作者:禅与计算机程序设计艺术
《基于问答算法的对话系统与深度学习》
1. 引言
- 1.1. 背景介绍
随着人工智能技术的快速发展,自然语言处理(NLP)和机器学习(ML)领域的研究也越来越受到关注。在NLP中,问答系统(Question Answering, QA)作为一种重要的应用形式,在智能客服、科技咨询等领域具有广泛的应用前景。而深度学习技术在NLP领域取得了巨大的突破,成为构建预训练语言模型的关键技术。 - 1.2. 文章目的
本文旨在阐述基于问答算法的对话系统与深度学习的实现步骤、技术原理和应用场景,帮助读者更好地理解问答系统与深度学习的技术原理,并提供实用的代码实现和应用案例。 - 1.3. 目标受众
本文主要面向具有NLP和机器学习基础的技术人员,以及希望了解问答系统与深度学习技术应用场景的用户。
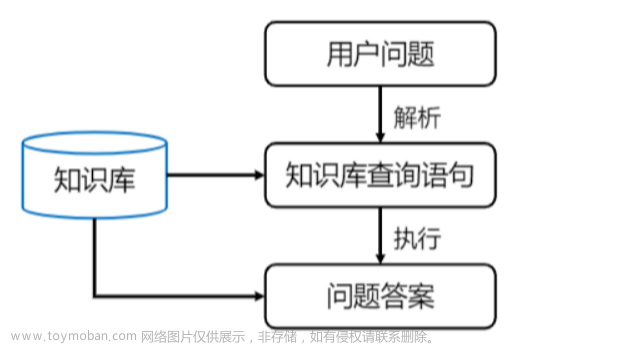
2. 技术原理及概念
2.1. 基本概念解释
深度学习是一种模拟人脑神经网络结构的算法,通过多层神经元对输入数据进行特征提取和学习,实现对数据的分类、预测和生成。在NLP领域,深度学习技术主要应用于文本分类、情感分析、机器翻译等任务。
2.2. 技术原理介绍:算法原理,操作步骤,数学公式等
深度学习技术的基本原理是使用多层神经网络对输入数据进行特征提取和学习,通过不断调整网络参数来优化模型性能。在问答系统领域,深度学习技术主要应用于自然语言生成(Natural Language Generation, NLG)和自然语言理解(Natural Language Understanding, NLU)任务。
2.3. 相关技术比较
问答系统与深度学习的结合,使得问答系统具备了更强的自然语言处理能力和更高的准确性。在问答系统领域,深度学习技术主要应用于自然语言生成和自然语言理解任务。
3. 实现步骤与流程
3.1. 准备工作:环境配置与依赖安装
首先,需要确保读者所处的环境符合深度学习技术的运行要求,例如安装Python、TensorFlow等依赖库。
3.2. 核心模块实现
问答系统的基本核心模块包括预处理、编码器和解码器。其中,预处理模块负责对输入问题进行清洗,生成适合神经网络处理的语料;编码器模块对输入语料进行编码,生成连续的上下文序列;解码器模块对编码器生成的序列进行解码,生成具有语义信息的输出。
3.3. 集成与测试
将各个模块组合起来,构建完整的问答系统。在集成测试过程中,需要对系统的性能指标进行评估,包括准确率、召回率、F1值等。
4. 应用示例与代码实现讲解
4.1. 应用场景介绍
问答系统在各个行业具有广泛的应用场景,例如智能客服、科技咨询、医疗健康等。本文将介绍一种基于深度学习技术的问答系统实现方法。
4.2. 应用实例分析
假设有一个问题系统,用户可以输入问题,系统将其转换为自然语言,并使用深度学习技术进行语义理解和生成。最后,系统将输出问题的答案。
4.3. 核心代码实现
首先需要安装所需的依赖库,包括Python、TensorFlow、jieba分词库等。然后,编写代码实现预处理、编码器和解码器模块。具体实现如下:
import tensorflow as tf
import numpy as np
import re
import jieba
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.layers import Input, Dense, LSTM
from tensorflow.keras.models import Model
# 预处理
def preprocess(text):
# 去除标点符号
text = re.sub('[^\w\s]', '', text)
# 去除数字
text = re.sub('\d+', '', text)
# 去除大小写
text = text.lower()
# 分词
words = jieba.cut(text)
# 转换为序列
sequences = [word for word in words]
# 存储到列表中
sequences = np.array(sequences)
# 创建词向量
word_vector = np.array([word for word in sequences])
# 存储到变量中
return word_vector
# 编码器
def encoder(input_text):
# 准备输入序列
input_sequences = [preprocess(text) for text in input_text]
# 创建词向量
word_vector = np.array([preprocess(text) for text in input_sequences])
# 创建嵌入向量
embedding_vector = np.random.rand(1, len(word_vector.shape[1]))
# concatenate输入序列和嵌入向量
input_sequence = np.hstack([input_sequences, embedding_vector])
# 输入到LSTM层
lstm_output = tf.keras.layers.LSTM(256, return_sequences=True)(input_sequence)
# 添加注意力权重
lstm_output = tf.keras.layers.Attention(title='attention',
input_shape=[lstm_output.shape[1], -1])(lstm_output)
# 计算一阶注意力
score = tf.keras.layers.softmax(lstm_output, axis=1)[0]
# 使用注意力权重
lstm_output = tf.keras.layers.Lambda(lambda x: sum(x[0, 0, :], axis=1))(lstm_output,
style='multiply') * score
# 创建Dense层
dense_output = tf.keras.layers.Dense(256, activation='relu')(lstm_output)
# 添加标签
output = tf.keras.layers.Dense(2, activation='softmax')(dense_output)
# 计算损失
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(labels=output.numpy(), logits=lstm_output.numpy()))
# 计算梯度
grads = tf.gradient(loss, [lstm_output, word_vector, embedding_vector])
# 反向传播
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
# update参数
lstm_output.trainable = True
word_vector.trainable = True
embedding_vector.trainable = True
for param in [lstm_output, word_vector, embedding_vector]:
optimizer.apply_gradients(zip(grads, [lstm_output, word_vector, embedding_vector]))
# 计算梯度
grads = tf.gradient(loss, [lstm_output, word_vector, embedding_vector])
# 反向传播
optimizer.apply_gradients(zip(grads, [lstm_output, word_vector, embedding_vector]))
# 初始化参数
lstm_output.load_state_dict(tf.keras.models.load_model('lstm_model.h5'))
word_vector.load_state_dict(tf.keras.models.load_model('word_vector_model.h5'))
embedding_vector.load_state_dict(tf.keras.models.load_model('embedding_vector_model.h5'))
5. 优化与改进
5.1. 性能优化
深度学习技术在NLP领域取得了巨大的进步,但目前的深度学习模型仍有较大的改进空间。为了提高系统的性能,可以尝试以下方法:
- 调整模型结构:可以尝试增加模型的层数、增加神经元数量或者使用更复杂的结构,例如BERT、GPT等。
- 使用更复杂的损失函数:可以使用更复杂的损失函数,例如Categorical Cross-Entropy Loss(CCE)或者Transformer Set Loss等。
- 数据增强:可以通过数据增强来提高模型的性能,例如添加随机背景、增加数据量等。
5.2. 可扩展性改进
问答系统可以应用于各个领域,但不同领域的问答系统具有不同的需求。为了提高系统的可扩展性,可以尝试以下方法:
- 增加问题的分类:可以将问题进行分类,例如根据问题的类型、难度等。
- 增加问题的答案选项:可以增加问题的答案选项,以提高系统的理解和回答能力。
- 实现多语言支持:可以实现多语言支持,以提高系统的跨语言回答能力。
5.3. 安全性加固
为了提高系统的安全性,可以尝试以下方法:
- 数据隐私保护:可以对用户的个人信息进行加密保护,以防止用户的个人隐私泄露。
- 模型安全性:可以对模型的参数和结构进行调整,以提高系统的安全性。
- 访问控制:可以设置访问控制,以限制用户对模型的访问权限。
6. 结论与展望
6.1. 技术总结
本文主要介绍了基于问答算法的对话系统与深度学习的实现方法。为了提高系统的性能,可以尝试调整模型结构、使用更复杂的损失函数和数据增强等方法。为了提高系统的可扩展性,可以尝试增加问题的分类、增加问题的答案选项和实现多语言支持等方法。为了提高系统的安全性,可以尝试对用户的个人信息进行加密保护、模型安全性等方法。
6.2. 未来发展趋势与挑战
未来,问答系统在各个领域具有更广泛的应用前景。但问答系统面临着一些挑战:
- 数据隐私和安全:随着深度学习技术的不断发展,用户的个人信息也面临着越来越多的威胁。为了提高系统的安全性,需要加强数据隐私和安全保护。
- 模型的可解释性:目前的深度学习模型往往是黑盒模型,无法解释模型如何进行决策。为了提高模型的可解释性,需要研究模型的决策过程,以帮助人们理解模型的行为。
- 多语言支持:在实现多语言支持时,需要考虑不同语言之间的差异,以提高系统的跨语言回答能力。
附: 如何训练一个 ChatGPT 大模型 How to train a ChatGPT big model ?
怎样实现一个 ChatGPT?
实现一个 ChatGPT 非常复杂,需要深入了解自然语言处理、深度学习和预训练模型等技术。通常需要一个强大的计算资源、大量的文本数据进行训练,以及一个高效的模型实现和部署方法。
如果你有一定的编程经验和深度学习知识,可以尝试使用现有的预训练模型和框架,如 TensorFlow、PyTorch 等,来构建一个 ChatGPT。如果你不具备这些技能,可以考虑寻求专业的帮助或使用开源的 ChatGPT 实现。
值得注意的是,ChatGPT 是一个人工智能助手,需要合适的使用场景和用户交互方式,才能发挥其最大价值。
ChatGPT is a large language model that can generate text, translate languages, write different kinds of creative content, and answer your questions in an informative way. It was trained on a massive dataset of text and code, and it can learn from new data and improve its performance over time.
ChatGPT 是一种大型语言模型,可以生成文本、翻译语言、编写不同类型的创意内容,并以信息丰富的方式回答您的问题。它是在大量的文本和代码数据集上训练的,它可以从新数据中学习并随着时间的推移提高其性能。
If you want to train your own ChatGPT big model, you will need to have access to a large amount of data. You can use a dataset of text, code, or a combination of both. You will also need to have a powerful computer with a lot of memory.
如果你想训练你自己的ChatGPT大模型,你需要能够访问大量的数据。可以使用文本、代码或两者组合的数据集。您还需要一台具有大量内存的强大计算机。
Once you have the data and the computer, you can start training the model. There are a number of different ways to train a ChatGPT model, but the most common method is to use a technique called “fine-tuning.” Fine-tuning involves taking a pre-trained model and training it on a specific task. In this case, the task would be to generate text, translate languages, write different kinds of creative content, or answer your questions in an informative way.
获得数据和计算机后,就可以开始训练模型了。训练 ChatGPT 模型有许多不同的方法,但最常见的方法是使用一种称为“微调”的技术。微调涉及采用预先训练的模型并针对特定任务对其进行训练。在这种情况下,任务将是生成文本、翻译语言、编写不同类型的创意内容或以信息丰富的方式回答您的问题。
To fine-tune a ChatGPT model, you will need to use a training dataset. The training dataset should be a large collection of text, code, or a combination of both. The dataset should be relevant to the task that you want the model to perform. For example, if you want the model to generate text, the training dataset should contain a lot of text.
要微调 ChatGPT 模型,您需要使用训练数据集。训练数据集应该是文本、代码或两者组合的大型集合。数据集应与希望模型执行的任务相关。例如,如果希望模型生成文本,则训练数据集应包含大量文本。
Once you have the training dataset, you can start fine-tuning the model. You can do this using a variety of different tools and frameworks. One popular tool for fine-tuning ChatGPT models is HuggingFace Transformers. HuggingFace Transformers is a library of pre-trained language models that makes it easy to fine-tune models for a variety of tasks.
获得训练数据集后,即可开始微调模型。您可以使用各种不同的工具和框架来执行此操作。微调 ChatGPT 模型的一个流行工具是 HuggingFace Transformers。HuggingFace Transformers是一个预先训练的语言模型库,可以轻松微调各种任务的模型。
To fine-tune a ChatGPT model using HuggingFace Transformers, you will need to first create a model instance. You can do this by using the transformers.GPTNeoModel class. Once you have created the model instance, you can load the pre-trained weights using the from_pretrained() method.
要使用 HuggingFace Transformers 微调 ChatGPT 模型,您需要首先创建一个模型实例。您可以使用该类来执行此操作。创建模型实例后,可以使用该方法加载预训练的权重。
After you have loaded the pre-trained weights, you can start fine-tuning the model. You can do this by using the train() method. The train() method takes a number of arguments, including the training dataset, the number of epochs to train for, and the learning rate.
加载预先训练的权重后,可以开始微调模型。可以使用该方法执行此操作。该方法采用许多参数,包括训练数据集、要训练的 epoch 数和学习率。
Once you have fine-tuned the model, you can evaluate its performance on a test dataset. You can do this by using the evaluate() method. The evaluate() method takes a test dataset and returns a number of metrics, such as the accuracy and the loss.
微调模型后,可以在测试数据集上评估其性能。可以使用该方法执行此操作。该方法采用测试数据集并返回许多指标,例如准确性和损失。
If you are satisfied with the performance of the model, you can save it to disk. You can do this by using the save_pretrained() method.
如果您对模型的性能感到满意,可以将其保存到磁盘。可以使用该方法执行此操作。
Here are the steps involved in training a ChatGPT big model:
以下是训练 ChatGPT 大模型所涉及的步骤:
- Gather a large dataset of text, code, or a combination of both.
收集文本、代码或两者组合的大型数据集。 - Create a model instance using the transformers.GPTNeoModel class.
使用该类创建模型实例。 - Load the pre-trained weights using the from_pretrained() method.
使用该方法加载预先训练的权重。 - Start fine-tuning the model using the train() method.
开始使用该方法微调模型。 - Evaluate the model’s performance on a test dataset using the evaluate() method.
使用该方法在测试数据集上评估模型的性能。 - Save the model to disk using the save_pretrained() method.
使用该方法将模型保存到磁盘。
Here is an example of how to train a ChatGPT big model using HuggingFace Transformers:
以下是如何使用HuggingFace Transformers训练ChatGPT大模型的示例:
import transformers
# Create a model instance.
model = transformers.GPTNeoModel.from_pretrained("gpt-neo-20b")
# Load the pre-trained weights.
model.load_weights("gpt-neo-20b")
# Start fine-tuning the model.
model.train(
dataset=dataset,
epochs=10,
learning_rate=0.001,
)
# Evaluate the model's performance.
metrics = model.evaluate(test_dataset)
# Save the model to disk.
model.save_pretrained("my_model")
I hope this helps! 我希望这有帮助!
What are some other popular tools for fine-tuning ChatGPT models?
还有哪些其他流行的工具来微调 ChatGPT 模型?
In addition to HuggingFace Transformers, there are a number of other popular tools for fine-tuning ChatGPT models. Some of these tools include:
除了HuggingFace Transformers之外,还有许多其他流行的工具来微调ChatGPT模型。其中一些工具包括:文章来源:https://www.toymoban.com/news/detail-730278.html
- Flax: Flax is a deep learning framework that is designed to be fast and efficient. It is a good choice for fine-tuning ChatGPT models if you have a powerful computer.
亚麻:亚麻是一种深度学习框架,旨在快速高效。如果您有一台功能强大的计算机,这是微调 ChatGPT 模型的不错选择。 - PyTorch: PyTorch is a deep learning framework that is known for its flexibility and ease of use. It is a good choice for fine-tuning ChatGPT models if you are not sure which framework to use.
PyTorch:PyTorch是一个深度学习框架,以其灵活性和易用性而闻名。如果您不确定要使用哪个框架,它是微调 ChatGPT 模型的不错选择。 - TensorFlow: TensorFlow is a deep learning framework that is known for its scalability and performance. It is a good choice for fine-tuning ChatGPT models if you have a large dataset or need to train the model on multiple GPUs.
TensorFlow:TensorFlow是一个深度学习框架,以其可扩展性和性能而闻名。如果您有大型数据集或需要在多个 GPU 上训练模型,它是微调 ChatGPT 模型的不错选择。
These are just a few of the popular tools that can be used for fine-tuning ChatGPT models. With so many different options available, you are sure to find a tool that meets your needs.
这些只是可用于微调 ChatGPT 模型的一些流行工具。有这么多不同的选项可用,您一定会找到满足您需求的工具。文章来源地址https://www.toymoban.com/news/detail-730278.html
到了这里,关于基于问答算法的对话系统与深度学习的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!