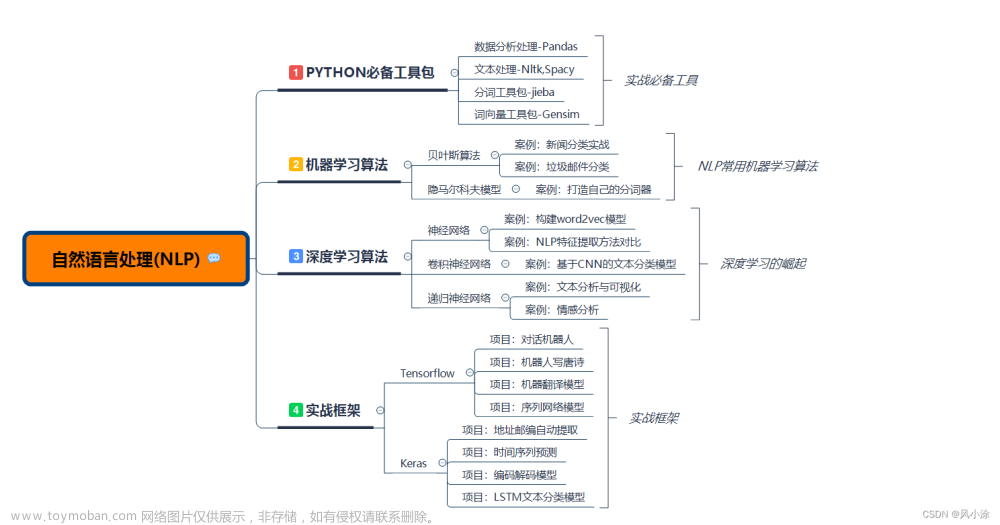
常见NLP任务
-
Word Segmentation 分词 – Tokenization
-
Stem extraction 词干提取 - Stemming
-
Lexical reduction 词形还原 – Lemmatization
-
Part of Speech Tagging 词性标注 – Parts of Speech
-
Named entity recognition 命名主体识别 -NER
-
Chunking 分块 -Chunking
-
语音识别:也称为语音转文本,用于将语音数据以可靠的方式转换为文本数据。 任何遵循语音命令或回答口述问题的应用都需要语音识别功能。 语音识别的挑战性在于人们的说话方式 — 语速快,含糊不清,各种重音、语调和口音,以及语法常常不正确。
-
词性标注:也称语法标注,这个过程按照用法和上下文确定特定单词或文本片段的词性。 “I can make a paper plane” 中 “make” 的词性为动词,“What make of car do you own?” 中 “make” 为名词。
-
关键词提取:
-
语块提取:
-
情绪分析,尝试从文本中提取主观特质,例如,态度、情绪、讽刺、困惑和怀疑。
-
词义消歧:用于对多义单词选择含义,通过语义分析过程确定单词在特定上下文中最准确的意思。 例如,词义消歧可帮助区分动词 “make” 在 “make the grade”(达到)和 “make a bet”(做出)中的含义。
-
命名实体识别 ,简称 NEM,用于将单词或短语识别为有意义的实体。 NEM 将"Kentucky"识别为地点,将 “Fred” 识别为男性的名字。
-
指代消解,用于确定两个单词是否以及何时指代同一实体。 最常见的例子是确定某个代词所指的人或物体(例如,"她"指玛丽),但也可能涉及识别文本中的隐喻或习语(例如,"熊"有时并不表示动物,而是指体型魁梧、体毛较多的人)。
-
自然语言生成,有时被视为语音识别或语音转文本的逆操作;该任务用于将结构化信息转化为人类语言。
常见NLP工具
英文NLP工具
-
NTLK:Natural Language Toolkit是一个用于构建Python程序以处理人类语言数据的平台。它包括词法分析、命名实体识别、标记化、词性标注、句法分析和语义推理。它还提供了一些很好的入门资源。但是,由于 NLTK 在处理大数据时会占用大量资源,因此推荐用于简单项目。 -
TextBlob:TextBlob构建在NLTK的基础上,就像是一个扩展,简化了NLTK的许多功能,它为任务提供了一个易于理解的界面,包括情感分析、词性标注和名词短语提取等。TextBlob是一个推荐给初学者的自然语言处理工具,它也具有可扩展性。 -
SpaCy:SpaCy是一个流畅、快速、高效的开源库,由Cython编写。它具有一个简单的API、预训练的词向量、11 种语言的 23 个统计模型、用于语法和NER的内置可视化工具,它的更新时间表也非常一致。 -
Stanford CoreNLP:CoreNLP用于对文本片段进行语言分析。它提供了 7 种语言的支持,可扩展性使其成为一个很好的自然语言处理工具,可用于信息抓取、聊天机器人训练以及文本处理和生成。需要说明的是,它是按照GNU通用公共许可证 V3 许可的,因此在构建任何专用软件时,都需要商业许可证。 -
GenSim:GenSim是一个用于自然语言处理的免费Python库,是主题建模和文档相似性比较的推荐选项。此外,它还提供了可扩展的统计语义和语义结构分析。GenSim具有高水平的处理速度和处理大量文本的能力。 -
PyTorch-Transformers:该NLP库包含了NLP的预训练模型。它具有PyTorch实现、预训练的模型权重、使用脚本和转换工具,包括BERT、GPT-2、Transformer-XL和RoBERTa。
中文NLP工具
- jieba
“结巴”中文分词:做最好的 Python 中文分词组件
“Jieba” (Chinese for “to stutter”) Chinese text segmentation: built to be the best Python Chinese word segmentation module.
特点——支持三种分词模式:
- 精确模式,试图将句子最精确地切开,适合文本分析;
- 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
- 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
- 支持繁体分词
- 支持自定义词典
- SnowNLP
SnowNLP是一个python写的类库,可以方便的处理中文文本内容,是受到了TextBlob的启发而写的,由于现在大部分的自然语言处理库基本都是针对英文的,于是写了一个方便处理中文的类库,并且和TextBlob不同的是,这里没有用NLTK,所有的算法都是自己实现的,并且自带了一些训练好的字典。注意本程序都是处理的unicode编码,所以使用时请自行decode成unicode。
Features
- 中文分词(
Character-Based Generative Model) - 词性标注(
TnT 3-gram隐马) - 情感分析(现在训练数据主要是商品评论(5w+),所以对其他的一些可能效果不是很好,
支持添加自定义数据集训练) - 文本分类(
Naive Bayes) - 转换成拼音(
Trie树实现的最大匹配) - 繁体转简体(
Trie树实现的最大匹配) - 提取文本关键词(
TextRank算法) - 提取文本摘要(
TextRank算法) tf,idf-
Tokenization(分割成句子) - 文本相似(
BM25) - 支持
python3
- pyhancp
pyhanlp: Python interfaces for HanLP
自然语言处理工具包HanLP的Python接口, 支持自动下载与升级HanLP,兼容py2、py3。
安装
pip install pyhanlp文章来源:https://www.toymoban.com/news/detail-730282.html
注意pyhanlp安装之后使用的时候还会自动下载相关的数据文件,zip压缩文件600多M,速度有点慢,时间有点长文章来源地址https://www.toymoban.com/news/detail-730282.html
- pyltp
pyltp是 语言技术平台(Language Technology Platform,LTP) 的 Python 封装,提供了分词,词性标注,命名实体识别,依存句法分析,语义角色标注的功能。
到了这里,关于自然语言处理NLP:LTP、SnowNLP、HanLP 常用NLP工具和库对比的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!