务端有应答后会触发回调函数
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if(null != e){
System.out.println("消息发送失败,"+e.getMessage());
e.printStackTrace();
}else{
String topic = recordMetadata.topic();
long offset = recordMetadata.offset();
String message = recordMetadata.toString();
System.out.println("message:["+ message+"] sended with topic:"+topic+";offset:"+offset);
}
latch.countDown();
}
});
}
//消息处理完才停止发送者。
latch.await();
producer.close();
}
}
整体来说,构建Producer分为三个步骤:
- 设置Producer核心属性 :Producer可选的属性都可以由ProducerConfig类管理。比如ProducerConfig.BOOTSTRAP_SERVERS_CONFIG属性,显然就是指发送者要将消息发到哪个Kafka集群上。这是每个Producer必选的属性。在ProducerConfig中,对于大部分比较重要的属性,都配置了对应的DOC属性进行描述。
- 构建消息:Kafka的消息是一个Key-Value结构的消息。其中,key和value都可以是任意对象类型。其中,key主要是用来进行Partition分区的,业务上更关心的是value。
- 使用Producer发送消息:通常用到的就是单向发送、同步发送和异步发送者三种发送方式。
1.2、消息消费者主流程
接下来可以使用Kafka提供的Consumer类,快速消费消息。
public class MyConsumer {
private static final String BOOTSTRAP_SERVERS = "worker1:9092,worker2:9092,worker3:9092";
private static final String TOPIC = "disTopic";
public static void main(String[] args) {
//PART1:设置发送者相关属性
Properties props = new Properties();
//kafka地址
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
//每个消费者要指定一个group
props.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
//key序列化类
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
//value序列化类
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
Consumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList(TOPIC));
while (true) {
//PART2:拉取消息
// 100毫秒超时时间
ConsumerRecords<String, String> records = consumer.poll(Duration.ofNanos(100));
//PART3:处理消息
for (ConsumerRecord<String, String> record : records) {
System.out.println("offset = " + record.offset() + ";key = " + record.key() + "; value= " + record.value());
}
//提交offset,消息就不会重复推送。
consumer.commitSync(); //同步提交,表示必须等到offset提交完毕,再去消费下一批数据。
// consumer.commitAsync(); //异步提交,表示发送完提交offset请求后,就开始消费下一批数据了。不用等到Broker的确认。
}
}
}
整体来说,Consumer同样是分为三个步骤:
- 设置Consumer核心属性 :可选的属性都可以由ConsumerConfig类管理。在这个类中,同样对于大部分比较重要的属性,都配置了对应的DOC属性进行描述。同样BOOTSTRAP_SERVERS_CONFIG是必须设置的属性。
- 拉取消息:Kafka采用Consumer主动拉取消息的Pull模式。consumer主动从Broker上拉取一批感兴趣的消息。
-
处理消息,提交位点:消费者将消息拉取完成后,就可以交由业务自行处理对应的这一批消息了。只是消费者需要向Broker提交偏移量offset。如果不提交Offset,Broker会认为消费者端消息处理失败了,还会重复进行推送。
Kafka的客户端基本就是固定的按照这三个大的步骤运行。在具体使用过程中,最大的变数基本上就是给生产者和消费者的设定合适的属性。这些属性极大的影响了客户端程序的执行方式。
2、从客户端属性来梳理客户端工作机制
渔与鱼:Kafka的客户端API的重要目的就是想要简化客户端的使用方式,所以对于API的使用,尽量熟练就可以了。对于其他重要的属性,都可以通过源码中的描述去学习,并且可以设计一些场景去进行验证。其重点,是要逐步在脑海之中建立一个Message在Kafka集群中进行流转的基础模型。
其实Kafka的设计精髓,是在网络不稳定,服务也随时会崩溃的这些作死的复杂场景下,如何保证消息的高并发、高吞吐,那才是Kafka最为精妙的地方。但是要理解那些复杂的问题,都是需要建立在这个基础模型基础上的。
2.1、消费者分组消费机制
这是我们在使用kafka时,最为重要的一个机制,因此最先进行梳理。
在Consumer中,都需要指定一个GROUP_ID_CONFIG属性,这表示当前Consumer所属的消费者组。他的描述是这样的:
public static final String GROUP_ID_CONFIG = "group.id";
public static final String GROUP_ID_DOC = "A unique string that identifies the consumer group this consumer belongs to. This property is required if the consumer uses either the group management functionality by using <code>subscribe(topic)</code> or the Kafka-based offset management strategy.";
既然这里提到了kafka-based offset management strategy,那是不是也有非Kafka管理Offset的策略呢?
另外,还有一个相关的参数GROUP_INSTANCE_ID_CONFIG,可以给组成员设置一个固定的instanceId,这个参数通常可以用来减少Kafka不必要的rebalance。
从这段描述中看到,对于Consumer,如果需要在subcribe时使用组管理功能以及Kafka提供的offset管理策略,那就必须要配置GROUP_ID_CONFIG属性。这个分组消费机制简单描述就是这样的:

生产者往Topic下发消息时,会尽量均匀的将消息发送到Topic下的各个Partition当中。而这个消息,会向所有订阅了该Topic的消费者推送。推送时,每个ConsumerGroup中只会推送一份。也就是同一个消费者组中的多个消费者实例,只会共同消费一个消息副本。而不同消费者组之间,会重复消费消息副本。这就是消费者组的作用。文章来源:https://www.toymoban.com/news/detail-729616.html
与之相关的还有Offset偏移量。这个偏移量表示每个消费者组在每个Partiton中已经消费处理的进度。在Kafka中,可以看到消费者组的Offset记录情况。文章来源地址https://www.toymoban.com/news/detail-729616.html
[oper@worker1 bin]$ ./kafka-consumer-groups.sh --bootstrap-server worker1:9092 --describe --group test
到了这里,关于Kafka收发消息核心参数详解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!