Ubuntu 20.0.4 Hadoop3.3.2 安装与配置全流程保姆级教程
准备工作
我下载的压缩包是基于 Windows 系统 x86 指令集的,如果你是苹果电脑可能需要选择 ARM 版本
3.21 更新:hadoop 某些功能不支持 JDK11 及以上版本(如网页管理无法查看文件系统),所以下载时选择 JDK8,官网需要登陆甲骨文账号下载
- 全新的 ubuntu 虚拟机
https://ubuntu.com/download/desktop - JDK 压缩包(for linux x64 Compressed Archive)
https://www.oracle.com/java/technologies/downloads/ - Hadoop 压缩包(Binary download)
https://hadoop.apache.org/releases.html - 充分使用 VMware 虚拟机的快照功能,在出错时进行回档
- 你的双手以及专注认真的美好品格
一、配置你的新系统
此时我使用的是刚装好的全新虚拟机,后面的流程以及截图我会全部使用此虚拟机重进操作,如果你已经拥有配置良好的虚拟机可以在目录跳转到你需要的章节
1. 更换国内源并更新软件
进入新系统后会提示你更新软件,这时我们先选择跳过,因为速度很慢。为了提升软件更新的速度,建议使用国内源,可大幅提升更新速度,我们点击桌面左下角的全部软件 点击紫色的这个图标进入软件与更新设置
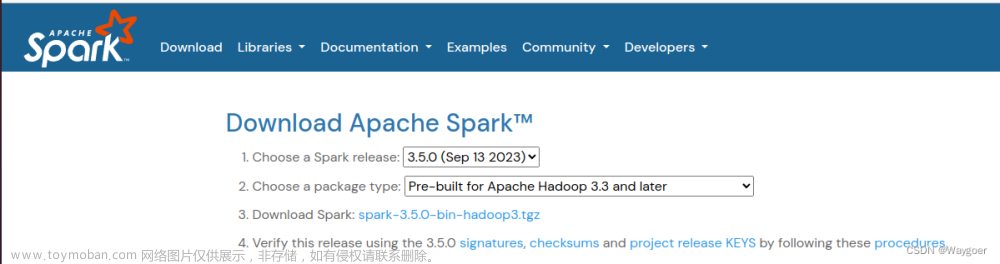
点击紫色的这个图标进入软件与更新设置 在 Download from 选择框点击 Other 选项
在 Download from 选择框点击 Other 选项 点击 Select Best Server 自动寻找最佳服务器,根据我自己的测试,直接在这里选择就好,不需要去改文件
点击 Select Best Server 自动寻找最佳服务器,根据我自己的测试,直接在这里选择就好,不需要去改文件
等待查询完毕 完成后直接点击 Choose Server
完成后直接点击 Choose Server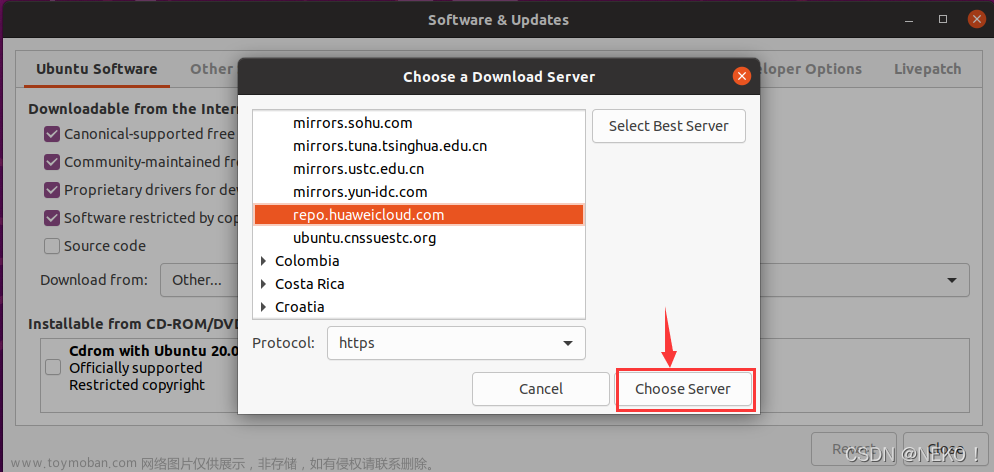 点击 Reload 更新依赖
点击 Reload 更新依赖 关闭设置界面回到桌面,再次点击左下角,这次打开银色的这个软件更新器
关闭设置界面回到桌面,再次点击左下角,这次打开银色的这个软件更新器 更新软件,等待更新完成,我这里能跑到十几兆每秒的速度,都没来得及截图就进入到了安装步骤
更新软件,等待更新完成,我这里能跑到十几兆每秒的速度,都没来得及截图就进入到了安装步骤
更新完成后选择立即重启
软件更新完成
2. 将事先准备的压缩包复制到虚拟机
根据自己的喜好选择一个位置存放我们准备好的压缩包,我选择放在用户主文件夹下的 Downloads 文件夹下
3. 其他注意事项
- 在你自定义你的虚拟机设置时做好不要更换你的桌面图片,如果你直接从主机上找来张图片放进虚拟机并设为壁纸,之后重启登陆进入系统可能会导致黑屏,具体原因不详,我自己因为这种原因重装了两次系统(属实大坑)
- 安装过程中遇到一些诸如权限不足时尽量使用管理员身份执行,而不要去随意改动系统文件夹的归属权
- 本文会使用系统自带的编辑器进行文件的修改,如果不习惯可以安装一个 VS Code 修改文件很方便,权限不足时可以输入管理员密码直接保存更改
- 每完成一部分配置最好保存一个虚拟机快照,在后续配置出错时能回档
二、安装与配置 Java 环境
1. 解压 JDK 压缩包并移动位置
在之前存放压缩包的文件夹右键打开菜单,选择在终端打开
3.21更新:后续测试发现网页管理 hdfs 文件时出现错误,所以 JDK 版本更改为 1.8.0_x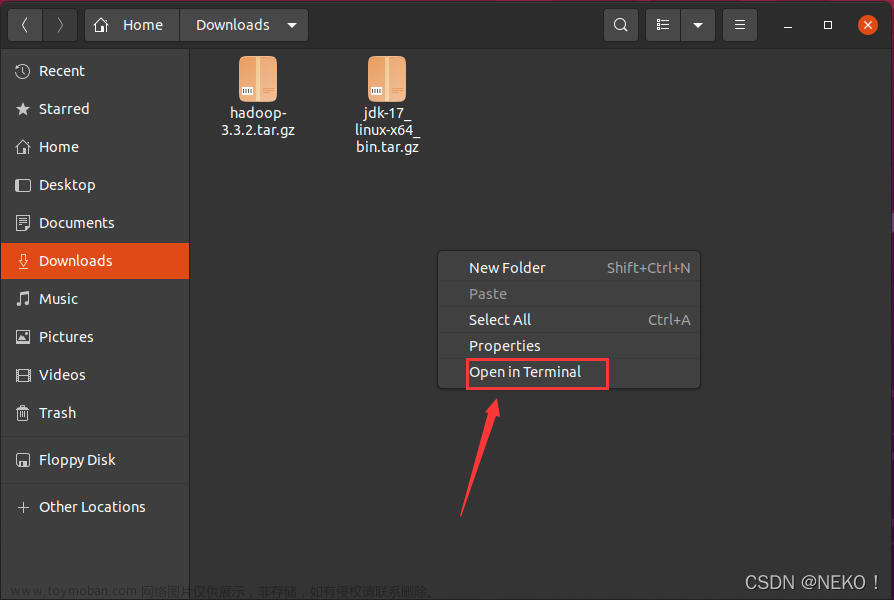
使用指令 tar -zxvf jdk-17_linux-x64_bin.tar.gz 解压 JDK 压缩包(后面的文件名是你自己下载的压缩文件名)
注意不同压缩格式解压指令不同,我以通常情况下的 tar.gz 压缩包为例
解压完成后原目录会出现解压后的文件夹
继续在终端输入指令 sudo mv jdk-17.0.2 /usr/java 将解压后的文件夹移动到 /usr/java 下(需要输入管理员密码)
检查移动是否成功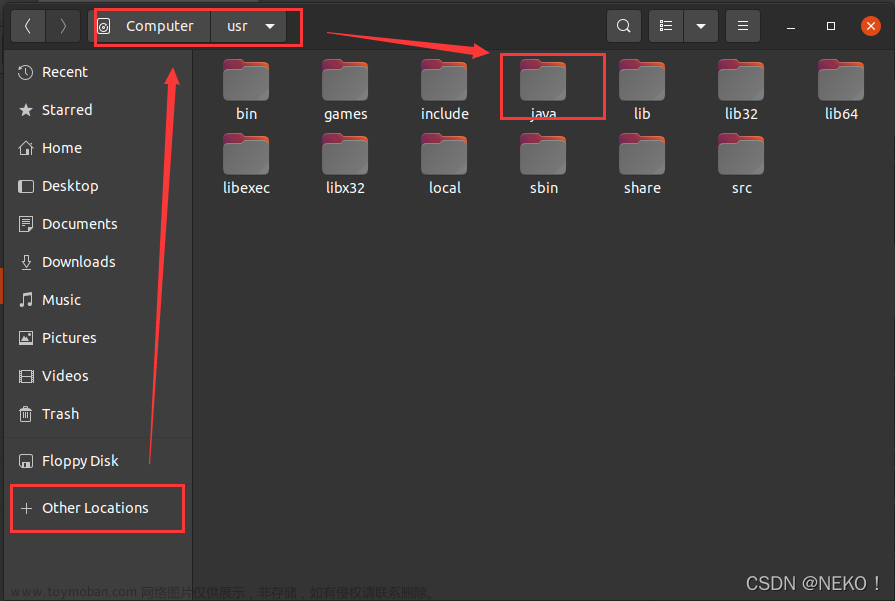
2. 配置环境变量
打开 Home 文件夹,在右上角选项中选中显示隐藏文件
找到名为 .profile 的文件,用文本编辑器打开它,然后在末尾添加如下代码
export JAVA_HOME=/usr/java
# JDK8 添加 JRE_HOME 和 CLASSPATH 配置
export JRE_HOME=$JAVA_HOME/jre
CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin:$PATH
注意不要多空格或少空格,建议直接复制,修改完成后点击 Save 进行保存
下面图片与上面代码不一致,请以上述代码为准
终端输入 source ~/.profile 应用我们配置的环境变量
建立系统软链接sudo update-alternatives --install /usr/bin/javac javac /usr/java/bin/javac 1sudo update-alternatives --install /usr/bin/javac java /usr/java/bin/java 1
3. 检查安装
终端输入 java --version 或 java -version 检查是否配置成功,出现下面的 java 版本提示说明配置成功
3.21更新:为兼容 Hadoop,Java 版本更改为 Java 1.8.0_x
三、安装与配置 Hadoop
1. 解压 Hadoop 压缩包并移动位置
我们回到存放压缩包的文件夹,同样右键选择在终端打开
使用指令 tar -zxvf hadoop-3.3.2.tar.gz 解压压缩包,目录下会出现解压后的文件夹
继续使用指令 sudo mv hadoop-3.3.2 /usr/hadoop 将文件夹移动到 /usr/hadoop 目录下(需要管理员密码)
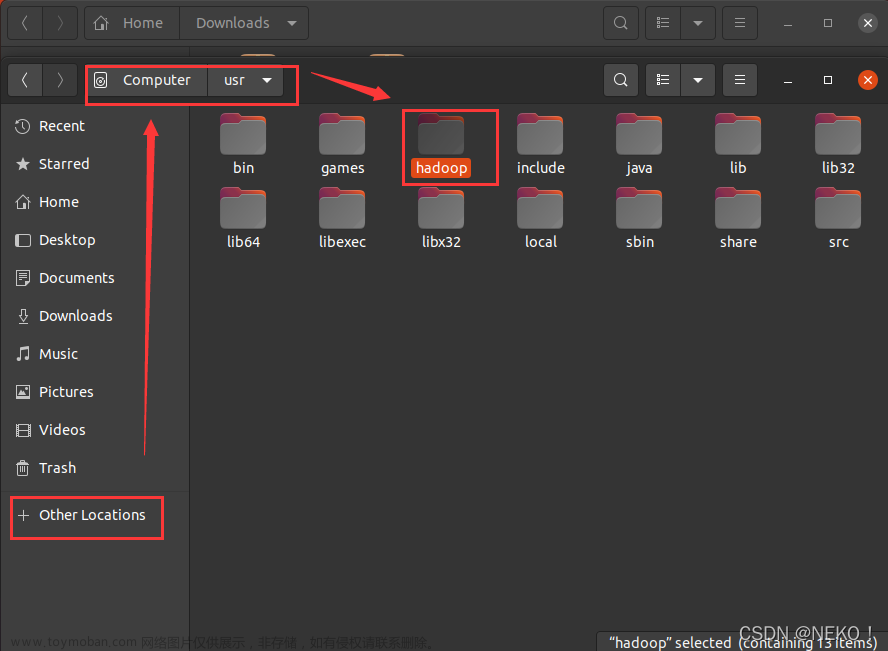
2. 配置 JDK 路径
打开文件管理器,找到 Hadoop 安装目录下的 /etc/hadoop/hadoop-env.sh 并使用文本编辑器打开(默认双击)
注意此处是 hadoop-env.sh 而不是 hadoop-env.cmd
在文件末尾添加以下代码(建议直接复制)并保存退出
export JAVA_HOME=/usr/java

3. 配置 Hadoop
在刚刚的目录下找到 core-site.xml 文件,用文本编辑器打开
在 <configuration> 标签中添加下面的配置,保存并退出
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/hadoop/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>

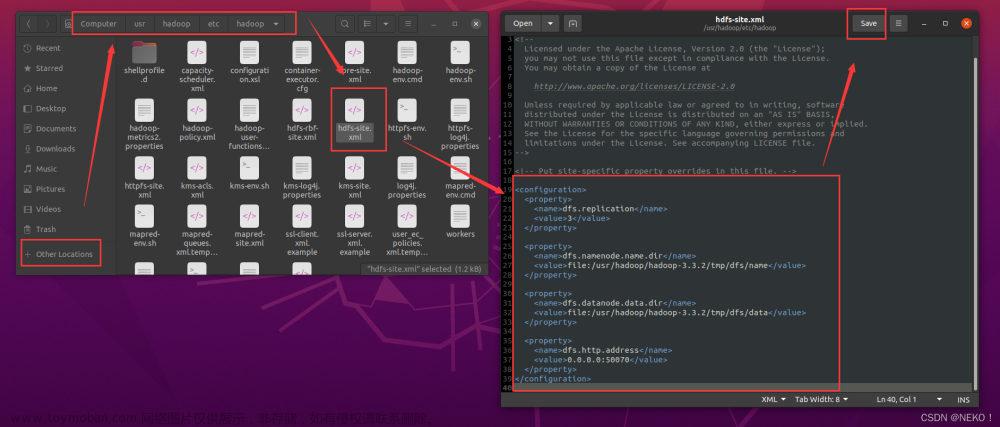
继续在文件夹中找到 hdfs-site.xml 文件,用文本编辑器打开
在 <configuration> 标签中添加下面的配置,保存并退出
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
4. 启动
打开任意终端,进入 /hadoop/bin 路径 cd /usr/hadoop/bin
执行指令 ./hdfs namenode -format 进行格式化
进入 /hadoop/sbin 路径 cd /usr/hadoop/sbin
执行指令 ./start-all.sh 启动 hadoop
执行指令 jps 查看运行的进程
打开浏览器输入 http://localhost:50070 进入 web 管理页面
至此 Hadoop 配置完成
四、附录
1. ssh 免密登陆设置
安装 openssh 服务 sudo apt-get install openssh-server
使用管理员密码验证,询问是否继续时输入 y
登陆主机 ssh localhost
询问是否继续时输入 yes 然后输入管理员密码进行登录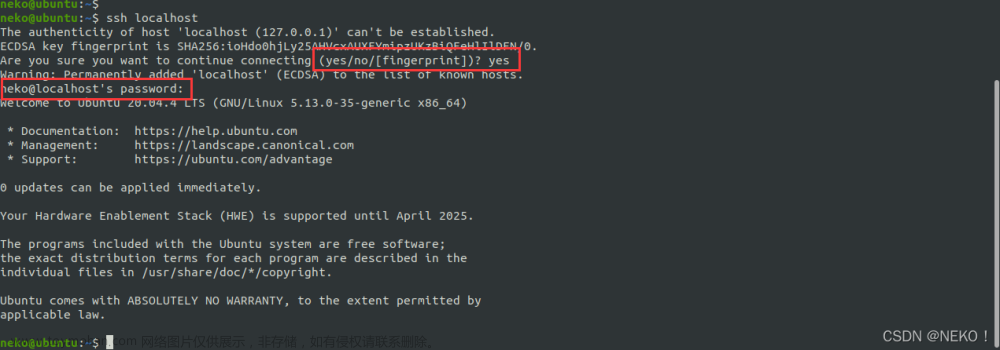
退出主机 exit
打开文件管理器,在 Home 中找到 .ssh 文件夹,进入
这个文件夹默认是隐藏的,但前面我们开启了显示隐藏文件 进入 .ssh 文件夹后右键,选择在终端打开
进入 .ssh 文件夹后右键,选择在终端打开
在终端输入指令 ssh-keygen -t rsa 创建公钥与私钥
过程中需要按几次回车,直到创建完毕
我们创建的公私钥文件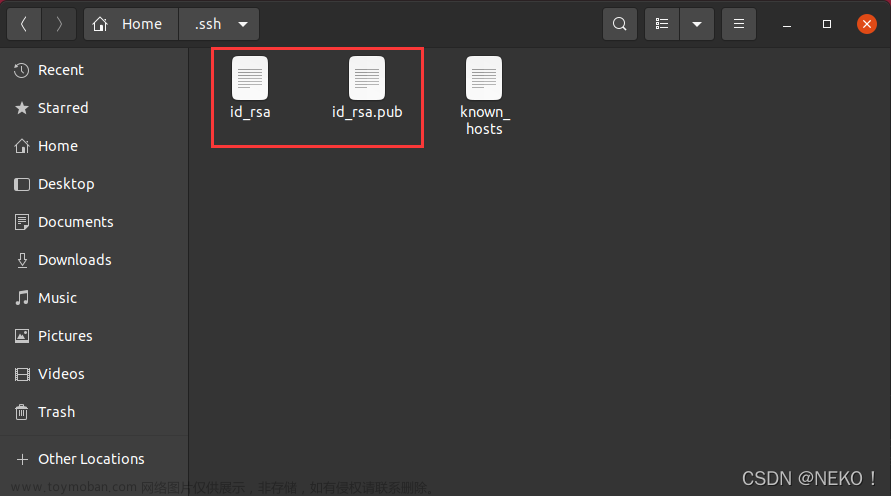
继续在终端输入 cat ./id_rsa.pub >> ./authorized_keys 进行免秘钥登陆授权
此时设置完成,再使用 ssh localhost 登陆主机已经不需要密码了
将私钥文件复制并注册到另一台计算机,可以实现远程访问
2. VS Code 安装与使用
不要直接在应用商店下载 VSCode,因为会出现无法输入中文的问题
官方下载地址:https://code.visualstudio.com/Download
下载 .deb 安装包直接运行安装文章来源:https://www.toymoban.com/news/detail-730683.html
安装中文扩展
在扩展商店搜索 Chinese 找到第一个扩展点击 Install 安装,完成后在右下角弹窗中点击 Change Language and Restart
重启后即可应用中文界面
安装 Java 扩展
在 扩展商店搜索 java 选择 Extension Pack for Java 安装后即可秒变 IDE 开始创建 java 项目

创建完成的示例可直接运行,按 F5 文章来源地址https://www.toymoban.com/news/detail-730683.html
文章来源地址https://www.toymoban.com/news/detail-730683.html
到了这里,关于Ubuntu 20.0.4 Hadoop3.3.2 安装与配置全流程保姆教程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!