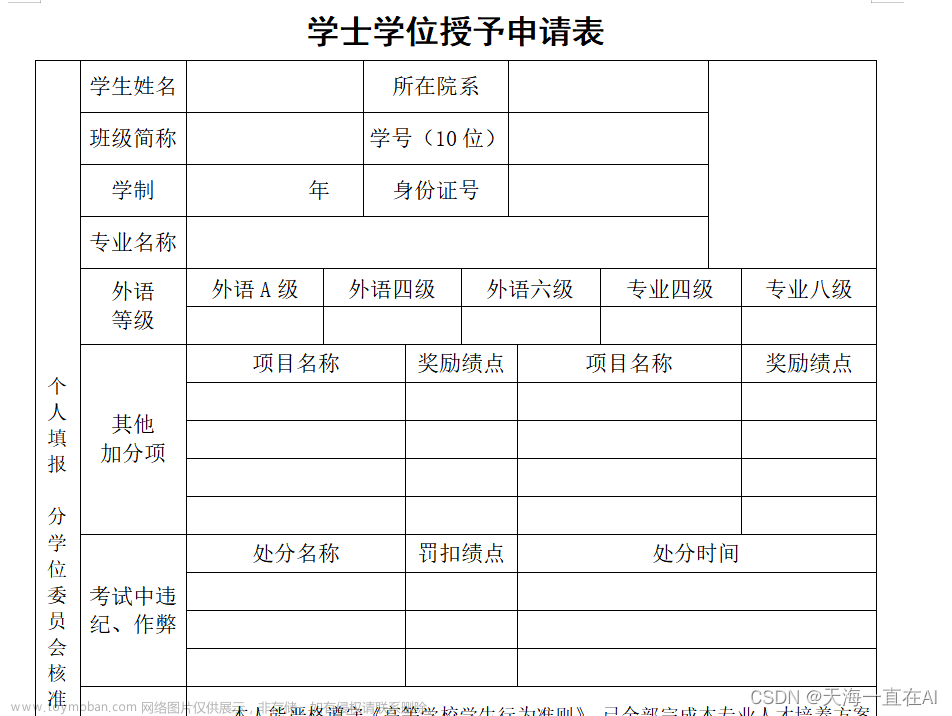
需求:内网通过Excel文件将数据同步到外网的CDH服务器中,将CDH中的文件数据写入hive中。
CDH版本为:6.3.2
spark版本为:2.4
python版本:2.7.5
操作系统:CentOS Linux 7
集群方式:yarn-cluster
一、在linux中将excel文件转换成CSV文件,然后上传到hdfs中。
为何要先转csv呢?主要原因是pyspark直接读取excel的话,涉及到版本的冲突问题。commons-collections-3.2.2.jar 在CDH6.3.2中的版本是3.2.2.但是pyspark直接读取excel要求collections4以上的版本,虽然也尝试将4以上的版本下载放进去,但是也没效果,因为时间成本的问题,所以没有做过多的尝试了,直接转为csv后再读吧。
spark引用第三方包
1.1 转csv的python代码(python脚本)
#-*- coding:utf-8 -*-
import pandas as pd
import os, xlrd ,sys
def xlsx_to_csv_pd(fn):
path1="/home/lzl/datax/"+fn+".xlsx"
path2="/home/lzl/datax/"+fn+".csv"
data_xls = pd.read_excel(path1, index_col=0)
data_xls.to_csv(path2, encoding='utf-8')
if __name__ == '__main__':
fn=sys.argv[1]
print(fn)
try:
xlsx_to_csv_pd(fn)
print("转成成功!")
except Exception as e:
print("转成失败!")
1.2 数据中台上的代码(shell脚本):
#!/bin/bash
#@description:这是一句描述
#@author: admin(admin)
#@email:
#@date: 2023-09-26 14:44:3
# 文件名称
fn="项目投运计划"
# xlsx转换成csv格式
ssh root@cdh02 " cd /home/lzl/shell; python xlsx2csv.py $fn"
# 将文件上传到hfds上
ssh root@cdh02 "cd /home/lzl/datax; hdfs dfs -put $fn.csv /origin_data/sgd/excel/"
echo "上传成功~!"
# 删除csv文件
ssh root@cdh02 "cd /home/lzl/datax; rm -rf $fn.csv"
echo "删除成功~!"
二、pyspark写入hive中
2.1 写入过程中遇到的问题点
2.1.1 每列的前后空格、以及存在换行符等问题。采取的措施是:循环列,采用trim函数、regexp_replace函数处理。
# 循环对每列去掉前后空格,以及删除换行符
import pyspark.sql.functions as F
from pyspark.sql.functions import col, regexp_replace
for name in df.columns:
df = df.withColumn(name, F.trim(df[name]))
df = df.withColumn(name, regexp_replace(col(name), "\n", ""))
2.1.2 个别字段存在科学计数法,需要用cast转换
from pyspark.sql.types import *
# 取消销售订单号的科学记数法
col="销售订单号"
df= df.withColumn(col,df[col].cast(DecimalType(10, 0)))
去掉换行符另一种方法:换行符问题也可以参照这个
2.2 数据中台代码(pyspark)文章来源:https://www.toymoban.com/news/detail-729953.html
# -*- coding:utf-8
# coding=UTF-8
# 引入sys,方便输出到控制台时不是乱码
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" )
# 引入模块
from pyspark.sql.types import IntegerType, DoubleType, StringType, StructType, StructField
from pyspark.sql import SparkSession
from pyspark import SparkContext, SparkConf, SQLContext
import pandas as pd
import pyspark.sql.functions as F
from pyspark.sql.functions import col, regexp_replace
from pyspark.sql.types import *
# 设定资源大小
conf=SparkConf()\
.set("spark.jars.packages","com.crealytics:spark-excel_2.11:0.11.1")\
.set("spark.sql.shuffle.partitions", "4")\
.set("spark.sql.execution.arrow.enabled", "true")\
.set("spark.driver.maxResultSize","6G")\
.set('spark.driver.memory','6G')\
.set('spark.executor.memory','6G')
# 建立SparkSession
spark = SparkSession \
.builder\
.config(conf=conf)\
.master("local[*]")\
.appName("dataFrameApply") \
.enableHiveSupport() \
.getOrCreate()
# 读取cvs文件
# 文件名称和文件位置
fp= r"/origin_data/sgd/excel/项目投运计划.csv"
df = spark.read \
.option("header", "true") \
.option("inferSchema", "true") \
.option("multiLine", "true") \
.option("delimiter", ",") \
.format("csv") \
.load(fp)
# 查看数据类型
# df.printSchema()
# 循环对每列去掉前后空格,以及删除换行符
for name in df.columns:
df = df.withColumn(name, F.trim(df[name]))
df = df.withColumn(name, regexp_replace(col(name), "\n", ""))
# 取消销售订单号的科学记数法
col="销售订单号"
df= df.withColumn(col,df[col].cast(DecimalType(10, 0)))
df.show(25,truncate = False) # 查看数据,允许输出25行
# 设置日志级别 (这两个没用)
sc = spark.sparkContext
sc.setLogLevel("ERROR")
# 写入hive中
spark.sql("use sgd_dev") # 指定数据库
# 创建临时表格 ,注意建表时不能用'/'和''空格分隔,否则会影响2023/9/4和2023-07-31 00:00:00这样的数据
spark.sql("""
CREATE TABLE IF NOT EXISTS ods_sgd_project_operating_plan_info_tmp (
project_no string ,
sale_order_no string ,
customer_name string ,
unoperating_amt decimal(19,2) ,
expected_operating_time string ,
operating_amt decimal(19,2) ,
operating_progress_track string ,
is_Supplied string ,
operating_submit_time string ,
Signing_contract_time string ,
remake string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
""")
# 注册临时表
df.createOrReplaceTempView("hdfs_df")
# spark.sql("select * from hdfs_df limit 5").show() #查看前5行数据
# 将数据插入hive临时表中
spark.sql("""
insert overwrite table ods_sgd_project_operating_plan_info_tmp select * from hdfs_df
""")
# 将数据导入正式环境的hive中
spark.sql("""
insert overwrite table ods_sgd_project_operating_plan_info select * from ods_sgd_project_operating_plan_info_tmp
""")
# 查看导入后的数据
spark.sql("select * from ods_sgd_project_operating_plan_info limit 20").show(20,truncate = False)
# 删除注册的临时表
spark.sql("""
drop table hdfs_df
""")
# 删除临时表
spark.sql("""
drop table ods_sgd_project_operating_plan_info_tmp
""")
关于spark的更多知识,可以参看Spark SQL总结文章来源地址https://www.toymoban.com/news/detail-729953.html
到了这里,关于CDH6.3.2 的pyspark读取excel表格数据写入hive中的问题汇总的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!