一、优化步骤
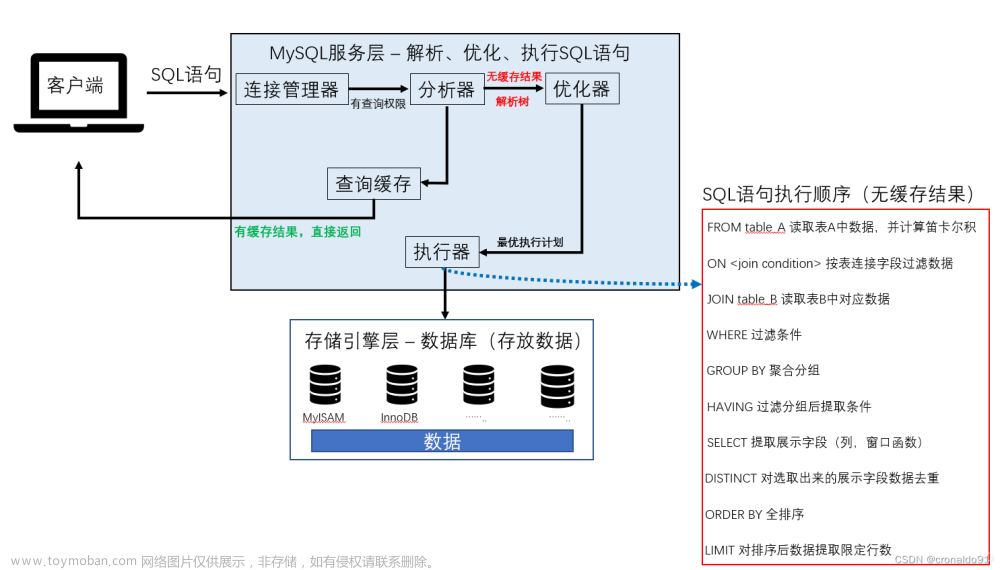
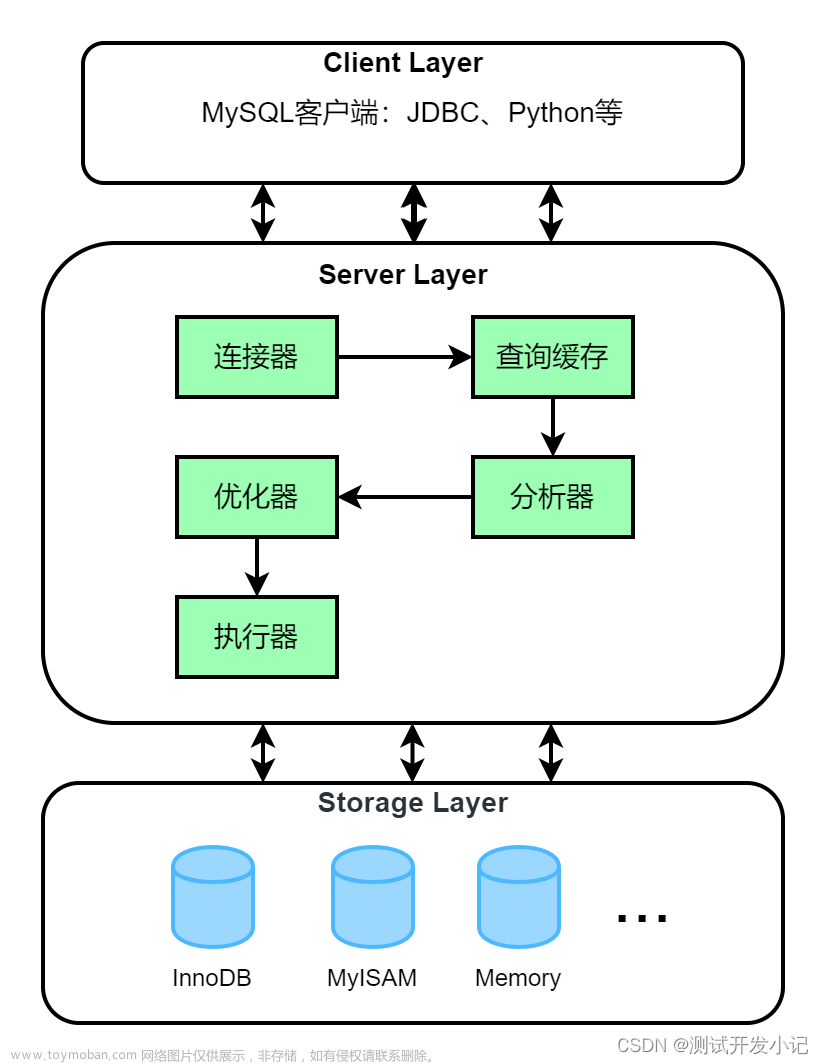
(1)通过SQL监控、请求、日志等找出耗时的SQL语句;
(2)使用Explain方式查看SQL耗时的具体原因;
(3)根据实际情况解决:索引、缓存、左右连接
二、Explain
- select_type:简单查询or复杂查询?simple、primary、subquery、deriveer、union。
- type:SQL关联类型,system > const > eq_ref > ref > range > index > All。一般达到range就行,最好达到ref级别。
- keys和key_len:具体使用到哪些索引及索引长度。
- extra:记录额外信息,如使用覆盖索引(Using index)、使用临时表、使用外部排序(Using filesort)、使用某些聚合函数等等.
Type级别
system/const:如id=1这种常量 ;
eq_ref:主键或联合主键被使用且返回一条;
ref:使用普通索引或唯一索引的部分前缀,可能找到多个值(如:name='zhangsan');
range:使用一个索引检索某个范围,如in、between、大于等等操作;
index:扫描全索引拿到结果,一般是扫描某个二级索引(唯一索引、普通索引、前缀索引等索引属于二级索引)。
ALL:全表扫描。
三、索引
索引本质上是方便MySQL高效获取数据的数据结构。
(一)索引的分类
- 数据结构维度: B+树、Hash索引、全文索引、R-Tree索引。
- 物理存储维度: 聚集索引、非聚集索引。
- 逻辑存储维度: 主键索引、普通索引、联合索引、唯一索引、空间索引。
唯一索引:索引值唯一,允许有null值。
主键索引:特殊的唯一索引,一个表只能有一个主键索引,且不能有null值。
联合索引:在多个字段上创建索引,遵循最左前缀原则。
聚簇索引:正文内容就是按照一定规则排序的目录,如B+树,按照索引排序,一个表只能有一个,存储记录物理连续。文章来源:https://www.toymoban.com/news/detail-730347.html
非聚簇索引:目录是目录,正文纯粹是正文,不按照索引排序,一个表可以有多个,存储记录物理不连续。文章来源地址https://www.toymoban.com/news/detail-730347.html
(二)索引使用的注意事项
- 索引不能包含null,否则无效;
- 索引上不能使用not in和<>操作;
- 不要在索引列上进行运算,会导致索引失效全表扫描;
- 查询使用多个列时可以建组合索引,查询时要符合最左前缀原则;
- 列长度过长时使用短索引,比如varchar2(100)的列可以使用列的前10个字段作索引;
- 控制索引的数量,过多的索引会消耗性能。
四、细节
- in/exists:in(适合子表比主表小的情况)、exists(适合子表比主表大的情况),尽可能让小表驱动大表。
- not in/not exists:not in(内外表全表扫描),not exists(无论跟大表小表都会用到表索引)。
- =和!=:尽量不使用!=避免全表扫描。
- like:左模糊匹配使用索引,全模糊匹配不使用索引。
- select:避免使用select *。
- union all/union:union需去重效率低,union all不去重效率高。
- 用连接代替子查询,避免子查询产生的临时表。
- join:join的表不宜太多。left join是左表驱动右表,inner join会自动小表驱动大表。
到了这里,关于【MySQL】sql如何优化?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!