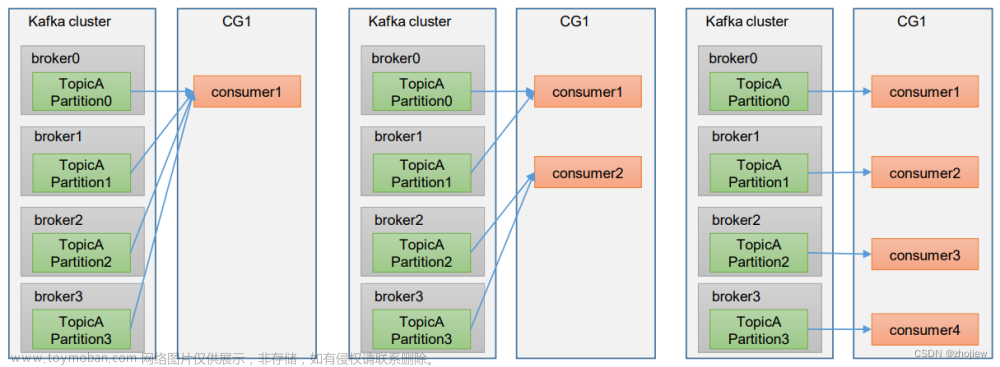
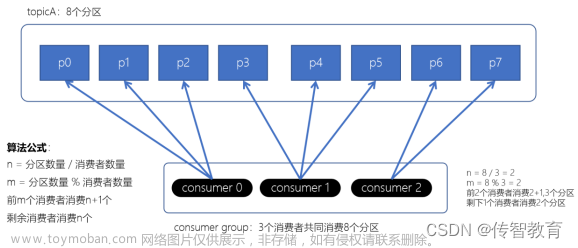
在1个topic中,有3个partition,那么如何保证数据的顺序消费?
生产者在写的时候,可以指定一个 key,被分发到同一个 partition 中去,而且这个 partition 中的数据一定是有顺序的。
消费者从 partition 中取出来数据的时候,也一定是有顺序的。到这里,顺序还是没有错乱的。
但是消费者里可能会有多个线程来并发处理消息,而多个线程并发处理的话,顺序可能就乱掉了。
解决方案
写 n 个 queue,将具有相同key的数据都存储在同一个 queue,然后对于 n 个线程,每个线程分别消费一个 queue 即可,并手动提交位点。由于 kafka consumer 实例不支持多线程同时提交位点,这里采取全局记数器的方式,在每一批次记录的消费过程中,每消费完一条记录则全局记数器加 1,全局记数器等于这一批记录的总条数时提交位点。
在Java中,可以使用多线程和队列来实现对具有相同 key 的数据进行消费,并通过手动提交位点来保证数据的消费。以下是一个带有手动位点提交的解决方案的示例代码:
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
public class DataConsumer {
private Map<String, BlockingQueue<String>> queues;
private Map<String, Integer> offsets;
public DataConsumer(int numThreads) {
queues = new HashMap<>();
offsets = new HashMap<>();
// 创建N个队列和位点
for (int i = 0; i < numThreads; i++) {
BlockingQueue<String> queue = new LinkedBlockingQueue<>();
String key = Integer.toString(i);
queues.put(key, queue);
offsets.put(key, 0);
// 创建并启动消费线程
Thread consumerThread = new Thread(new Consumer(queue, key));
consumerThread.start();
}
}
public void consumeData(String key, String data) {
BlockingQueue<String> queue = queues.get(key);
if (queue != null) {
try {
// 将数据放入对应的队列
queue.put(data);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}
public void commitOffset(String key, int offset) {
offsets.put(key, offset);
System.out.println("Committed offset for key " + key + ": " + offset);
}
private static class Consumer implements Runnable {
private final BlockingQueue<String> queue;
private final String key;
private int offset;
public Consumer(BlockingQueue<String> queue, String key) {
this.queue = queue;
this.key = key;
this.offset = 0;
}
@Override
public void run() {
// 消费队列中的数据
while (!Thread.currentThread().isInterrupted()) {
try {
String data = queue.take();
// 进行消费逻辑
System.out.println("Consumed data: " + data);
offset++;
// 模拟提交位点
if (offset % 10 == 0) {
DataConsumer.getInstance().commitOffset(key, offset);
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}
}
private static DataConsumer instance;
public static synchronized DataConsumer getInstance() {
if (instance == null) {
instance = new DataConsumer(3);
}
return instance;
}
public static void main(String[] args) {
DataConsumer dataConsumer = DataConsumer.getInstance();
// 模拟产生数据
for (int i = 0; i < 30; i++) {
dataConsumer.consumeData(Integer.toString(i % 3), "Data " + (i + 1));
}
}
}
在以上代码中,DataConsumer 类维护了一个 Map 来存储队列和位点的关系。每个消费者线程都有一个对应的位点来记录消费的进度。
在 commitOffset 方法中,根据 key 提交位点的偏移值。
消费线程在每次成功消费一条数据后,更新位点,并判断是否满足提交位点的条件。这里模拟每消费10条数据提交一次位点。文章来源:https://www.toymoban.com/news/detail-729626.html
在 main 方法中,通过 consumeData 方法模拟了产生了30条数据,并将它们放入不同的队列中进行消费。文章来源地址https://www.toymoban.com/news/detail-729626.html
到了这里,关于实现 Kafka 分区内消费者多线程顺序消费的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!