前言
Hadoop是一个适合大数据的分布式存储和计算平台。狭义上说Hadoop就是一个框架平台,广义上讲Hadoop代表大数据的一个技术生态圈,包括很多软件框架。而我们的完全分布式,指的是在真实环境下,使⽤多台机器,共同配合,来构建⼀个完整的分布式文件系统。在真实环境中,hdfs中的相关守护进程也会分布在不同的机器中。
一、部署需要的软件
- 虚拟机管理软件:VMware
- 系统:CentOS 7 64 位
- SSH⼯具:MobaXterm
- JDK:jdk-8u221-linux-x64.tar.gz
- Hadoop:hadoop-2.7.1
| 主机名 | IP地址 |
|---|---|
| master | 192.168.206.18 |
| slave1 | 192.168.206.28 |
| slave2 | 192.168.206.38 |
首先要确保本地电脑是否已经安装好了VMware Workstation Pro
下载地址: VMware Workstation Pro | CN
清华大学镜像源:
Index of /centos/7/isos/x86_64/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
注意!注意!注意!
如果虚拟机是从伪分布式复制过来的,最好先把伪分布式的相关守护进程关闭:stop-all.sh,并且保留好自己的伪分布式部署。
二、Hadoop配置环境
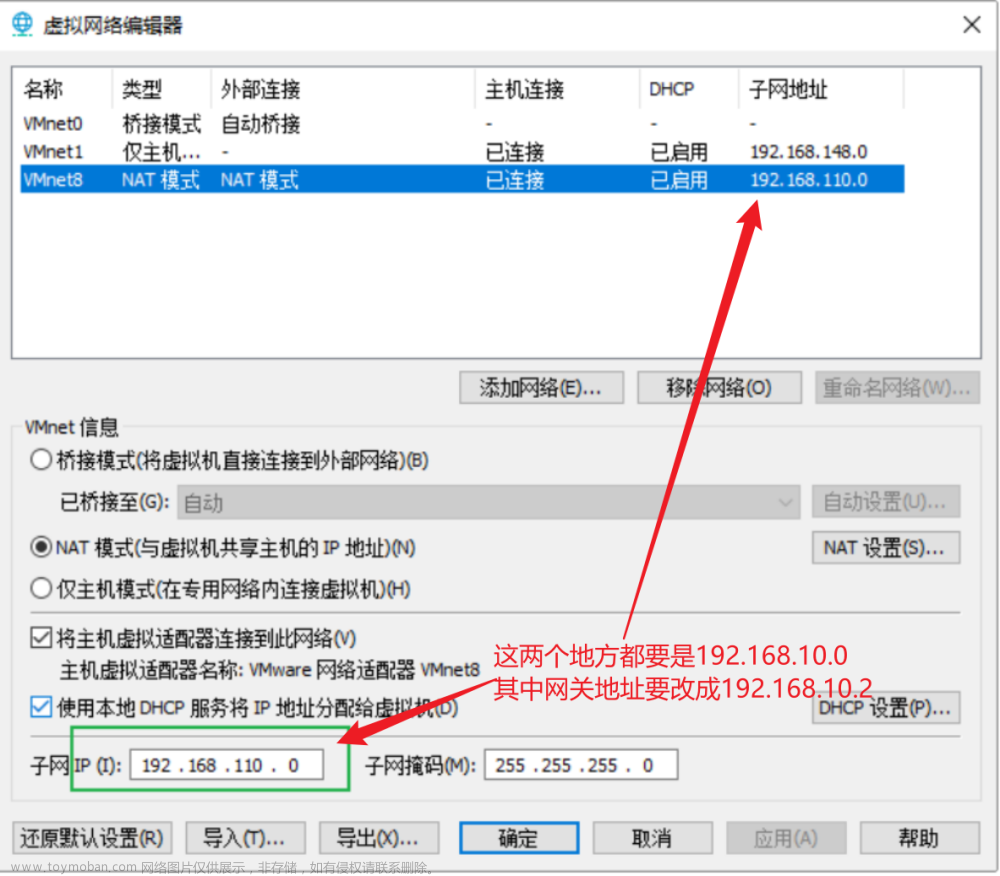
我们设置ip地址首先【Win+R——cmd】使用ipconfig的命令查看VMnet8的ip地址是多少。
例如我的ip地址为192.168.206.1,那么我hadoop的ip地址前3位就需要设置为192.168.206,然后进入到我们的虚拟机里面进行ip地址的设置。
1. 配置网络环境
输入命令vi /etc/sysconfig/network-scripts/ifcfg-ens33进行静态ip地址的设置。
BOOTPROTO=static
ONBOOT=yes
IPADDR=静态ip(这个ip与你的主机在同一个网段)
GATEWAY=网关
NETMASK=子网掩码
DNS1=8.8.8.8
修改以上内容后,Esc键+输入:wq,保存修改的内容。
并重启网络systemctl restart network,让配置生效。
关闭防火墙
关闭防火墙:systemctl stop firewalld
禁用防火墙:systemctl disable firewalld
2. 安装jdk和hadoop
- 在官网下载jdk-8u221-linux-x64.tar.gz与hadoop-2.7.1,并解压到/usr/local路径
- 解压命令:tar -zxvf 包名
- 配置环境变量
2.1 配置jdk环境变量
在/etc/profile文件最后追加两行:
export JAVA_HOME=/usr/local/jdk1.8.0_221
export PATH=$JAVA_HOME/bin:$PATH
添加完之后保存退出输入此命令使配置立刻生效:source /etc/profile
2.2 配置Hadoop环境变量
在/etc/profile文件最后追加:
export HADOOP_HOME=/usr/local/hadoop-2.7.1
export HADOOP_PREFIX=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$HADOOP_HOME/bin$HADOOP_HOME/sbin:$PATH
添加完之后保存退出输入此命令使配置立刻生效:source /etc/profile
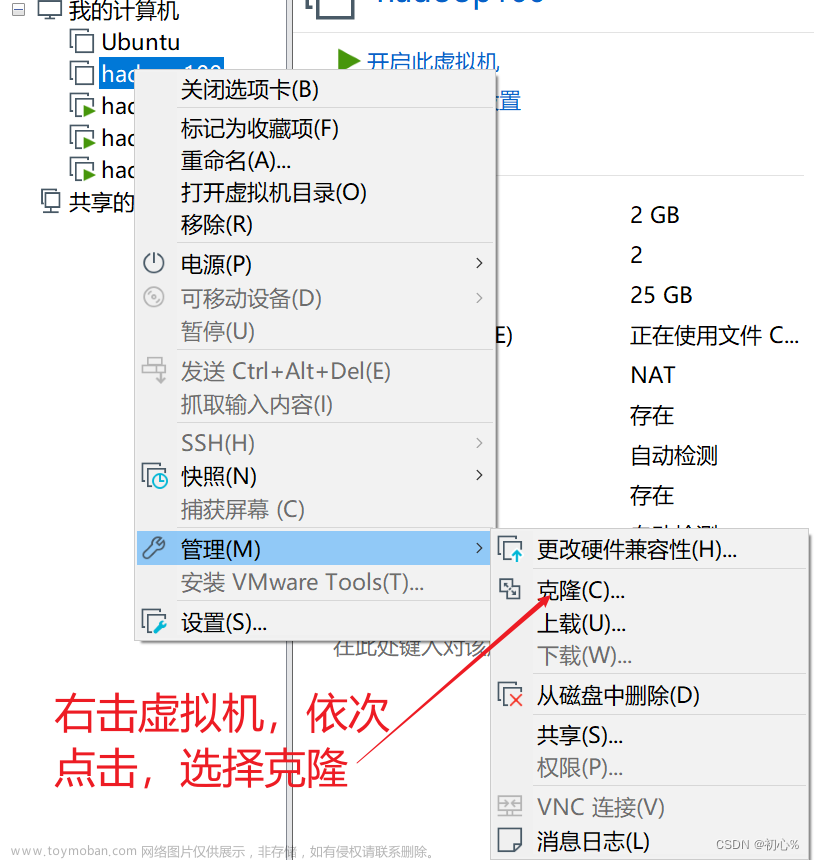
三、准备三台虚拟机
准备三台虚拟机,主机名分别为master、slave1、slave2,而他们的IP地址分别为192.168.206.18、192.168.206.28、192.168.206.38。
1. 修改主机名与IP映射

2. 修改主机上的hadoop相关配置文件
2.1 core-site.xml
由于我们配置Hadoop的环境变量在**$HADOOP_HOME/etc/hadoop**路径下,所以我们首先切换到此路径,在执行:vi core-site.xml,配置文件内容如下:
2.2 hdfs-site.xml
配置文件内容如下:
2.3 yarn-site.xml
配置文件内容如下:
2.4 slaves
配置文件内容如下:
3. 将主机上的hadoop配置文件,同步到其他两个主机上
3.1 使用“scp”对slave1进行同步

3.2 使用“scp”对slave2进行同步

四、配置SSH免密登录及时间同步
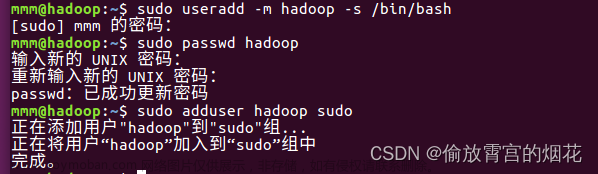
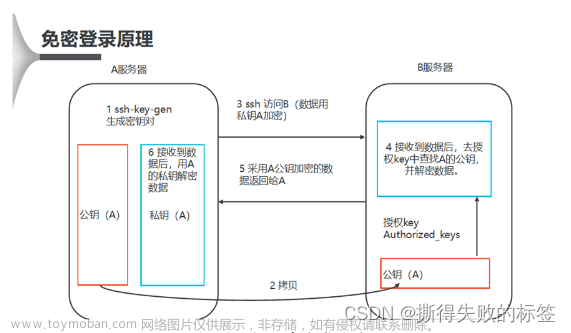
1. 免密登录
1.1在三个机器的目录下执行
ssh-keygen -t rsa
然后需要一直回车确认哦
1.2 ls -all :查看所有文件和文件夹
会在/root/.ssh产生id_rsa和id_rsa.pub文件
查看.ssh目录可以看到id_rsa(私钥), id_rsa.pub (公钥)两个文件
1.3 在master、slave1、slave2中分别执行
(期间需要输入yes ,和对应机器的密码,看提示自行决定)
ssh-copy-id slave1
ssh-copy-id slave2
ssh-copy-id master
2. 时间同步
yum install ntpdate
ntpdate time.ntp.org #同步一个统一的时间(阿里的都可以)
统一设置时间为:
date -s "20230624 00:00:00"
五、NameNode格式化
注意啦!格式化只需要格式化一次哦,若以后启动Hadoop集群时,就不需要再格式化啦。
hdfs namenode -format
最后分别在master、slave1、slave2上执行start-all.sh命令启动hadoop集群就大功告成啦!
六、查看Web管理页面
浏览器访问master的50070端口:http://192.168.206.100:50070
总结
问题:
DataNode不能启动或只启动一个
因多次格式化NameNode导致NameNode和DataNode的clusterID不一致无法启动DataNode。
有时候我们的HDFS出了问题,无法解决,可以通过重新格式化NameNode来搞定停止集群的HDFS和Yarn进程,然后删除hadoop目录下的logs以及data文件。
删除命令为:
rm -rf data
rm -rf logs
《Hadoop》课程学习收获:
本学期我们主要学习了Hadoop的基本概念和架构,包括HDFS、MapReduce等。
1.HDFS:学习如何在HDFS上进行文件读写、权限控制等操作;
2.MapReduce:学习MapReduce编程的基本原理和实现方法;
3.Hive:学习如何使用Hive进行SQL查询,以及如何将数据导入到Hive中进行查询和分析;
4.HaBase:学习将数据按照表、行和列进行存储,使用Zookeeper作为协同管理服务。文章来源:https://www.toymoban.com/news/detail-729992.html
Hadoop是大数据中的基础框架,有着广泛的应用,也是其他大数据框架的基础。总的来说,对于本次Hadoop的完全分布式的搭建还算是挺简单滴啦,若有不对滴还请大家在评论区指正哦!文章来源地址https://www.toymoban.com/news/detail-729992.html
到了这里,关于【Hadoop】安装部署-完全分布式搭建的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!